
Motivación
El WS2812 es un led RGB con interface digital mediante tren de pulsos modulado en anchura (PWM) a través de una única línea serie asíncrona. Cada led acepta 24 bits, cuando el tren de pulsos PWM supera esa cantidad de bits, el led envía los bits sobrantes a través de otro de sus pines, de esta forma pueden encadenarse tantos leds RGB en serie como se quiera. Aquí puede descargarse la hoja de datos del fabricante.
El tren de pulsos debe tener unos tiempos muy específicos.
- Para mandar un 0 hay que poner la entrada a nivel alto durante 350 ns y luego a nivel bajo durante 800 ns.
- Para mandar un 1 hay que poner la entrada a nivel alto durante 700 ns y luego a nivel bajo durante 600 ns.
Con estos tiempos, con un microcontrolador de gama media o baja, si no tenemos una salida específica que soporte este protocolo hay que recurrir a trucos:
- Bitbanging: Lo bueno es que funciona en cualquier micro que tenga GPIO (todo tienen pines GPIO), lo malo es que los tiempos que hay que manejar obligan a inhibir las interrupciones y dejar de hacer el resto de tareas cada vez que el micro quiera refrescar el estado de los leds. Esta es la solución más utilizada actualmente.
- Aprovechar la interface SPI o I2S que tenga el microcontrolador para simular el tren de pulsos: Lo bueno es que es una solución menos soft que la anterior pero es una solución muy específica que debe ser programada en función de las características de cada micro y que nos obliga a prescindir de dicho interface (SPI o I2S) de la forma habitual. Por otro lado, aunque se utilicen controladores DMA internos del microcontrolador para aligerar la carga de la CPU, lo cierto es que un controlador DMA no deja de ser un máster de bus más, por lo que siempre provoca un incremento en los estados de espera de la RAM del procesador.
Solución hardware
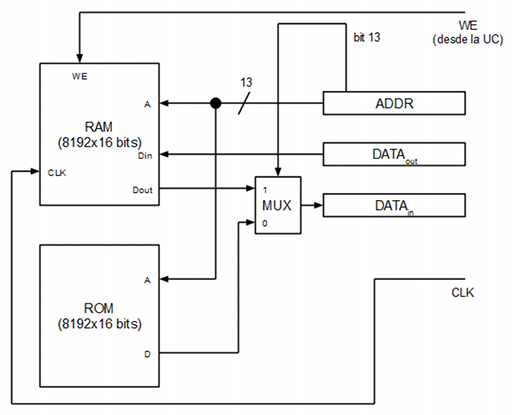
La idea es utilizar una FPGA para abstraer el acceso a los WS2812. La FPGA implementará una RAM que hará las veces de RAM de vídeo: De cara a los neopixels habrá una máquina de estados encargada de generar el tren de pulsos necesario para representar en los neopixels conectados el contenido de la RAM interna. De cara al procesador la FPGA se mostrará como una RAM con interface SPI estándar. De esta forma el procesador para iluminar un led RGB lo que hará será escribir el valor RGB en la posición correspondiente de la RAM de la FPGA. Los tres primeros bytes se corresponden con el primer pixel (formato GRB), los tres siguiente con el siguiente píxel y así sucesivamente.
Primera iteración
Como primera iteración de la solución se planteará la implementación sólo del interface con los leds RGB y que por ahora lea los datos de una ROM simulada dentro de la FPGA. La conexión SPI se dejará, por tanto, para la segunda iteración del proyecto.
Ruta de datos
La ruta de datos planteada para el interface de la FPGA con los neopixels es la siguiente:
A continuación se enumeran los elementos de forma agrupada.
La memoria ROM
Por ahora es una ROM ya que sólo se va a emitir su contenido y no será aún accesible mediante SPI.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Rom is port ( AddressIn : in std_logic_vector(12 downto 0); DataOut : out std_logic_vector(7 downto 0) ); end entity; architecture Architecture1 of Rom is type RomType is array (0 to 8191) of std_logic_vector(7 downto 0); constant Data : RomType := ( -- format = GRB "10111010", -- first pixel = green "00100110", "00001000", "00000000", -- second pixel = red "10001000", "00110011", "01000000", -- third pixel = blue "11111111", "10010110", "10000000", -- fourth pixel = yellow "10000000", "00000000", others => "00000000" ); begin DataOut <= Data(to_integer(unsigned(AddressIn))); end architecture;
Registro de desplazamiento (SR)
Se trata de un registro de desplazamiento estándar con multiplexor de carga. Cuando la entrada LOAD está a 1 el multiplexor dirige los datos de la ROM hacia la entrada del registro, mientras que cuando la entrada LOAD está a 0 el multiplexor dirige los datos del desplazador de 1 bit a la izquierda.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity ShiftReg is generic ( NBits : integer := 8 ); port ( Clk : in std_logic; Enable : in std_logic; BitOut : out std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); Load : in std_logic ); end entity; architecture Architecture1 of ShiftReg is component Reg is generic ( NBits : integer := 16 ); port ( Enable : in std_logic; Clk : in std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; signal InputMuxOut : std_logic_vector((NBits - 1) downto 0); signal DataOut : std_logic_vector((NBits - 1) downto 0); begin R : Reg generic map ( NBits => NBits ) port map ( Enable => Enable, Clk => Clk, DataIn => InputMuxOut, DataOut => DataOut ); BitOut <= DataOut(7); InputMuxOut <= DataIn when (Load = '1') else DataOut(6 downto 0) & '0'; end architecture;
Contador con un único límite (BC y ADDR)
Los contadores BC (Bit Counter) y Addr son dos instancias de un mismo contador. El contador implementado permite definir en tiempo de compilación VHDL tanto el valor de inicialización como el valor límite así como el valor de incremento (que puede ser negativo en complemento a dos). En el caso del contador ADDR el valor de inicio es 0 y el incremento es +1. El caso del contador BC es más laxo ya que no se necesita el valor de la cuenta: sólo hace falta saber si se ha llegado al final.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity FixedLimitCounter is generic ( NBits : integer := 16; LimitValue : integer := 0; ResetValue : integer := 1000; Increment : integer := -1 ); port ( Clk : in std_logic; Enable : in std_logic; Reset : in std_logic; LimitReached : out std_logic; DataOut : out std_logic_vector((NBits - 1) downto 0) ); end entity; architecture Architecture1 of FixedLimitCounter is component Reg is generic ( NBits : integer := 16 ); port ( Enable : in std_logic; Clk : in std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; component Adder is generic ( NBits : integer := 16 ); port ( A : in std_logic_vector((NBits - 1) downto 0); B : in std_logic_vector((NBits - 1) downto 0); Y : out std_logic_vector((NBits - 1) downto 0) ); end component; signal TCOut : std_logic_vector((NBits - 1) downto 0); signal AdderOut : std_logic_vector((NBits - 1) downto 0); signal InputMuxOut : std_logic_vector((NBits - 1) downto 0); signal LimitReachedPulse : std_logic; signal LimitReachedDBus : std_logic; signal LimitReachedQBus : std_logic; begin C : Reg generic map ( NBits => NBits ) port map ( Enable => Enable, Clk => Clk, DataIn => InputMuxOut, DataOut => TCOut ); A : Adder generic map ( NBits => NBits ) port map ( A => std_logic_vector(to_signed(Increment, NBits)), B => TCOut, Y => AdderOut ); InputMuxOut <= std_logic_vector(to_signed(ResetValue, NBits)) when (Reset = '1') else AdderOut; LimitReachedPulse <= '1' when (TCOut = std_logic_vector(to_signed(LimitValue, NBits))) else '0'; DataOut <= TCOut; -- LimitReached D flip-flop process (Clk) begin if (Clk'event and (Clk = '1')) then LimitReachedQBus <= LimitReachedDBus; end if; end process; LimitReachedDBus <= '0' when (Reset = '1') else (LimitReachedQBus or LimitReachedPulse); LimitReached <= LimitReachedQBus; end architecture;
Contador de límite variable (TC)
El contador TC (Time Counter) es un contador parecido al anterior. La diferencia es que el límite siempre es 0, el incremento es siempre -1 y el valor de inicialización de la cuenta es la salida de un multiplexor de 5 entradas. Este contador se utiliza para medir tiempos. En el caso de los neopixels hay que medir cinco tiempos: el valor alto para el 0 (T0H), el valor bajo para el 0 (T0L), el valor alto para el 1 (T1H), el valor bajo para el 1 (T1L) y el tiempo de pausa entre frames que, en el caso de los neopixels, debe ser de, al menos, 50 microsegundos.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Fixed5LimitsCounter is generic ( NBits : integer := 16; Limit0 : integer := 10; Limit1 : integer := 20; Limit2 : integer := 30; Limit3 : integer := 40; Limit4 : integer := 50 ); port ( Clk : in std_logic; Enable : in std_logic; Reset : in std_logic; LimitReached : out std_logic; LimitSelect : in std_logic_vector(2 downto 0) ); end entity; architecture Architecture1 of Fixed5LimitsCounter is component Reg is generic ( NBits : integer := 16 ); port ( Enable : in std_logic; Clk : in std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; component Adder is generic ( NBits : integer := 16 ); port ( A : in std_logic_vector((NBits - 1) downto 0); B : in std_logic_vector((NBits - 1) downto 0); Y : out std_logic_vector((NBits - 1) downto 0) ); end component; signal LimitMuxOut : std_logic_vector((NBits - 1) downto 0); signal TCOut : std_logic_vector((NBits - 1) downto 0); signal AdderOut : std_logic_vector((NBits - 1) downto 0); signal InputMuxOut : std_logic_vector((NBits - 1) downto 0); signal LimitReachedPulse : std_logic; signal LimitReachedDBus : std_logic; signal LimitReachedQBus : std_logic; begin TC : Reg generic map ( NBits => NBits ) port map ( Enable => Enable, Clk => Clk, DataIn => InputMuxOut, DataOut => TCOut ); A : Adder generic map ( NBits => NBits ) port map ( A => std_logic_vector(to_signed(-1, NBits)), B => TCOut, Y => AdderOut ); LimitMuxOut <= std_logic_vector(to_unsigned(Limit0, NBits)) when (LimitSelect = "000") else std_logic_vector(to_unsigned(Limit1, NBits)) when (LimitSelect = "001") else std_logic_vector(to_unsigned(Limit2, NBits)) when (LimitSelect = "010") else std_logic_vector(to_unsigned(Limit3, NBits)) when (LimitSelect = "011") else std_logic_vector(to_unsigned(Limit4, NBits)); InputMuxOut <= LimitMuxOut when (Reset = '1') else AdderOut; LimitReachedPulse <= '1' when (TCOut = std_logic_vector(to_signed(0, NBits))) else '0'; -- LimitReached D flip-flop process (Clk) begin if (Clk'event and (Clk = '1')) then LimitReachedQBus <= LimitReachedDBus; end if; end process; LimitReachedDBus <= '0' when (Reset = '1') else (LimitReachedQBus or LimitReachedPulse); LimitReached <= LimitReachedQBus; end architecture;
Máquina de estados
La máquina de estados que se ha realizado consta de 16 estados (cabe justito en 4 biestables si codificamos los estados de forma binaria estándar). Se trata de una máquina de estados de tipo Moore en la que la salida depende del estado actual y el estado siguiente depende del estado actual y de las entradas:
La implementación de una máquina de Moore en VHDL es sistemática:
library ieee; use ieee.std_logic_1164.all; entity FSM is port ( -- inputs Clk : in std_logic; Reset : in std_logic; DrawDisplay : in std_logic; TCLimitReached : in std_logic; BitCounterLimitReached : in std_logic; AddrLimitReached : in std_logic; CurrentBit : in std_logic; -- outputs AddrEnable : out std_logic; AddrReset : out std_logic; RAMEnable : out std_logic; SRLoad : out std_logic; SREnable : out std_logic; BitCounterEnable : out std_logic; BitCounterReset : out std_logic; TCLimitSelect : out std_logic_vector(2 downto 0); -- 000=t0h, 001=t0l, 010=t1h, 011=t1l, 1XX=50us TCEnable : out std_logic; TCReset : out std_logic; NeopixelOutput : out std_logic ); end entity; architecture Architecture1 of FSM is signal QBus : std_logic_vector(3 downto 0); signal DBus : std_logic_vector(3 downto 0); begin process (Clk, Reset) begin if (Clk'event and (Clk = '1')) then if (Reset = '1') then QBus <= (others => '0'); else QBus <= DBus; end if; end if; end process; -- next state logic DBus <= "0001" when ((QBus = "0000") and (DrawDisplay = '1')) else "0010" when ((QBus = "0001") or ((QBus = "1101") and (AddrLimitReached = '0'))) else "0011" when (QBus = "0010") else "0100" when ((QBus = "0011") or (QBus = "1011")) else "0101" when (QBus = "0100") else "0110" when ((QBus = "0101") or ((QBus = "0110") and (TCLimitReached = '0'))) else "0111" when ((QBus = "0110") and (TCLimitReached = '1')) else "1000" when ((QBus = "0111") or ((QBus = "1000") and (TCLimitReached = '0'))) else "1001" when ((QBus = "1000") and (TCLimitReached = '1')) else "1010" when (QBus = "1001") else "1011" when ((QBus = "1010") and (BitCounterLimitReached = '0')) else "1100" when ((QBus = "1010") and (BitCounterLimitReached = '1')) else "1101" when (QBus = "1100") else "1110" when ((QBus = "1101") and (AddrLimitReached = '1')) else "1111" when ((QBus = "1110") or ((QBus = "1111") and (TCLimitReached = '0'))) else "0000" when ((QBus = "1111") and (TCLimitReached = '1')) else "0000"; -- output logic AddrEnable <= '1' when ((QBus = "0001") or (QBus = "1100")) else '0'; AddrReset <= '1' when (QBus = "0001") else '0'; RAMEnable <= '1' when (QBus = "0010") else '0'; SRLoad <= '1' when (QBus = "0011") else '0'; SREnable <= '1' when ((QBus = "0011") or (QBus = "1011")) else '0'; BitCounterEnable <= '1' when ((QBus = "0011") or (QBus = "1001")) else '0'; BitCounterReset <= '1' when (QBus = "0011") else '0'; TCLimitSelect <= "000" when ((QBus = "0101") and (CurrentBit = '0')) else "001" when ((QBus = "0111") and (CurrentBit = '0')) else "010" when ((QBus = "0101") and (CurrentBit = '1')) else "011" when ((QBus = "0111") and (CurrentBit = '1')) else "100" when (QBus = "1110") else "000"; TCEnable <= '1' when ((QBus = "0101") or (QBus = "0110") or (QBus = "0111") or (QBus = "1000") or (QBus = "1110") or (QBus = "1111")) else '0'; TCReset <= '1' when ((QBus = "0101") or (QBus = "0111") or (QBus = "1110")) else '0'; NeopixelOutput <= '1' when (QBus = "0110") else '0'; end architecture;
Como se puede observar hay una señal de entrada adicional que no se encuentra reflejada en la ruta de datos: DRAW. La máquina de estados, al arrancar se pone en el estado 0 (el estado de reset) y permanece en ese estado hasta que la entrada DRAW se ponga a 1, en ese momento es cuando se desencadena todo el proceso (le lee la ROM y se manda bit a bit usando el PWM específico de los neopixels). Cuando terminan de mandarse todos los bytes, la máquina de estados espera el tiempo de pausa (mínimo 50 microsegundo) y vuelve al estado 0. Estado en el que se queda a menos que desde fuera se le vuelva a indicar que dibuje de nuevo (DRAW=1).
Nótese también que la máquina de estados está pensada para interactuar con una RAM ya que el estado 2 pone a 1 la línea ENABLE de la RAM. Esta línea no se encuentra en esta implementación conectada a nada (la ROM no tiene ENABLE, es estática). Se ha dejado ya que en su momento, cuando se utilice una RAM sí que será necesario.
Ajuste de los tiempos
Los tiempos de nivel alto y nivel bajo en función del bit que se envía son críticos en el caso del WS2812. Como se puede ver en el grafo de la máquina de estados el tiempo que está a nivel alto la salida depende exclusivamente del tiempo que permanece la máquina de estados en el estado 6. Dicho tiempo viene determinado por los tiempos T0H y T1H (en función del bit que se esté mandando). El problema viene con el tiempo que debe estar la salida a nivel bajo (T0L y T1L):
- Cuando estamos dentro de los 8 bits del registro de desplazamiento y no es necesario realizar una carga en memoria, además del estado 8 en el que se espera el tiempo T0L o T1L, la máquina de estados pasa por otros estados: 7, 9, 10, 11, 4 y 5 (6 estados adicionales).
- Cuando es necesario cargar el siguiente byte de la memoria en el registro de desplazamiento la cantidad de estados por los que pasa la máquina teniendo la salida a nivel bajo (tiempos T0L y T1L) además del estado 8 son los estados: 7, 9, 10, 12, 13, 2, 3, 4 y 5 (9 estados adicionales).
Teniendo en cuenta que, a 32 MHz, cada estado consume 1 / 32000000 segundos = 31.25 nanosegundos, el desfase de tiempo entre un caso y otro no es trivial. En estos casos hay que echar mano de la tolerancia de las señales de entrada y procurar que la ruta más corta (la primera) entre dentro de la tolerancia de forma negativa para que la ruta más larga (la segunda) caiga dentro de la tolerancia de forma positiva.
Utilizando diferentes testbenchs se consiguieron ajustar los tiempos de esta manera:
T1H
teórico: 700±150 ns (550 a 850 ns)
real con inicio de cuenta en el valor 21:
718750 ps = 718.750 ns = 0.718750 us
T1L
teórico: 600±150 ns (450 a 750 ns)
real con inicio de cuenta en el valor 10:
562500 ps = 562.500 ns = 0.562500 us (ruta corta)
656250 ps = 656.250 ns = 0.656250 us (ruta larga)
T0H
teórico: 350±150 ns (200 a 500 ns)
real con inicio de cuenta en el valor 9:
343750 ps = 343.750 ns = 0.343750 us
T0L
teórico: 800±150 ns (650 a 950 ns)
real con inicio de cuenta en el valor 16:
750000 ps = 750.000 ns = 0.750000 us (ruta corta)
843750 ps = 843.750 ns = 0.843750 us (ruta larga)
Estos valores se obtuvieron implementando un reloj a 32 MHz en el testbench (la misma frecuencia del reloj de la placa FPGA Papilio One) y midiendo los tramos correspondientes sobre la simulación.
Implementación física
La implementación física fue la parte más sencilla en este caso. Se asigna la entrada de reloj, se configura la salida para los neopixels y la entrada de reset para la máquina de estados.
El circuito funcionó a la primera :-).
Siguiente entrega
En la siguiente entrega se implementará la parte de interface con el procesador mediante protocolo SPI, simulando una RAM SPI externa.
Todo el código fuente puede descargarse de la sección soft.
[ añadir comentario ] ( 3073 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |


 ( 3 / 4381 )
( 3 / 4381 )En la anterior entrega de la serie se llegó hasta la fase de simulación y se comprobó, usando el software GHDL, el funcionamiento del procesador V1. En esta tercera entrega se ha implementado y probado el diseño en una FPGA real: una Spartan-3E de Xilinx.
>>> Enlace a la segunda entrega de la serie.
Cuando se va a implementar un diseño VHDL sobre un dispositivo real siempre nos podemos topar con problemas o limitaciones inherentes al hardware: por eso el paso final debería ser siempre el sintetizado del código sobre una FPGA. En este caso se optó por el sintetizado sobre una FPGA Spartan-3E de Xilinx, en concreto la que viene incluida en la placa de desarrollo Papilio One.
El problema de la memoria
Todas las FPGAs que hay en el mercado incluyen zonas de su sustrato especialmente diseñadas para implementar memorias RAM y/o ROM. Lo ideal, por lo tanto es que el código VHDL que implemente la ROM y la RAM sea fácilmente detectable o inferible, para que el entorno de desarrollo del fabricante utilice estos recursos de forma eficiente y que lo que queremos que sea una RAM se implemente realmente como una RAM y que lo que queremos que sea una ROM se implemente realmente como una ROM.
En el caso del código original que se hizo en la segunda entrega de la serie, a la hora de sintetizar para la FPGA de Xilinx, el entorno de desarrollo ISE detecta y sintetiza la ROM como una ROM pero no es capaz de inferir el código VHDL de la RAM como una RAM: de hecho para la RAM de 8192 palabras de 16 bits sintetiza ¡131072 biestables!
Si nos fijamos en el código VHDL de la RAM de la anterior entrega se puede observar cómo se integró la salida de proposito general (un puerto de salida que se denominó GPOut) como salida adicional en la RAM. Para facilitar que el entorno de Xilinx detectase este módulo como una RAM real se pasó la lógica de este puerto GPOut de la RAM al módulo de mas alto nivel Memory.vhd. Así mismo se incluyó una entrada Enable en el módulo RAM acorde con los estándares de diseño recomendados por los fabricantes. Esta entrada se deja permanentemente a 1 pero facilita al entorno de desarrollo la detección del codigo y su posterior sintetizado como una RAM real.
Ahora Ram.vhd es una implementacion más estándar de lo que es una RAM (sin puertos de salida y con una entrada "Enable"):
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Ram is port ( AddressIn : in std_logic_vector(12 downto 0); DataOut : out std_logic_vector(15 downto 0); DataIn : in std_logic_vector(15 downto 0); WriteEnable : in std_logic; Enable : in std_logic; Clk : in std_logic ); end entity; architecture Architecture1 of Ram is type RamType is array(0 to 8191) of std_logic_vector(15 downto 0); signal Data : RamType; begin process (Clk) begin if ((Clk'event) and (Clk = '1')) then if (Enable = '1') then if (WriteEnable = '1') then Data(to_integer(unsigned(AddressIn))) <= DataIn; end if; DataOut <= Data(to_integer(unsigned(AddressIn))); end if; end if; end process; end architecture;
Y la lógica relacionada con el puerto de salida GPOut se ha trasladado a Memory.vhd:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Memory is generic ( GPOutAddress : integer := 12288 ); port ( AddressIn : in std_logic_vector(15 downto 0); DataIn : in std_logic_vector(15 downto 0); DataOut : out std_logic_vector(15 downto 0); WriteEnable : in std_logic; GPOut : out std_logic_vector(15 downto 0); Clk : in std_logic ); end entity; architecture Architecture1 of Memory is component Rom is port ( AddressIn : in std_logic_vector(12 downto 0); DataOut : out std_logic_vector(15 downto 0) ); end component; component Ram is port ( AddressIn : in std_logic_vector(12 downto 0); DataOut : out std_logic_vector(15 downto 0); DataIn : in std_logic_vector(15 downto 0); WriteEnable : in std_logic; Enable : in std_logic; Clk : in std_logic ); end component; signal RomOut : std_logic_vector(15 downto 0); signal RamOut : std_logic_vector(15 downto 0); signal GPOutD : std_logic_vector(15 downto 0); signal GPOutQ : std_logic_vector(15 downto 0); begin -- GPOut register process (Clk) begin if ((Clk'event) and (Clk = '1')) then GPOutQ <= GPOutD; end if; end process; GPOutD <= DataIn when (to_integer(unsigned(AddressIn)) = GPOutAddress) else GPOutQ; GPOut <= GPOutQ; -- ROM Rom1 : Rom port map ( -- 8192 words (16 bit) AddressIn => AddressIn(12 downto 0), DataOut => RomOut ); -- RAM Ram1 : Ram port map ( -- 8192 words (16 bit) AddressIn => AddressIn(12 downto 0), DataOut => RamOut, WriteEnable => WriteEnable, Enable => '1', DataIn => DataIn, Clk => Clk ); -- RAM vs ROM multiplexer DataOut <= RomOut when (AddressIn(13) = '0') else -- bit 13 = 0 --> ROM, bit 13 = 1 --> RAM RamOut; end architecture;
Con estas pequeñas modificaciones el entorno de desarrollo ISE de Xilinx sí infiere correctamente la RAM a partir del código VHDL y la implementa como una RAM real dentro de la FPGA.
Estados de espera para la memoria
Introducir este modelo de memoria RAM síncrono tanto para la lectura como para la escritura de datos obliga a introducir un estado de espera antes de cada estado que habilite el registro DATAin en la unidad de control. En concreto es necesario introducir el estado de espera en tres sitios de la máquina de estados: en la secuencia le lectura de instrucciones, en el microcódigo de la instrucción POP y en el microcódigo de la instrucción LOAD.
Para la lectura de instrucciones la secuencia de microcódigo quedaría como sigue:
0. MUX6 := "0", Habilitar PC (El vector de reset es el 0)
1. MUX1 = PC, Habilitar ADDR (Se carga IR con la instrucción apuntada por PC)
2. Estado de espera para la lectura de la memoria
3. Habilitar DATAin
4. Habilitar IR
5. MUX5 := FSM, ALU := inc, MUX4 := PC, Habilitar PC (Se hace PC := PC + 1)
6. EJECUTAR EL MICROCÓDIGO DE LA INSTRUCCIÓN ALMACENADA EN IR
7. Ir al estado 1
El microcódigo de la instrucción POP quedaría así:
POP
MUX1 := SP, Habilitar ADDR
Estado de espera
Habilitar DATAin
Habilitar RA, MUX2 := DATAin
MUX4 := SP, MUX5 := FSM, ALU := dec, Habilitar SP
Mientras que el microcódigo de la instrucción LOAD sería el siguiente:
LOAD
MUX1 := RB, Habilitar ADDR
Estado de espera
Habilitar DATAin
MUX2 := DATAin, Habilitar RA
Estos tres nuevos estados de espera se introducen como nuevos estados en la FSM de la unidad de control.
Blinker
Para probar el procesador se inicializa la ROM (el fichero Rom.vhd) con el código máquina asociado al siguiente código ensamblador V1. El programa simplemente cambia de forma alternativa los bits del puerto GPOut (0x0000, 0xFFFF, 0x0000, 0xFFFF, 0x0000, etc.).
# [12288] <-- 0 loadi 12288 op rb, ra, assign loadi 0 store loop: # RA <-- [12288] loadi 12288 op rb, ra, assign load # RA <-- NOT RA op ra, ra, not # [12288] <-- RA store # wait loop loadi 100 op rb, ra, assign waitLoop1: op ra, rb, assign jz waitLoop1End loadi 8192 waitLoop2: jz waitLoop2End op ra, ra, dec j waitLoop2 waitLoop2End: op rb, rb, dec j waitLoop1 waitLoop1End: # end of wait loop j loop
Se trata de un bucle infinito en el que en cada iteración se cambia de estado el puerto GPOut (alternativamente 0x0000 y 0xFFFF) y que, entre iteración e iteración, incluye dos bucles anidados que provocan un retardo significativo y visible entre cada cambio de estado.
El V1 tiene dos entradas de un bit cada una (Clk y Reset) y una salida de 16 bits (GPOut). La entrada de reloj (Clk) se encuentra conectada internamente en la placa Papilio One a un oscilador de cristal de 32MHz, la entrada Reset se mapea al pin A0 de la placa y la salida GPOut se mapea a los pines B0 a B15 (16 bits). Para comprobar que el blinker funciona basta con conectar un led a cualquiera de los pines B0 a B15.
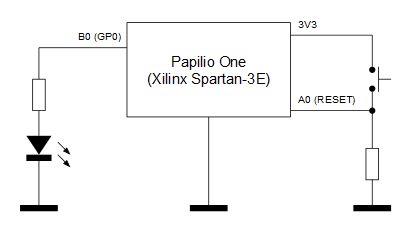
Resultado
Como se puede ver en el siguiente vídeo, nuestro procesador V1 implementado en la FPGA ejecuta perfectamente el código de la ROM.
En la sección soft puede descargarse todo el código VHDL del proyecto.
[ añadir comentario ] ( 2987 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4316 )En esta segunda entrega de la serie se profundiza en el diseño de la unidad de control, en la implementación en VHDL de los diferentes elementos y en la realización de una prueba de concepto sobre un simulador.
>>> Enlace a la primera entrega de la serie.
Lógica combinatoria: los multiplexores
Un multiplexor es un circuito combinacional con varias entradas y una salida que permite, mediante una entrada adicional de selección, decidir qué entrada se enruta a la salida.
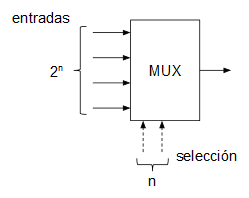
El código VHDL para un multiplexor de, por ejemplo, 3 entradas sería el siguiente:
library ieee; use ieee.std_logic_1164.all; entity Mux3Inputs is generic ( NBits : integer := 16 ); port ( Sel : in std_logic_vector(1 downto 0); DataIn0 : in std_logic_vector((NBits - 1) downto 0); DataIn1 : in std_logic_vector((NBits - 1) downto 0); DataIn2 : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end entity; architecture Architecture1 of Mux3Inputs is begin DataOut <= DataIn0 when (Sel = "00") else DataIn1 when (Sel = "01") else DataIn2; end architecture;
Lógica combinatoria: el expansor del signo
El expansor del signo (EXP) es un bloque combinacional que expande el signo de un valor de M bits a N bits siendo M < N.
En nuestro caso, el expansor del signo incluye una entrada de selección de un bit para elegir entre M=12 (instrucciones de salto relativo) y M=15 (sólo para la instrucción LOADI).
library ieee; use ieee.std_logic_1164.all; entity SignExp is generic ( NBitsToExpand0 : integer := 15; NBitsToExpand1 : integer := 12; NBits : integer := 16 ); port ( SelIn : in std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end SignExp; architecture Architecture1 of SignExp is signal Expansion0 : std_logic_vector((NBits - NBitsToExpand0 - 1) downto 0); signal Expansion1 : std_logic_vector((NBits - NBitsToExpand1 - 1) downto 0); begin Expansion0 <= (others => DataIn(NBitsToExpand0 - 1)); Expansion1 <= (others => DataIn(NBitsToExpand1 - 1)); DataOut <= Expansion0 & DataIn((NBitsToExpand0 - 1) downto 0) when (SelIn = '0') else Expansion1 & DataIn((NBitsToExpand1 - 1) downto 0); end Architecture1;
Lógica combinatoria: ALU
La ALU es en este caso incluye dentro dos multiplexores, un sumador y un negador.
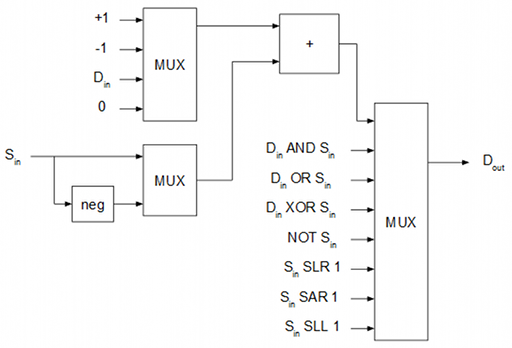
Partiendo de este diseño, la implementación en VHDL es directa.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Alu is generic ( NBits : integer := 16 ); port ( DIn : in std_logic_vector((NBits - 1) downto 0); SIn : in std_logic_vector((NBits - 1) downto 0); RAIn : in std_logic_vector((NBits - 1) downto 0); DOut : out std_logic_vector((NBits - 1) downto 0); SelIn : in std_logic_vector(3 downto 0) ); end entity; architecture Architecture1 of Alu is component Adder is generic ( NBits : integer := 16 ); port ( A : in std_logic_vector((NBits - 1) downto 0); B : in std_logic_vector((NBits - 1) downto 0); Y : out std_logic_vector((NBits - 1) downto 0) ); end component; component Neg is generic ( NBits : integer := 16 ); port( DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; signal AddOut : std_logic_vector((NBits - 1) downto 0); signal SInNeg : std_logic_vector((NBits - 1) downto 0); signal FirstOperand : std_logic_vector((NBits - 1) downto 0); signal SMuxOut : std_logic_vector((NBits - 1) downto 0); begin -- mux for the first operand of the adder FirstOperand <= std_logic_vector(to_signed(1, NBits)) when (SelIn = "0111") else -- inc std_logic_vector(to_signed(-1, NBits)) when (SelIn = "1000") else -- dec DIn when ((SelIn = "0001") or (SelIn = "0010") or (SelIn = "1100") or (SelIn = "1101")) else -- add, sub, jz, jn (others => '0'); -- assign -- neg Y Negate : Neg generic map ( NBits => NBits ) port map ( DataIn => SIn, DataOut => SInNeg ); -- src mux SMuxOut <= SInNeg when (SelIn = "0010") else -- sub (others => '0') when ((SelIn = "1100") and (RAIn /= std_logic_vector(to_unsigned(0, NBits)))) or ((SelIn = "1101") and (RaIn(NBits - 1) = '0')) else -- jz, jn SIn; -- adder Add : Adder generic map ( NBits => NBits ) port map ( A => FirstOperand, B => SMuxOut, Y => AddOut ); -- final mux DOut <= AddOut when ((SelIn = "0000") or (SelIn = "0001") or (SelIn = "0010") or (SelIn = "0111") or (SelIn = "1000") or (SelIn = "1100") or (SelIn = "1101")) else (DIn and SIn) when (SelIn = "0011") else (DIn or SIn) when (SelIn = "0100") else (DIn xor SIn) when (SelIn = "0101") else (not(SIn)) when (SelIn = "0110") else ('0' & SIn(15 downto 1)) when (SelIn = "1001") else -- slr (SIn(15) & SIn(15 downto 1)) when (SelIn = "1010") else -- sar (SIn(14 downto 0) & '0') when (SelIn = "1011") else -- sll (others => '0'); end architecture;
Nótese que el componente Neg es el negador y calcula el complemento a dos (también se trata, a su vez, de un circuito combinacional)
Lógica secuencial: los registros
Un registro no es más que una colección de biestables D en paralelo, uno por cada bit.
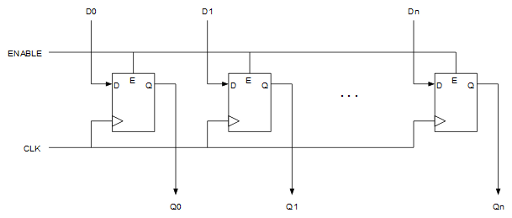
La forma más portable de implementar una entrada enable es poniendo un multiplexor en la entrada D que seleccione entre la entrada exterior y realimentar la propia Q. De esta forma simulamos un enable con lógica estándar.
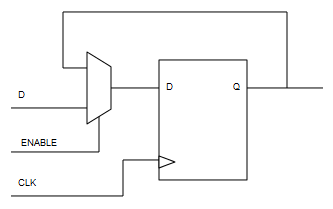
La implementación en VHDL de biestables D es directa:
library ieee; use ieee.std_logic_1164.all; entity Reg is generic ( NBits : integer := 16 ); port ( Enable : in std_logic; Clk : in std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end Reg; architecture Architecture1 of Reg is signal QBus : std_logic_vector((NBits - 1) downto 0); signal DBus : std_logic_vector((NBits - 1) downto 0); signal PreDBus : std_logic_vector((NBits - 1) downto 0); begin process (Clk) begin if (Clk'event and (Clk = '1')) then QBus <= DBus; end if; end process; DBus <= PreDBus when (Enable = '1') else QBus; PreDBus <= DataIn; DataOut <= QBus; end Architecture1;
Lógica secuencial: la memoria
La unidad de memoria viene con una RAM y una ROM. Una memoria ROM no requiere secuencialidad y puede ser implementada como una LUT de forma combinatoria:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Rom is port ( AddressIn : in std_logic_vector(12 downto 0); DataOut : out std_logic_vector(15 downto 0) ); end entity; architecture Architecture1 of Rom is type RomType is array (0 to 8191) of std_logic_vector(15 downto 0); constant Data : RomType := ( "0001000000000000", -- load "0010000000001000", -- op ra, ra, dec "0011000000000000", -- store others => "0000000000000000" ); begin DataOut <= Data(to_integer(unsigned(AddressIn))); end architecture;
La memoria RAM sí requiere de la señal de reloj ya que es un circuito secuencial. La implementación VHDL usada es la recomendada por la mayoría de los fabricantes (usando un array de std_logic_vector):
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Ram is generic ( GPOutAddress : integer := 4096 ); port ( AddressIn : in std_logic_vector(12 downto 0); DataOut : out std_logic_vector(15 downto 0); DataIn : in std_logic_vector(15 downto 0); WriteEnable : in std_logic; GPOut : out std_logic_vector(15 downto 0); Clk : in std_logic ); end entity; architecture Architecture1 of Ram is type RamType is array(0 to 8191) of std_logic_vector(15 downto 0); signal Data : RamType; begin process (Clk) begin if ((Clk'event) and (Clk = '1')) then if (WriteEnable = '1') then Data(to_integer(unsigned(AddressIn))) <= DataIn; end if; end if; end process; DataOut <= Data(to_integer(unsigned(AddressIn))); GPOut <= Data(GPOutAddress); end architecture;
La RAM incluye un puerto GPOut que mapea la dirección de memoria 4096 de la RAM en un puerto de salida de 16 bits. Este añadido se usará más adelante, en la prueba de concepto, para facilitar la depuración del procesador.
La unidad de control
Como se vio en la primera entrega, la unidad de control es realmente una FSM (máquina de estados finita) cuyas salidas gobiernan las entradas enable de los registros, las entradas de selección de los multiplexores y el resto de la lógica del procesador.
La FSM de la unidad de control va avanzando el contador de programa, carga las instrucciones en el IR y ejecuta el microcódigo de cada instrucción. Los estados de la FSM comunes a cualquier instrucción que se ejecute son los siguientes (extraído del anterior post):
0. MUX6 := "0", Habilitar PC
1. MUX1 = PC, Habilitar ADDR
2. Habilitar DATAin
3. Habilitar IR
4. MUX5 := FSM, ALU := inc, MUX4 := PC, Habilitar PC
5. EJECUTAR EL MICROCÓDIGO DE LA INSTRUCCIÓN ALMACENADA EN IR
6. Ir al estado 1
A continuación puede verse el grafo completo de la FSM.
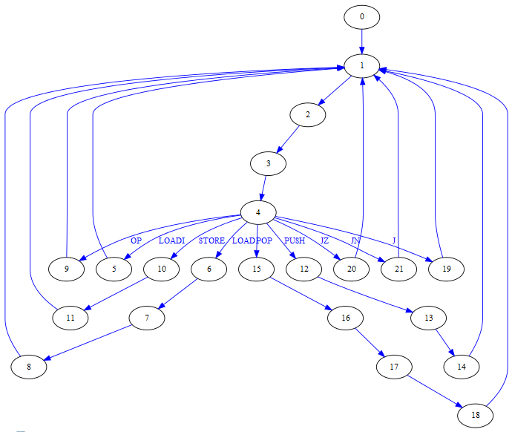
El estado 0 es al estado que se va en el reset. A continuación pueden verse también las señales que unen la unidad de control con el resto de la lógica del procesador:

Se ha optado por implementar la FSM como una máquina de tipo Moore (la salida depende sólo del estado actual y el estado siguiente depende de las entradas y del estado actual)
library ieee; use ieee.std_logic_1164.all; entity FSM is port ( DataOutEnable : out std_logic; DataInEnable : out std_logic; RAEnable : out std_logic; RBEnable : out std_logic; RCEnable : out std_logic; SPEnable : out std_logic; PCEnable : out std_logic; AddrEnable : out std_logic; IREnable : out std_logic; Mux1Sel : out std_logic_vector(1 downto 0); Mux2Sel : out std_logic_vector(1 downto 0); Mux3Sel : out std_logic_vector(2 downto 0); Mux4Sel : out std_logic_vector(2 downto 0); Mux5Sel : out std_logic; Mux6Sel : out std_logic; AluOpSel : out std_logic_vector(3 downto 0); MemWriteEnable : out std_logic; SignExpSel : out std_logic; IRValue : in std_logic_vector(15 downto 0); Clk : in std_logic; Reset : in std_logic ); end entity; architecture Architecture1 of FSM is signal QBus : std_logic_vector(4 downto 0); signal DBus : std_logic_vector(4 downto 0); begin process (Clk, Reset) begin if (Clk'event and (Clk = '1')) then if (Reset = '1') then QBus <= (others => '0'); else QBus <= DBus; end if; end if; end process; -- next state logic -- for state "00000" MUX6 := "0", Enable PC DBus <= "00001" when ((QBus = "00000") or (QBus = "00101") or (QBus = "01000") or (QBus = "01001") or (QBus = "01011") or (QBus = "01110") or (QBus = "10010") or (QBus = "10011") or (QBus = "10100") or (QBus = "10101")) else -- MUX1 := PC, Enable ADDR "00010" when (QBus = "00001") else -- Enable DATAIN "00011" when (QBus = "00010") else -- Enable IR "00100" when (QBus = "00011") else -- MUX5 := FSM, ALU := inc, MUX4 := PC, Enable PC -- LOADI states "00101" when ((QBus = "00100") and (IRValue(15) = '1')) else -- MUX2 := EXP, SignSel := 15 bits, Enable RA -- LOAD states "00110" when ((QBus = "00100") and (IRValue(15 downto 12) = "0001")) else -- MUX1 := RB, Enable ADDR "00111" when (QBus = "00110") else -- Enable DATAIN "01000" when (QBus = "00111") else -- MUX2 := DATAIN, Enable RA -- OP states "01001" when ((QBus = "00100") and (IRValue(15 downto 12) = "0010")) else -- MUX2 := ALU, MUX3 := dst, MUX4 := src, MUX5 := IR(3..0), Enable dst -- STORE states "01010" when ((QBus = "00100") and (IRValue(15 downto 12) = "0011")) else -- MUX1 := RB, Enable ADDR, Enable DATAOUT "01011" when (QBus = "01010") else -- WE := 1 -- PUSH states "01100" when ((QBus = "00100") and (IRValue(15 downto 12) = "0100")) else -- MUX4 := SP, MUX5 := FSM, ALU := inc, Enable SP "01101" when (QBus = "01100") else -- MUX1 := SP, Enable ADDR, Enable DATAOUT "01110" when (QBus = "01101") else -- WE := 1 -- POP states "01111" when ((QBus = "00100") and (IRValue(15 downto 12) = "0101")) else -- MUX1 := SP, Enable ADDR "10000" when (QBus = "01111") else -- Enable DATAIN "10001" when (QBus = "10000") else -- Enable RA, MUX2 := DATAIN "10010" when (QBus = "10001") else -- MUX4 := SP, MUX5 := FSM, ALU := dec, Enable SP -- J states "10011" when ((QBus = "00100") and (IRValue(15 downto 12) = "0110")) else -- MUX4 := EXP, SignSel := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add, Enable PC -- JZ states "10100" when ((QBus = "00100") and (IRValue(15 downto 12) = "0111")) else -- MUX4 := EXP, SignSel := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add if RA=0, Enable PC -- JN states "10101" when ((QBus = "00100") and (IRValue(15 downto 12) = "0000")) else -- MUX4 := EXP, SignSel := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add if RA<0, Enable PC "00000"; -- output logic DataOutEnable <= '1' when (QBus = "01010") or (QBus = "01101") else '0'; DataInEnable <= '1' when (QBus = "00010") or (QBus = "00111") or (QBus = "10000") else '0'; RAEnable <= '1' when (QBus = "00101") or (QBus = "01000") or (QBus = "10001") or ((QBus = "01001") and (IRValue(10 downto 8) = "000")) else '0'; RBEnable <= '1' when (QBus = "01001") and (IRValue(10 downto 8) = "001") else '0'; RCEnable <= '1' when (QBus = "01001") and (IRValue(10 downto 8) = "010") else '0'; SPEnable <= '1' when (QBus = "01100") or (QBus = "10010") or ((QBus = "01001") and (IRValue(10 downto 8) = "011")) else '0'; PCEnable <= '1' when (QBus = "00000") or (QBus = "00100") or (QBus = "10011") or (QBus = "10100") or (QBus = "10101") or ((QBus = "01001") and (IRValue(10 downto 8) = "100")) else '0'; AddrEnable <= '1' when (QBus = "00001") or (QBus = "00110") or (QBus = "01010") or (QBus = "01101") or (QBus = "01111") else '0'; IREnable <= '1' when (QBus = "00011") else '0'; Mux1Sel <= "00" when (QBus = "00110") or (QBus = "01010") else "01" when (QBus = "01101") or (QBus = "01111") else "10"; Mux2Sel <= "00" when (QBus = "01000") or (QBus = "10001") else "01" when (QBus = "01001") else "10"; Mux3Sel <= "100" when (QBus = "10011") or (QBus = "10100") or (QBus = "10101") else IRValue(10 downto 8); Mux4Sel <= "011" when (QBus = "01100") or (QBus = "10010") else "100" when (QBus = "00100") else "101" when (QBus = "10011") or (QBus = "10100") or (QBus = "10101") else IRValue(6 downto 4); Mux5Sel <= '0' when (QBus = "01001") else '1'; Mux6Sel <= '0' when (QBus = "00000") else '1'; AluOpSel <= "0111" when (QBus = "00100") or (QBus = "01100") else "1000" when (QBus = "10010") else "0001" when (QBus = "10011") else "1100" when (QBus = "10100") else "1101" when (QBus = "10101") else "0000"; MemWriteEnable <= '1' when (QBus = "01011") or (QBus = "01110") else '0'; SignExpSel <= '0' when (QBus = "00101") else '1'; end architecture;
Al igual que en otras ocasiones, una vez tenemos el grafo de la FSM, su implementación en VHDL es totalmente mecánica.
Prueba de concepto
Como primera aproximación se ha creado un fichero Rom.vhd que contiene, escrito a mano, el código máquina del siguiente código ensamblador:
# GPOut := 10 loadi 12288 op rb, ra, assign loadi 10 store loop: # if (GPOut == 0) then goto loopEnd loadi 12288 op rb, ra, assign load jz loopEnd # decrementar GPOut loadi 12288 op rb, ra, assign load op ra, ra, dec store # bucle j loop loopEnd: j loopEnd
Para este programa el código VHDL de la ROM quedaría como sigue:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity Rom is port ( AddressIn : in std_logic_vector(12 downto 0); DataOut : out std_logic_vector(15 downto 0) ); end entity; architecture Architecture1 of Rom is type RomType is array (0 to 8191) of std_logic_vector(15 downto 0); constant Data : RomType := ( -- simple counter "1011000000000000", -- loadi 12288 "0010000100000000", -- op rb, ra, assign "1000000000001010", -- loadi 10 "0011000000000000", -- store -- loop: "1011000000000000", -- loadi 12288 "0010000100000000", -- op rb, ra, assign "0001000000000000", -- load "0111000000000110", -- jz loopEnd (+6) "1011000000000000", -- loadi 12288 "0010000100000000", -- op rb, ra, assign "0001000000000000", -- load "0010000000001000", -- op ra, ra, dec "0011000000000000", -- store "0110111111110110", -- j loop (-10) -- loopEnd: "0110111111111111", -- j loopEnd (-1) others => "0000000000000000" ); begin DataOut <= Data(to_integer(unsigned(AddressIn))); end architecture;
El puerto de salida está en la dirección 4096 de nuestra RAM pero como la RAM está situada después de la ROM, la dirección de memoria de este puerto de salida será realmente 8192 + 4096 = 12288.
Ejecutando la simulación
El paquete de software usado para realizar la simulación es el GHDL, un compilador y simulador VHDL open source que genera ficheros VCD de eventos. Estos ficheros VCD contienen las señales digitales de todo el circuito simulado y son visualizables con herramientas como el GtkWave.
El testbench utilizado se encarga simplemente de generar el tren de pulsos del reloj y de realizar un reset al principio.
Reset <= '0' after 3 ns; Finished <= '1' after 2 us; Clk <= not Clk after 1 ns when Finished /= '1' else '0';
A continuación pueden verse las señales de nuestra CPU al ejecutar una instrucción LOADI justo después del reset:
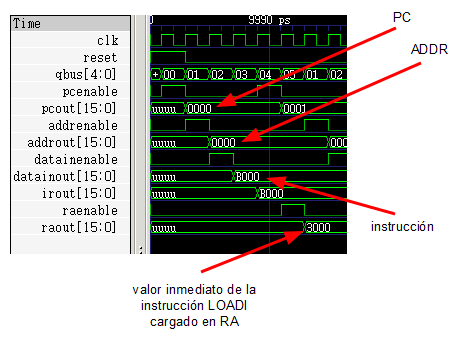
Si observamos el puerto de salida GPOut y alejamos el zoom se puede ver cómo el procesador ha ejecutado el programa correctamente (cuenta descendente desde 10 hasta 0 y se detiene).

Ya hemos conseguido que nuestro provesador V1 funcione en un simulador, ahora sólo nos queda implementarlo en una FPGA, pero eso será en la próxima entrega :-).
En la sección soft puede descargarse todo el código VHDL del proyecto.
>>> Enlace a la tercera entrega de la serie.
[ añadir comentario ] ( 3343 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4455 )Mediante este post empiezo a realizar una serie de entradas en las que iré abordando el diseño y la implementación en VHDL de un procesador RISC sencillo al que he llamado V1. La complejidad y lo extenso del tema obligan a dividir el proyecto en varios posts que iré publicando a medida que vaya alcanzando los diferentes hitos.
El objetivo final es conseguir un procesador funcional dentro de una FPGA (en mi caso, dentro de una Sparten-3E de Xilinx) y de desarrollar como mínimo un ensamblador y, si se tercia, un pequeño compilador.
Procesador RISC
Se plantea un procesador de tipo RISC de 16 bits con 5 registros (RA, RB, RC, SP y PC) y 9 instrucciones. Las características generales del procesador son las siguientes:
- 5 registros de 16 bits con signo (RA, RB, RC, SP y PC) entre los que se incluyen el puntero de pila (SP) y el contador de programa (PC).
- Memoria interna incorporada: 8192 palabras de 16 bits (16Kb) de ROM y 8192 palabras de 16 bits (16Kb) de RAM. La memoria no es accesible por bytes sino por palabras de 16 bits.
- 9 instrucciones tipo RISC (instrucciones de acceso a los datos separadas de las instrucciones de manipulación de los datos): LOADI, LOAD, STORE, OP, PUSH, POP, J, JZ y JN.
Repertorio de instrucciones
LOADI value
Carga en el registro RA el valor indicado como operando de 15 bits.
1vvv vvvv vvvv vvvv
RA := value (15 bits con expansión del signo)
LOAD
Carga en el registro RA el valor almacenado en la posición de memoria apuntada por el registro RB.
0001 xxxx xxxx xxxx
RA := [RB]
OP dst, src, ope
Realiza una operación entre registros.
0010 0ddd 0sss oooo
ddd, sss:
000 RA
001 RB
010 RC
011 SP (puntero de pila)
100 PC (contador de programa)
oooo:
0000 assign (dst := src)
0001 add (dst := dst + src)
0010 sub (dst := dst - src)
0011 and (dst := dst & src)
0100 or (dst := dst | src)
0101 xor (dst := dst ^ src)
0110 not (dst := !src)
0111 inc (dst := src + 1)
1000 dec (dst := src - 1)
1001 slr (dst := src slr 1)
1010 sar (dst := src sar 1)
1011 sll (dst := src sll 1)
1100 add if RA = 0 (dst := dst + src if RA = 0, else dst := dst) (jz)
1101 add if RA < 0 (dst := dst + src if RA < 0, else dst := dst) (jn)
STORE
Almacena en la posición de memoria apuntada por RB el valor que hay en RA.
0011 xxxx xxxx xxxx
[RB] := RA
PUSH
Empuja en la pila el valor que hay en RA.
0100 xxxx xxxx xxxx
SP := SP + 1, [SP] := RA
POP
Extrae un valor de la pila y lo pone en RA.
0101 xxxx xxxx xxxx
RA := [SP], SP := SP - 1
J value
Salto relativo incondicional a otra posición de memoria.
0110 vvvv vvvv vvvv
PC := PC + value (12 bits con expansión de signo)
JZ value
Salto relativo condicional (si RA = 0) a otra posición de memoria.
0111 vvvv vvvv vvvv
Si RA = 0 entonces PC := PC + value (12 bits con expansión de signo)
JN value
Salto relativo condicional (si RA < 0) a otra posición de memoria.
0000 vvvv vvvv vvvv
Si RA < 0 entonces PC := PC + value (12 bits con expansión de signo)
Como se puede comprobar se trata de un repertorio de instrucciones muy sencillo. En el que se ha optado por hacer una instrucción OP que abarque todas las posibles operaciones de la ALU: No es casualidad que las dos últimas operaciones de la instrucción OP sean las utilizadas internamente por las instrucciones JZ y JN. Esta simplificación facilita mucho el diseño de la unidad de control.
Se ha optado, además, por utilizar 5 registros en lugar de 4 ya que, aunque un juego de registros (RA, RB, SP, PC) de 4 es más que suficiente para obtener un procesador funcional, lo cierto es que de cara a la implementación de un compilador y el uso de marcos de pila (stack frames) se agradece poder disponer de un registro que permita localizar cómodamente los parámetros y las variables locales sin estar haciendo muchas filigranas (la función que realiza el registro BP en la arquitectura x86).
Un compilador podrá utilizar los registros RA y RB para los cálculos de propósito general y RC como puntero base para acceder a los parámetros actuales y las variables locales, sin necesidad de hacer malabarismos con el puntero de pila (SP).
Ejemplos de código
Un bucle sencillo:
# x = 10 loadi x op rb, ra, assign loadi 10 store loop: # if x = 0 goto loopEnd loadi x op rb, ra, assign load jz loopEnd # x-- loadi x op rb, ra, assign load op ra, ra, dec store # goto loop j loop loopEnd:
Una indirección:
# x[ i ] = 10 loadi i op rb, ra, assign load op rc, ra, assign loadi x op rb, ra, assign op rb, rc, add loadi 10 store
Restricciones de diseño
De cara a realizar el diseño del procesador se han seguido las siguientes directrices:
- Que el código VHDL sea totalmente síncrono y sintetizable. Utilizando siempre una arquitectura de tipo RTL para que pueda implementarse en cualquier FPGA de cualquier fabricante.
- Sin pipeline ni ningún otro tipo de paralelización u optimización hardware.
- Sin caché: Sólo RAM, ROM y registros.
Ruta de datos
La ruta de datos que se ha usado partiendo del repertorio de instrucciones es la siguiente:
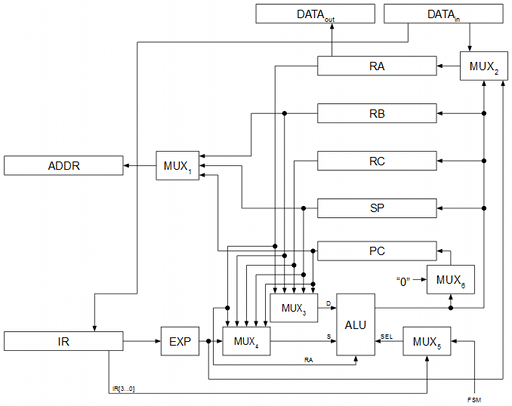
ALU
La unidad aritmético-lógica (ALU) se encarga de realizar los cálculos mediante lógica combinatoria: sumas, restas, operaciones de bit, etc.
Módulo de memoria
La memoria está compuesta por 32 Kbytes repartidos en 16 KBytes para ROM y 16 KBytes para RAM. La memoria es solo accesible a nivel de palabra de 16 bits por lo que realmente tenemos un espacio de 16384 palabras con 16 bits por palabra: 8192 palabras de ROM y 8192 palabras de RAM.
Microcódigo
Cada una de las instrucciones descritas anteriormente tendrá un microcódigo asociado que serán las órdenes de carga de los latches, las entradas de selección de los multiplexores, etc. necesarias para que cada instrucción de ejecute. A continuación se puede ver cómo es el microcódigo de cada una de las instrucciones:
LOADI value
MUX2 := EXP, EXP := 15 bits, Habilitar RA
LOAD
MUX1 := RB, Habilitar ADDR
Habilitar DATAin
MUX2 := DATAin, Habilitar RA
OP dst, src, ope
MUX2 := Alu, MUX3 := dst, MUX4 := src, MUX5 := IR[3...0], Habilitar dst
STORE
MUX1 := RB, Habilitar ADDR, Habilitar DATAout
WE := 1
PUSH
MUX4 := SP, MUX5 := FSM, ALU := inc, Habilitar SP
MUX1 := SP, Habilitar ADDR, Habilitar DATAout
WE := 1
POP
MUX1 := SP, Habilitar ADDR
Habilitar DATAin
Habilitar RA, MUX2 := DATAin
MUX4 := SP, MUX5 := FSM, ALU := dec, Habilitar SP
J value
MUX4 := EXP, EXP := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add, Habilitar PC
JZ value
MUX4 := EXP, EXP := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add if RA = 0, Habilitar PC
JN value
MUX4 := EXP, EXP := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add if RA < 0, Habilitar PC
Cada línea de microcódigo corresponde con un ciclo de reloj: LOADI requiere de un único ciclo de reloj mientras que POP requiere de cuatro ciclos de reloj. Las instrucciones PUSH y POP son las más intensivas en cuanto a ciclos de microcódigo.
Por ejemplo:
MUX4 := SP, MUX5 := FSM, ALU := inc, Habilitar SP
Significa: seleccionar la entrada correspondiente a SP en el MUX4, seleccionar la entrada correspondiente a la FSM en el MUX5 y hacer que la FSM mande la instrucción "inc" a la ALU y habilitar (poner el enable a 1) el registro SP para que sea cargado en el siguiente ciclo de reloj. Como todo está en una misma línea significa que se hace todo esto de golpe.
Hay que recordar que como estamos haciendo un modelo RTL el reloj es global a todos los bloques del procesador y la única forma que hay de controlar la carga de registros es mediante enables (Habilitar XX). Cuando se habilita un registro, es en el siguiente pulso de reloj cuando dicho registro se carga. Por ejemplo, veamos el caso de la instrucción POP:
POP
MUX1 := SP, Habilitar ADDR
Habilitar DATAin --> AQUÍ SE CARGA ADDR
Habilitar RA, MUX2 := DATAin --> AQUÍ SE CARGA DATAin
MUX4 := SP, MUX5 := FSM, ALU := dec, Habilitar SP --> AQUÍ SE CARGA RA
Veamos este microcódigo de forma más detallada y explicada:
1. En el primer ciclo de reloj se selecciona la entrada SP del MUX1 y se pone a 1 la entrada "enable" del registro ADDR.
2. En el segundo ciclo de reloj se cargará el registro ADDR con lo que estaba en la salida del MUX1 (el valor del registro SP) y se pondrá a 1 la entrada "enable" del registro DATAIN.
3. Como el registro ADDR direcciona la memoria, en la entrada del registro DATAIN estará el dato alojado en la dirección de memoria apuntada por el valor de ADDR (el valor de SP), por lo que en este ciclo de reloj en DATAIN se cargará este dato (es decir, lo que está en el tope de la pila). Se pone a 1 la entrada "enable" del registro RA y se selecciona la entrada DATAIN en el MUX2.
4. En el cuarto ciclo de reloj se carga el registro RA con el valor que sale del MUX2, que es el valor del registro DATAIN. Ya tenemos en RA el valor del tope de la pila (hemos hecho RA := [SP]). En este mismo ciclo de reloj nos preparamos para decrementar SP: Indicamos al MUX4 que seleccione la entrada SP para que la entrada S de la ALU sea el valor de SP, seleccionamos en el MUX5 la entrada de selección que llega desde la FSM, desde la FSM indicamos que queremos una operación de decremento ("dec") y ponemos a 1 la entrada "enable" del registro SP.
5. En el quinto ciclo de reloj el registro SP se carga con el valor de salida de la ALU (SP := SP - 1).
Unidad de control
La unidad de control es la parte del procesador que se encarga de la secuenciación del resto de elementos y normalmente (como este caso) se implementa en forma de FSM (máquina de estados finita). La unidad de control se encarga en nuestro caso de:
- Inicialización en el arranque del PC con el vector de reset.
- Carga de la instrucción apuntada por el PC en el IR.
- Ejecución del microcódigo de la instrucción almacenada en el IR.
- Actualización automática del PC.
Los estados que tendrá la FSM serán los siguientes (el estado 0 es el estado en el que empieza el procesador tras un reset):
0. MUX6 := "0", Habilitar PC (El vector de reset es el 0)
1. MUX1 = PC, Habilitar ADDR (Se carga IR con la instrucción apuntada por PC)
2. Habilitar DATAin
3. Habilitar IR
4. MUX5 := FSM, ALU := inc, MUX4 := PC, Habilitar PC (Se hace PC := PC + 1)
5. EJECUTAR EL MICROCÓDIGO DE LA INSTRUCCIÓN ALMACENADA EN IR
6. Ir al estado 1
En el peor caso (instrucción POP), el paso 5 necesita 4 ciclos de reloj para ejecutarse. Por tanto en el peor caso, cada instrucción necesita un total de 11 ciclos mientras que en el mejor caso (instrucciones de 1 ciclo) cada instrucción necesita un total de 7 ciclos. A 32 MHz tendremos una velocidad mínima de 2.9 MIPS y máxima de 4.6 MIPS (millones de instrucciones por segundo).
Siguiente entrega
El la siguiente entrega se abordará el diseño de la máquina de estados y se empezará a plantear la implementación de los multiplexores, la ALU y los registros en VHDL.
En la sección soft puede descargarse un simulador y un ensamblador para este procesador, desarrollados en C++.
>>> Enlace a la segunda entrega de la serie.
[ 2 comentarios ] ( 38766 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
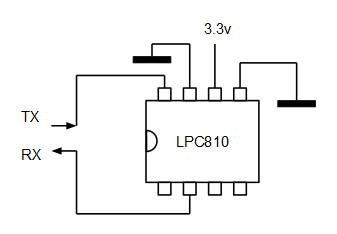
( 3 / 4332 )El LPC810 es un microcontrolador con núcleo ARM Cortex-M0+ en encapsulado DIP8 y con reloj interno. Es bastante limitado (4Kb de memoria flash y 1Kb de memoria RAM) pero el encapsulado DIP8 y el reloj interno permiten montar proyectos sencillos en protoboard, lo que le da un valor educativo muy alto. Un micro ideal para introducirse en los 32 bits cuando se viene del mundo de los 8 bits.
Características generales
El LPC810 es un ARM Cortex-M0+ en encapsulado DIP8 que incluye un multiplicador rápido de 1 ciclo, 4 Kb de memoria flash, 1 Kb de memoria RAM, un reloj interno a 12 MHz overclockeable hasta 30 MHz, bootloader por puerto serie, I2C, SPI e interface de depuración compatible JTAG. El bootloader no ocupa espacio en los 4Kb de memoria flash sino que reside una zona de memoria aparte lo que facilita mucho la programación y la configuración del linker script y del compilador.
Núcleo ARM Cortex-M0+
Todos los ARM Cortex-M mapean, tras el reset, la tabla de vectores en la posición 0x00000000 con el siguiente contenido:
dirección tamaño contenido
0x00000000 4 puntero de pila
0x00000004 4 puntero a la primera instrucción a ejecutar
...
0x0000003C 4 puntero al manejador del SysTick (timer)
...
Hay más vectores en la tabla. Sólo he indicado los más relevantes para nuestro ejemplo y por ahora nos centraremos en los dos primeros vectores (puntero de pila y vector de reset), que son los más importantes.
Bootloader
Cuando el chip LPC810 se reinicia o se enciende se ejecuta el código del bootloader. Dicho código comprueba, entre otras cosas, si el pin ISP (pin 5) del chip está a masa, si lo está, entra en modo programación (es el modo usado para tostar el integrado), en caso contrario comprueba si el código almacenado en la memoria flash es "correcto". La forma de ver si el código cargado en la memoria flash es correcto es sumando las 8 primeras palabras de 32 bits (que coincide con los 8 primeros vectores de la tabla de vectores que se vieron antes), si el resultado es 0, se considera que el código el válido y se arranca, en caso contrario se entra en modo programación (como si el pin ISP hubiese estado a masa).
El programa que se ha utilizado para tostar el LPC810 es el lpc21isp (open source) y éste ya se encarga de calcular el valor que debe tener la posición de memoria correspondiente al vector de interrupción 7 para que la suma de los 8 primeros vectores valga 0. Ni en el linker script ni en el código fuente hay que preocuparse por este valor.
Fichero de startup y linker script
En anteriores posts en los que se abordaba la programación de otro microcontrolador de la familia ARM Cortex-M (el K20 de Freescale, de la placa Teensy), utilizaba una combinación de código ensamblador y de código C para realizar la secuencia de arranque. En este caso se ha optado por abordar el código de arranque (startup) sólo en lenguaje C/C++ para facilitar la claridad. Recordemos, antes de seguir, que el formato de fichero objeto (.o) y el formato ejecutable (.elf) de salida del gcc organizan su contenido por secciones. Las secciones básicas de cualquier fichero objeto o ejecutable ELF son las siguientes:
- .text, que es la sección que incluye el código.
- .data, que es la sección que incluye las variables globales inicializadas.
- .bss, que es la sección que incluye las variables globales sin inicializar (realmente sí se inicializan, pero a cero).
La secuencia de arranque que se sigue normalmente en cualquier sistema embebido para los programas hechos con gcc la podemos resumir como sigue:
1. Se copia la parte de la flash que incluye las variables globales en RAM (sección .data de los ficheros objeto).
2. Se inicializa a cero la parte de la RAM en la que van alojadas las variables sin inicializar (sección .bss de los ficheros objeto).
3. Se recorre la lista de punteros a funciones acabada en 0 alojada en la sección .ctors. Cada entrada es una función que hay que invocar.
4. Se recorrer la lista de punteros a funciones alojada en la sección .init_array. Cada entrada es una función que hay que invocar.
5. Se invoca a la función main.
6. Al terminar main (cosa que no suele ocurrir en un microcontrolador) se recorre la lista de punteros a funciones alojada en la sección .fini_array. Cada entrada es una función que hay que invocar.
7. Por último se recorre la lista de punteros a funciones (acabada en 0) y alojada en la sección .dtors.
8. En este instante se supone que se regresa al sistema operativo, pero como somos un sistema embebido nos colgamos (while (true) ; )
Se puede observar que las secciones .ctors y .init_array sirven para lo mismo, igual que las secciones .dtors y .fini_array. Hace algunos años gcc utilizaba las secciones .ctors y .dtors pero en las ultimas versiones esta usando las secciones .init_array y .fini_array (dejando las correspondientes .ctors y .dtors vacias) por compatibilidad y homogeneidad con la librería de C de GNU (glibc).
Siguiendo los pasos descritos, podemos escribir nuestro fichero de arranque startup.cc. Dentro de este código fuente, la función void _startup() es el punto de entrada:
void _startup() __attribute__((section(".startup"), naked)); void _startup() { _initDataRAM(); _initBssRAM(); _initClock(); _callConstructors(); _callInitArray(); main(); _callFiniArray(); _callDestructors(); while (true) ; }
Como se puede apreciar la función void _startup() tiene definidos los atributos.
- section(.startup)
- naked
Los atributos son una característica exclusiva de gcc (no forman parte del estándar del lenguaje C) y permiten controlar de forma fina la generación del código por parte del compilador gcc. En este caso se le dice al compilador que el código de la función void _startup() no lo coloque en la sección estándar .text (que es, por defecto, donde va el código), sino que lo coloque en una sección aparte y que llame a dicha sección .startup. El atributo naked le indica al compilador que no genere código preámbulo ni postámbulo para la función (preparación de la pila para variables locales, etc.), en otras palabras: le estamos diciendo al compilador que se limite a generer el código del cuerpo de la función, que el resto será responsabilidad nuestra.
¿Qué sentido tienen estos atributos? El poner el código de esta función en una sección aparte llamada .startup nos permite forzar en el linker script a que el código de esta función se sitúe al principio del vector de reset, mientras que el atributo naked nos permite reducir al mínimo ese código (no necesitamos código preámbulo ni postámbulo puesto que esa función no es llamada por nadie ni termina nunca).
SECTIONS {
. = 0x00000000 ;
.cortex_m0plus_vectors : {
LONG(0x10000400);
LONG(0x000000C1);
}
. = 0x0000003C ;
.cotex_m0plus_vector_systick : {
LONG(SYSTICK_ADDRESS + 1);
}
. = 0x000000C0 ;
.text : {
_linker_code = . ;
startup.o (.startup)
*(.text)
*(.text.*)
*(.rodata*)
*(.gnu.linkonce.t*)
*(.gnu.linkonce.r*)
}
SYSTICK_ADDRESS = . ;
.systick : {
*(.systick)
}
...
}
Como se puede ver para la tabla de vectores sólo hace falta definir los dos primeros valores (puntero de pila y vector de reset). El vector de reset está fijado a 0xC1 ya que el código de startup empieza en la posición de memoria 0xC0 (justo después de la tabla de vectores en los LPC810). En la tabla de vectores se ponen las direcciones con el bit 0 a 1 ya que se trata de un ARM Cortex-M y sólo soporta el juego de instrucciones Thumb (16 bits por instrucción).
La función _startup ademas de los pasos descritos (.data, .bss, .init_array, etc.) se encarga también de configurar el reloj del sistema en el LPC810 para que vaya a la máxima frecuencia permitida. En el arranque, el LPC810 utiliza su reloj interno RC, que va a 12 MHz. Estos 12 MHz pueden aumentarse configurando la PLL hasta llegar a los 30 MHz
Inicialización de variables globales
La función void _startup() invoca a varias funciones antes y después de invocar la función main(). La función void _initDataRAM() inicializa las variables globales inicializadas (que no están a cero) copiando una parte de la memoria flash hacia la RAM:
extern "C" { extern unsigned char flash_sdata; extern unsigned char ram_sdata; extern unsigned char ram_edata; } void _initDataRAM() { // init .data section (global variables) with flash data unsigned char *from = &flash_sdata; unsigned char *to = &ram_sdata; while (to != &ram_edata) { *to = *from; from++; to++; } }
Mientras que la función void _initBssRAM() llena de ceros la zona de la memoria RAM indicada por la sección .bss (variables sin inicializar).
extern "C" { extern unsigned char ram_sbssdata; extern unsigned char ram_ebssdata; } void _initBssRAM() { // init .bss section with zeros unsigned char *p = &ram_sbssdata; while (p != &ram_ebssdata) { *p = 0; p++; } }
A continuación las funciones void _callConstructors() y void _callInitArray() son las encargadas de llevar a cabo las inicializaciones complejas, invocando una o a una cada una de las funciones incluidas en la lista correspondiente (.ctors y .init_array). Estas llamadas se encargan de hacer estas inicializaciones (por ejemplo, cuando declaramos un objeto global, es preciso llamar a su contructor antes de que se ejecute la funcion main).
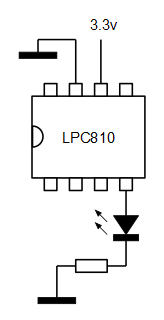
Prueba de concepto: parpadeo
Como prueba de concepto se ha desarrollado un pequeño programa muy sencillo que hace parpadear un led conectado a uno de los pines del integrado. Lo único que necesitamos es una toolchain con el target arm-none-eabi configurado (aquí los pasos para compilar una desde cero). Para controlar el parpadeo se ha usado la interrupción SysTick, esta interrupción está disponible en todos los ARM Cortex-M y consiste en un timer con un contador descendente de 24 bits que, cuando llega a 0, dispara dicha interrupción SysTick y vuelve a cargarse con el valor inicial.
1. En el linker script lpc810.ld incluimos una sección especial, que denominamos .systick y hacemos que la entrada 15 de la tabla de vectores (dirección de memoria 0x0000003C) apunte a la dirección de la memoria flash donde residirá la sección .systick.
SECTIONS {
. = 0x00000000 ;
.cortex_m0plus_vectors : {
LONG(0x10000400);
LONG(0x000000C1);
}
. = 0x0000003C ;
.cotex_m0plus_vector_systick : {
LONG(SYSTICK_ADDRESS + 1);
}
. = 0x000000C0 ;
.text : {
_linker_code = . ;
startup.o (.startup)
*(.text)
*(.text.*)
*(.rodata*)
*(.gnu.linkonce.t*)
*(.gnu.linkonce.r*)
}
SYSTICK_ADDRESS = . ;
.systick : {
*(.systick)
}
...
}
2. En el código fuente de nuestro programa definimos una función systick (aunque podemos ponerle el nombre que queramos) y mediante los atributos de GCC, le decimos al compilador que debe ir alojada en la sección .systick.
void systick() __attribute__ ((section(".systick")));
Esto hace que nuestra función systick quede alojada en la seccion .systick de la memoria de programa. El vector de interrupción 15 apuntará, por tanto, a esta función systick.
3. En el cuerpo de la función void systick() simplemente escribimos un 1 en el bit 2 del registro NOT0. Escribir un 1 hace que el bit PIN0_2 cambie de estado.
void systick() { // change PIO0_2 NOT0 = (1 << 2); }
4. En la función int main() configuramos el PIN0_2 como pin de salida GPIO, configuramos el SysTick para que utilice reloj del sistema / 2 como fuente de reloj y en el registro de cuenta metemos el valor 15000000 (el reloj del sistema va a 30 MHz, por lo que si contamos hasta 15000000 usando un reloj de 30/2 = 15 MHz, tendremos una interrupción por segundo).
// PIN0_2 is output PINENABLE0 = 0xFFFFFFBF; DIR0 = (1 << 2); // enable systick for interval = 1 second at 30 MHz SYST_RVR = 15000000ULL; SYST_CVR = 0; SYST_CSR |= 0x03; // clock source for systick is system clock / 2 = 15 MHz
5. A partir de este instante la funcion systick será invocada internamente una vez por segundo, provocando el parpadeo. Lo lógico ahora es no hacer nada, aunque hay varias formas de no hacer nada. Se puede siemplemente hacer un blucle infinito de toda la vida:
while (true) ;
Aunque en este caso lo más adecuado sería poner el procesador en algún modo de baja potencia para que esté medio dormido entre invocación e invocacion de la interrupción systick. Un término medio entre ambas aproximaciones es usar la instrucción WFI (Wait For Interrupt) que hace que parte del procesador se pare (no avanza ni siquiera el contador de programa) hasta que se dispare alguna interrupción.
while (true) { // WFI (wait for interrupt) instruction, enters low power mode asm volatile ("wfi"); }

Todo el código fuente puede descargarse de la sección soft.
[ añadir comentario ] ( 3900 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4990 ) Calendario
Calendario




