
El objetivo final es conseguir un procesador funcional dentro de una FPGA (en mi caso, dentro de una Sparten-3E de Xilinx) y de desarrollar como mínimo un ensamblador y, si se tercia, un pequeño compilador.
Procesador RISC
Se plantea un procesador de tipo RISC de 16 bits con 5 registros (RA, RB, RC, SP y PC) y 9 instrucciones. Las características generales del procesador son las siguientes:
- 5 registros de 16 bits con signo (RA, RB, RC, SP y PC) entre los que se incluyen el puntero de pila (SP) y el contador de programa (PC).
- Memoria interna incorporada: 8192 palabras de 16 bits (16Kb) de ROM y 8192 palabras de 16 bits (16Kb) de RAM. La memoria no es accesible por bytes sino por palabras de 16 bits.
- 9 instrucciones tipo RISC (instrucciones de acceso a los datos separadas de las instrucciones de manipulación de los datos): LOADI, LOAD, STORE, OP, PUSH, POP, J, JZ y JN.
Repertorio de instrucciones
LOADI value
Carga en el registro RA el valor indicado como operando de 15 bits.
1vvv vvvv vvvv vvvv
RA := value (15 bits con expansión del signo)
LOAD
Carga en el registro RA el valor almacenado en la posición de memoria apuntada por el registro RB.
0001 xxxx xxxx xxxx
RA := [RB]
OP dst, src, ope
Realiza una operación entre registros.
0010 0ddd 0sss oooo
ddd, sss:
000 RA
001 RB
010 RC
011 SP (puntero de pila)
100 PC (contador de programa)
oooo:
0000 assign (dst := src)
0001 add (dst := dst + src)
0010 sub (dst := dst - src)
0011 and (dst := dst & src)
0100 or (dst := dst | src)
0101 xor (dst := dst ^ src)
0110 not (dst := !src)
0111 inc (dst := src + 1)
1000 dec (dst := src - 1)
1001 slr (dst := src slr 1)
1010 sar (dst := src sar 1)
1011 sll (dst := src sll 1)
1100 add if RA = 0 (dst := dst + src if RA = 0, else dst := dst) (jz)
1101 add if RA < 0 (dst := dst + src if RA < 0, else dst := dst) (jn)
STORE
Almacena en la posición de memoria apuntada por RB el valor que hay en RA.
0011 xxxx xxxx xxxx
[RB] := RA
PUSH
Empuja en la pila el valor que hay en RA.
0100 xxxx xxxx xxxx
SP := SP + 1, [SP] := RA
POP
Extrae un valor de la pila y lo pone en RA.
0101 xxxx xxxx xxxx
RA := [SP], SP := SP - 1
J value
Salto relativo incondicional a otra posición de memoria.
0110 vvvv vvvv vvvv
PC := PC + value (12 bits con expansión de signo)
JZ value
Salto relativo condicional (si RA = 0) a otra posición de memoria.
0111 vvvv vvvv vvvv
Si RA = 0 entonces PC := PC + value (12 bits con expansión de signo)
JN value
Salto relativo condicional (si RA < 0) a otra posición de memoria.
0000 vvvv vvvv vvvv
Si RA < 0 entonces PC := PC + value (12 bits con expansión de signo)
Como se puede comprobar se trata de un repertorio de instrucciones muy sencillo. En el que se ha optado por hacer una instrucción OP que abarque todas las posibles operaciones de la ALU: No es casualidad que las dos últimas operaciones de la instrucción OP sean las utilizadas internamente por las instrucciones JZ y JN. Esta simplificación facilita mucho el diseño de la unidad de control.
Se ha optado, además, por utilizar 5 registros en lugar de 4 ya que, aunque un juego de registros (RA, RB, SP, PC) de 4 es más que suficiente para obtener un procesador funcional, lo cierto es que de cara a la implementación de un compilador y el uso de marcos de pila (stack frames) se agradece poder disponer de un registro que permita localizar cómodamente los parámetros y las variables locales sin estar haciendo muchas filigranas (la función que realiza el registro BP en la arquitectura x86).
Un compilador podrá utilizar los registros RA y RB para los cálculos de propósito general y RC como puntero base para acceder a los parámetros actuales y las variables locales, sin necesidad de hacer malabarismos con el puntero de pila (SP).
Ejemplos de código
Un bucle sencillo:
# x = 10 loadi x op rb, ra, assign loadi 10 store loop: # if x = 0 goto loopEnd loadi x op rb, ra, assign load jz loopEnd # x-- loadi x op rb, ra, assign load op ra, ra, dec store # goto loop j loop loopEnd:
Una indirección:
# x[ i ] = 10 loadi i op rb, ra, assign load op rc, ra, assign loadi x op rb, ra, assign op rb, rc, add loadi 10 store
Restricciones de diseño
De cara a realizar el diseño del procesador se han seguido las siguientes directrices:
- Que el código VHDL sea totalmente síncrono y sintetizable. Utilizando siempre una arquitectura de tipo RTL para que pueda implementarse en cualquier FPGA de cualquier fabricante.
- Sin pipeline ni ningún otro tipo de paralelización u optimización hardware.
- Sin caché: Sólo RAM, ROM y registros.
Ruta de datos
La ruta de datos que se ha usado partiendo del repertorio de instrucciones es la siguiente:
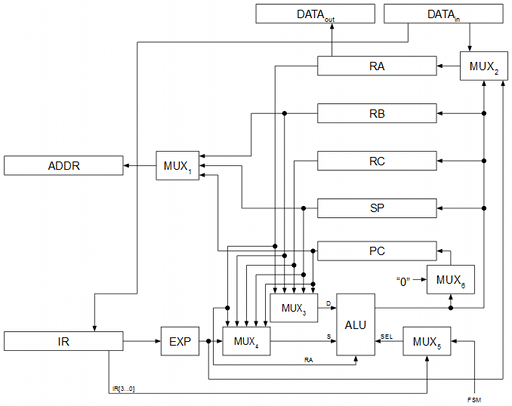
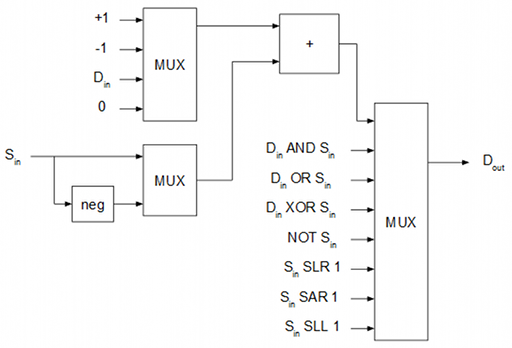
ALU
La unidad aritmético-lógica (ALU) se encarga de realizar los cálculos mediante lógica combinatoria: sumas, restas, operaciones de bit, etc.
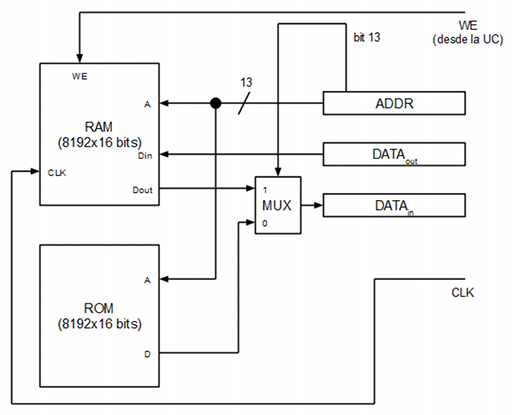
Módulo de memoria
La memoria está compuesta por 32 Kbytes repartidos en 16 KBytes para ROM y 16 KBytes para RAM. La memoria es solo accesible a nivel de palabra de 16 bits por lo que realmente tenemos un espacio de 16384 palabras con 16 bits por palabra: 8192 palabras de ROM y 8192 palabras de RAM.
Microcódigo
Cada una de las instrucciones descritas anteriormente tendrá un microcódigo asociado que serán las órdenes de carga de los latches, las entradas de selección de los multiplexores, etc. necesarias para que cada instrucción de ejecute. A continuación se puede ver cómo es el microcódigo de cada una de las instrucciones:
LOADI value
MUX2 := EXP, EXP := 15 bits, Habilitar RA
LOAD
MUX1 := RB, Habilitar ADDR
Habilitar DATAin
MUX2 := DATAin, Habilitar RA
OP dst, src, ope
MUX2 := Alu, MUX3 := dst, MUX4 := src, MUX5 := IR[3...0], Habilitar dst
STORE
MUX1 := RB, Habilitar ADDR, Habilitar DATAout
WE := 1
PUSH
MUX4 := SP, MUX5 := FSM, ALU := inc, Habilitar SP
MUX1 := SP, Habilitar ADDR, Habilitar DATAout
WE := 1
POP
MUX1 := SP, Habilitar ADDR
Habilitar DATAin
Habilitar RA, MUX2 := DATAin
MUX4 := SP, MUX5 := FSM, ALU := dec, Habilitar SP
J value
MUX4 := EXP, EXP := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add, Habilitar PC
JZ value
MUX4 := EXP, EXP := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add if RA = 0, Habilitar PC
JN value
MUX4 := EXP, EXP := 12 bits, MUX3 := PC, MUX5 := FSM, ALU := add if RA < 0, Habilitar PC
Cada línea de microcódigo corresponde con un ciclo de reloj: LOADI requiere de un único ciclo de reloj mientras que POP requiere de cuatro ciclos de reloj. Las instrucciones PUSH y POP son las más intensivas en cuanto a ciclos de microcódigo.
Por ejemplo:
MUX4 := SP, MUX5 := FSM, ALU := inc, Habilitar SP
Significa: seleccionar la entrada correspondiente a SP en el MUX4, seleccionar la entrada correspondiente a la FSM en el MUX5 y hacer que la FSM mande la instrucción "inc" a la ALU y habilitar (poner el enable a 1) el registro SP para que sea cargado en el siguiente ciclo de reloj. Como todo está en una misma línea significa que se hace todo esto de golpe.
Hay que recordar que como estamos haciendo un modelo RTL el reloj es global a todos los bloques del procesador y la única forma que hay de controlar la carga de registros es mediante enables (Habilitar XX). Cuando se habilita un registro, es en el siguiente pulso de reloj cuando dicho registro se carga. Por ejemplo, veamos el caso de la instrucción POP:
POP
MUX1 := SP, Habilitar ADDR
Habilitar DATAin --> AQUÍ SE CARGA ADDR
Habilitar RA, MUX2 := DATAin --> AQUÍ SE CARGA DATAin
MUX4 := SP, MUX5 := FSM, ALU := dec, Habilitar SP --> AQUÍ SE CARGA RA
Veamos este microcódigo de forma más detallada y explicada:
1. En el primer ciclo de reloj se selecciona la entrada SP del MUX1 y se pone a 1 la entrada "enable" del registro ADDR.
2. En el segundo ciclo de reloj se cargará el registro ADDR con lo que estaba en la salida del MUX1 (el valor del registro SP) y se pondrá a 1 la entrada "enable" del registro DATAIN.
3. Como el registro ADDR direcciona la memoria, en la entrada del registro DATAIN estará el dato alojado en la dirección de memoria apuntada por el valor de ADDR (el valor de SP), por lo que en este ciclo de reloj en DATAIN se cargará este dato (es decir, lo que está en el tope de la pila). Se pone a 1 la entrada "enable" del registro RA y se selecciona la entrada DATAIN en el MUX2.
4. En el cuarto ciclo de reloj se carga el registro RA con el valor que sale del MUX2, que es el valor del registro DATAIN. Ya tenemos en RA el valor del tope de la pila (hemos hecho RA := [SP]). En este mismo ciclo de reloj nos preparamos para decrementar SP: Indicamos al MUX4 que seleccione la entrada SP para que la entrada S de la ALU sea el valor de SP, seleccionamos en el MUX5 la entrada de selección que llega desde la FSM, desde la FSM indicamos que queremos una operación de decremento ("dec") y ponemos a 1 la entrada "enable" del registro SP.
5. En el quinto ciclo de reloj el registro SP se carga con el valor de salida de la ALU (SP := SP - 1).
Unidad de control
La unidad de control es la parte del procesador que se encarga de la secuenciación del resto de elementos y normalmente (como este caso) se implementa en forma de FSM (máquina de estados finita). La unidad de control se encarga en nuestro caso de:
- Inicialización en el arranque del PC con el vector de reset.
- Carga de la instrucción apuntada por el PC en el IR.
- Ejecución del microcódigo de la instrucción almacenada en el IR.
- Actualización automática del PC.
Los estados que tendrá la FSM serán los siguientes (el estado 0 es el estado en el que empieza el procesador tras un reset):
0. MUX6 := "0", Habilitar PC (El vector de reset es el 0)
1. MUX1 = PC, Habilitar ADDR (Se carga IR con la instrucción apuntada por PC)
2. Habilitar DATAin
3. Habilitar IR
4. MUX5 := FSM, ALU := inc, MUX4 := PC, Habilitar PC (Se hace PC := PC + 1)
5. EJECUTAR EL MICROCÓDIGO DE LA INSTRUCCIÓN ALMACENADA EN IR
6. Ir al estado 1
En el peor caso (instrucción POP), el paso 5 necesita 4 ciclos de reloj para ejecutarse. Por tanto en el peor caso, cada instrucción necesita un total de 11 ciclos mientras que en el mejor caso (instrucciones de 1 ciclo) cada instrucción necesita un total de 7 ciclos. A 32 MHz tendremos una velocidad mínima de 2.9 MIPS y máxima de 4.6 MIPS (millones de instrucciones por segundo).
Siguiente entrega
El la siguiente entrega se abordará el diseño de la máquina de estados y se empezará a plantear la implementación de los multiplexores, la ALU y los registros en VHDL.
En la sección soft puede descargarse un simulador y un ensamblador para este procesador, desarrollados en C++.
>>> Enlace a la segunda entrega de la serie.
[ 2 comentarios ] ( 38533 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |


 ( 3 / 3885 )
( 3 / 3885 ) Calendario
Calendario




