
El formato de cassette
Los cassettes fueron el soporte por antonomasia de los juegos para todos los ordenadores de los 80 (Spectrum, Amstrad, MSX, Commodore, etc.). Tardaban en cargar y eran propensos a errores pero eran baratos y el hardware necesario estaba disponible en cualquier hogar: conectabas la salida de auriculares de un reproductor de cassettes a la entrada de audio del ordenador, escribías el comando de carga en el ordenador y le dabas al "play" en el reproductor. Al cabo de unos minutos tenías el juego cargado en el ordenador.

(imagen extraída de Ebay)
A día de hoy ya no se utilizan cassettes físicos (salvo excepciones muy frikis), siendo el formato .CAS es el más extendido para almacenar datos de cassettes y existiendo multitud de utilidades para convertir dichos ficheros .CAS en ficheros .WAV de sonido listos para ser reproducidos o grabados en un cassette real y también apps para móviles que permiten reproducir ficheros .CAS a través de la salida de auriculares del móvil. Esta última aproximación será la que se usará para probar el juego desarrollado en un MSX real.
Estructura de un fichero CAS
Un fichero .CAS contiene los bytes tal cual estarían almacenados en una cinta de cassette y tienen una estructura muy sencilla y ampliamente documentada.
Cada fichero .CAS contiene, a su vez una colección de ficheros con nombre y datos, que se disponen de forma secuencial a lo largo de la cinta. Hay 3 tipos de ficheros, reconocibles por el MSX según su cabecera:
- Ficheros BASIC (accesibles con comandos CSAVE y CLOAD).
- Ficheros binarios (accesibles con comandos BSAVE y BLOAD).
- Ficheros de texto (accesibles con comandos LOAD/SAVE/OPEN).
Cuando desde el BASIC del MSX se desea ejecutar un juego en cinta, normalmente se usa el comando:
BLOAD "CAS:",R
Y a continuación se le da al "play" en el reproductor de cassette. Este comando carga en la RAM el primer fichero binario que se encuentre en la cinta de cassette y lo ejecuta (lo trata como código), por lo que, para hacer un juego cargable desde cinta de cassette, hay que crear un fichero .CAS con al menos un fichero de tipo binario dentro (que sea el primero o el único). Ese fichero binario será el que el BASIC del MSX cargará en RAM y luego ejecutará.
crt0 para crear un binario de cassette
Un fichero crt0 es un fichero, normalmente escrito en lenguaje ensamblador, encargado de describir la estructura interna de un fichero binario o ejecutable y a veces también es el encargado de realizar labores rutinarias en el arranque (puesta a cero de variables globales, por ejemplo). Esto es así en cualquier arquitectura y todos los compiladores disponen de ficheros "crt0" para todas las arquitecturas que soportan.
En este caso se utilizará el SDCC, un compilador de C con licencia GPL ampliamente utilizado para dispositivos pequeños y especializado en arquitecturas de 8 y 16 bits.
Como en otros proyectos de este blog donde se ha utilizado el SDCC, compilarlo desde Linux es muy sencillo:
$ ./configure --prefix=/ruta/de/instalacion/sdcc --disable-pic14-port --disable-pic16-port
$ make
$ make install
La cabecera de un fichero binario para que vaya dentro de un .CAS de MSX tiene 7 bytes y es la siguiente:
- 1 byte con el valor 0xFE.
- 2 bytes con la dirección de inicio del código.
- 2 bytes con la dirección final del código.
- 2 bytes con la dirección de arranque del código (donde empezará la ejecución, normalmente la misma que la dirección de inicio, pero podría ser otra).
Esta estructura es la que se traslada al fichero ensamblador del "crt0" que, en este caso, se ha llamado "crt0msx.s":
.module crt0msx
.globl _main
.globl _vblank_isr
.area _HEADER (ABS)
.org 0x81F9
.db #0xFE
.dw #0x8200
.dw end - 1
.dw #0x8200
init:
; init global variables
call gsinit
; call main function
call _main
inf_loop:
jp inf_loop
; ordering of segments for the linker.
.area _CODE
.area _HOME
.area _INITIALIZER
.area _GSINIT
.area _GSFINAL
.area _DATA
.area _INITIALIZED
.area _BSEG
.area _BSS
.area _HEAP
.area _CODE
.area _GSINIT
gsinit::
.area _GSFINAL
ret
end:
Como se puede apreciar, tanto la dirección de inicio como la dirección de arranque están puestas a fuego como 0x8200. Por eso también la cabecera se pone en 0x81F9 (exactamente 7 bytes antes). La RAM en cualquier MSX que tenga 32Kb de RAM o más (en este caso se asume eso) está disponible a partir de la dirección 0x8000 (según el mapa de la RAM del MSX) y se podría haber puesto en el crt0 la dirección de inicio como 0x8000 pero preferí dejar 512 bytes (0x200 bytes) de margen, por si BASIC tenía algún dato al principio de la RAM.
Prueba de concepto
Como prueba de concepto se hace un pequeño programa en C que escribe una cadena de caracteres usando llamadas a la BIOS y cuelga una rutina de servicio de interrupción que escribe caracteres a razón de uno cada 60 interrupciones de retrazo vertical (v-blank).
En el entorno del BASIC de MSX la zona de memoria denominada "H.TIMI" es una zona de memoria de 5 bytes entre las direcciones de memoria 0xFD9F y 0xFDA3 (ambas inclusive) que contiene código que es llamado mediante una instrucción "CALL" cada vez que se produce una interrupción de retrazo vertical (v-blank). El contenido inicial de este buffer de 5 bytes suele ser
C9 XX XX XX XX: siendo C9 el código máquina de la instrucción RET (retorno de subrutina).
Pero, al ser una zona en la RAM, podemos escribirla sin problema y colocar en ella un salto a una rutina de servicio de interrupción propia. Por ejemplo, podemos escribir:
C3 LL HH XX XX: siendo C3 el código máquina de la instrucción JP (salto incondicional) y LL y HH, respectivamente, el byte bajo y el byte alto de la dirección de memoria de nuestra rutina de servicio de interrupción a la que se quiere saltar.
De esta manera podemos colocar un "hook" o "gancho" que se ejecutará en cada interrupción de retrazo vertical y nos permitirá controlar el timing de nuestro juego (saber cuando debemos escribir en la VRAM, acceder al VPD, etc.).
#define H_TIMI_HOOK ((volatile uint8_t *) 0xFD9F) void putchar(char c) { __asm__ ( "call #0x00A2" ); } void putstr(char *s) { while (*s != 0) { putchar(*s); s++; } } volatile uint8_t counter; volatile uint8_t counter2; void vblank_isr(void) { counter++; if (counter == 60) { counter = 0; putchar((counter2 & 0x0F) + '0'); counter2++; } } void vblank_isr_set(void (*function_ptr)()) { H_TIMI_HOOK[0] = 0xC3; // JP instruction H_TIMI_HOOK[1] = (uint8_t) (((uint16_t) function_ptr) & 0x00FF); H_TIMI_HOOK[2] = (uint8_t) (((uint16_t) function_ptr) >> 8); } void main(void) { counter = 0; counter2 = 0; vblank_isr_set(vblank_isr); putstr("\r\nHola desde SDCC\r\n"); while (1) ; }
Como se puede ver, la función "vblank_isr_set" recibe por parámetros el puntero a una función y escribe en la zona de memoria "H.TIMI" los bytes necesarios para que se invoque a ese puntero cada vez que se produzca un retrazo vertical (v-blank).
Los pasos para generar el fichero .CAS serán los siguientes:
$ /ruta/al/sdcc/bin/sdasz80 -o crt0msx.rel crt0msx.s
$ /ruta/al/sdcc/bin/sdcc -mz80 --std-c23 --stack-auto -c -o main.rel main.c
$ /ruta/al/sdcc/bin/sdcc -mz80 --std-c23 --stack-auto --code-loc 0x8209 --no-std-crt0 -o main.ihx crt0msx.rel main.rel
$ objcopy -I ihex -O binary main.ihx main.bin
$ mkcas.py --name MAIN --addr 0x81F9 --exec 0x8200 main.cas binary main.bin
Nótese que en "crt0msx.s" la cabecera de 7 bytes empieza en 0x81F9 para que el código empiece en 0x8200. A partir de la dirección 0x8200 tenemos las instrucciones:
call gsinit ; 3 bytes, inicializar variables globales
call _main ; 3 bytes, llamada a la función "main"
inf_loop:
jp inf_loop ; 3 bytes, si la función "main" regresa, nos quedamos en un bucle infinito
Este código ocupa 9 bytes y, por eso le decimos al compilador en la línea de comandos que el código compilado debe alojarlo a partir de la dirección 0x8209 (opción "--code-loc").
"objcopy" es una utilidad que se puede encontrar en cualquier Linux (es una utilidad estándar para convertir ficheros binarios entre diferentes formatos) mientras que la utilidad "mkcas.py" es una utilidad desarrollada por Juan J. Martínez que está disponible en su servidor Git y que permite crear un fichero CAS a partir de una colección de ficheros para cassette (recordar que un fichero .CAS es internamente una colección de ficheros binarios, BASIC o de texto). Esta utilidad "mkcas.py" está escrita en Python y se encarga de incluir las cabeceras .CAS necesarias descritas aquí. En este caso se utiliza para construir el "main.cas" a partir del "main.bin" generado por el compilador.
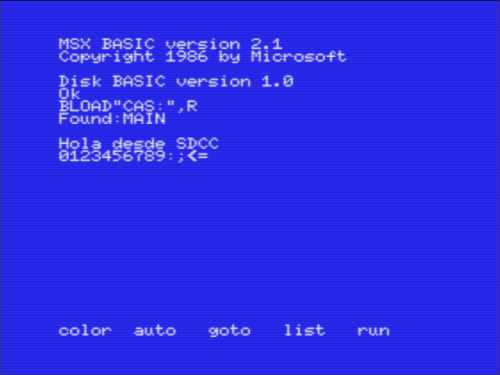
Esta captura se corresponde con la ejecución de la prueba de concepto en el emulador OpenMSX, configurado con la ROM del Philips NMS 8245 y ejecutado de la siguiente manera:
$ openmsx -machine Philips_NMS_8245 -cassetteplayer main.cas
Sudoku
Como proyecto más allá de una simple prueba de concepto, se plantea el desarrollo de un sencillo juego de tipo Sudoku con muy pocas pantallas:
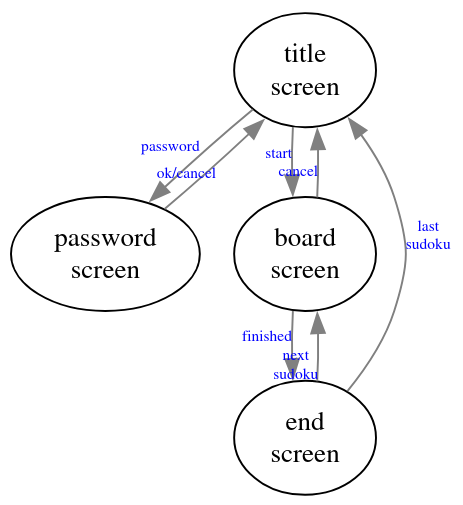
Al igual que en otros proyectos de juegos anteriores, cada pantalla tiene tres funciones asociadas (en este caso son funciones normales de C, no es C++, por lo que la orientación a objetos es simulada):
- void on_load(struct inter_screen_data_t *isd): Se invoca al entrar en la pantalla.
- struct screen_t *on_vblank(uint16_t key_mask, struct inter_screen_data_t *isd): Se invoca en cada retrazo vertical. key_mask es la máscara de teclas que están pulsadas en ese instante en el teclado.
- void on_unload(struct inter_screen_data_t *isd): Se invoca al salir de la pantalla.
Al igual que en proyectos anteriores, el bucle principal sólo invoca las funciones que corresponden en cada momento según qué pantalla esté cargada:
volatile bool vblank; void vblank_isr(void) { vblank = true; } const struct screen_t screens[] = { { title_screen_on_load, title_screen_on_vblank, title_screen_on_unload }, { password_screen_on_load, password_screen_on_vblank, password_screen_on_unload }, { board_screen_on_load, board_screen_on_vblank, board_screen_on_unload }, { end_screen_on_load, end_screen_on_vblank, end_screen_on_unload } }; int main(void) { // init vpd and VRAM . . . // init vblank isr vblank = false; vblank_isr_set(vblank_isr); // init screens volatile struct inter_screen_data_t isd; isd.level_index = 0; strcpy(isd.password, "000000"); isd.title_screen = screens; isd.password_screen = screens + 1; isd.board_screen = screens + 2; isd.end_screen = screens + 3; const struct screen_t *current_screen = screens; current_screen->on_load(&isd); uint16_t key_mask = get_key_mask(); while (1) { if (vblank) { vblank = false; const struct screen_t *next_screen = current_screen->on_vblank(key_mask, &isd); if ((next_screen != NULL) && (next_screen != current_screen)) { current_screen = next_screen; current_screen->on_load(&isd); } key_mask = get_key_mask(); } } }
El juego es un sencillo sudoku que se controla con el teclado y que por ahora sólo tiene 3 niveles (se pueden añadir más editando "levels.h" y "levels.c").
Los diferentes niveles están generados usando el proyecto Sudoku++ del desarrollador Oliver Lau. Este proyecto es un generador heurístico de sudokus: compilé el proyecto en Linux y lo ejecuté varias veces para que me generara un buen conjunto de sudokus en ficheros de texto, de los que saqué 3 para ponerlos en el fichero "levels.c".
Carga en un MSX real
En la Play Store de Android hay una utilidad llamada MSX2Cas del desarrollador brasileño Roberto Focosi Jr que permite abrir ficheros .CAS y reproducirlos a través de la salida de audio del móvil.

Los pasos son los siguientes:
- Se instala la app MSX2Cas en el móvil.
- Se pasa el fichero .CAS al móvil.
- Se deja que el MSX arranque en modo BASIC (modo por defecto).
- Se conecta la entrada de audio del MSX a la salida de auriculares del móvil (aquí puede verse el pinout del conector en el MSX para hacer el cable nosotros mismos).
- Se escribe el comando BLOAD "CAS:",R en el MSX (el BASIC se queda esperando a que entren datos por la entrada de audio).
- En la app MSX2Cas del móvil reproducimos el fichero .CAS del juego hasta que cargue y lo ejecute.
- Si la carga falla es probable que sea, o porque el volumen no es el adecuado (demasiado alto o demasiado bajo) o porque hay que invertir la señal de audio (opción disponible en la configuración de la app MSX2Cas).


Toda la información y el código fuente aquí.
[ añadir comentario ] ( 244 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |


 ( 3 / 594 )
( 3 / 594 )La PlayStation 1 fue la primera consola de 32 bits lanzada por Sony en 1994. Está basada en un procesador MIPS R3000A, dispone de 4 Mb de memoria RAM, una GPU basada en framebuffer, un coprocesador de sonido y un coprocesador para cálculo geométrico especializado en proyección 3D. A lo largo de este artículo se describirá todo el proceso para programar esta consola desde cero: desde compilar la toolchain hasta desarrollar un juego sencillo en 2D.
Breve descripción de la plataforma
La mejor fuente de información técnica sobre la PlayStation 1 es la web de Nocash. La PlayStation 1 dispone de 4 Mb de memoria RAM accesible por la CPU y de 1 Mb de memoria VRAM accesible desde la GPU (espacio de direcciones de la GPU no compartido con la CPU). El coprocesador de sonido dispone de 512 Kb de RAM para muestras y procesado de señal de audio.
Las tarjetas de memoria y los mandos se acceden mediante protocolo SPI. El procesador MIPS, al igual que el ARM, no tiene un espacio de direcciones de memoria separado del espacio de direcciones E/S, por lo que los puertos de E/S para el control de periféricos están mapeados en el espacio de direcciones fuera de los 4 Mb de RAM.
Proceso de arranque
Los discos de PlayStation 1 son CD-ROM estándar ISO 9660 con información encriptada de licencia en los primeros sectores de los mismos. Cuando la PlayStation 1 arranca, tras comprobar la licencia del disco y mostrar el logo inicial, busca un fichero de texto llamado "SYSTEM.CNF" en la carpeta raíz, que contiene, entre otros datos, la ruta dentro del CD-ROM donde está el ejecutable de arranque. En ausencia de este fichero "SYSTEM.CNF", directamente busca un fichero que se llame "PSX.EXE" en la carpeta raiz del CD-ROM y lo carga a partir de la dirección 0x80010000.
El fichero "PSX.EXE" tiene una cabecera de 2048 bytes en la que se indica la dirección de arranque, la región del juego, el valor del puntero de pila en el arranque, etc:
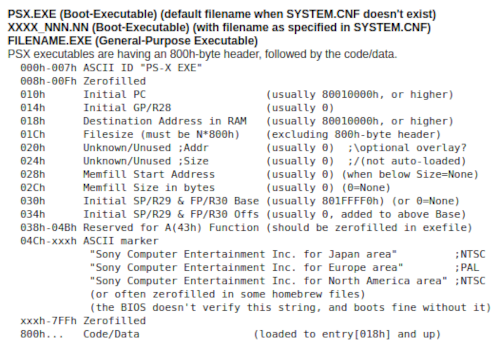
Como se puede ver, la BIOS de la PlayStation 1 carga del CD-ROM el código del fichero EXE, lo escribe a partir de la dirección 0x80010000 y luego salta a la dirección de memoria indicada por el campo PC de la cabecera (normalmente también 0x80010000, pero puede ser otra dirección dentro del espacio de 4 Mb) y es ahí donde debe estar el punto de entrada del ejecutable.
GPU
La GPU de la PlayStation 1 se encarga de manejar el frame buffer y la VRAM. La GPU no realiza transformaciones geométricas 3D, es una GPU 2D. Las transformaciones geométricas para el cálculo 3D las realiza otro coprocesador aparte: el GTE (Geometry Transformation Engine), del que no hablaré en esta entrada ya que el objetivo es hacer una prueba de concepto y un juego sencillo 2D.
La mayor particularidad de la GPU de la PlayStation 1 es que ve la VRAM (de 1 Mb) como un framebuffer de 1024x512 pixels y los comandos de GPU no hacen referencia a direcciones de memoria sino a coordenadas en el framebuffer: copiar rectángulos, mapear texturas, pintar. Esto facilita mucho el trabajo de gestión de la VRAM. Cada pixel visible (que esté dentro del área de visualización) puede abarcar 16 bits o 24 bits. Lo habitual es aplicar la técnica del swap en el framebuffer:
configurar 2 zonas en el framebuffer, con el mismo tamaño que el área de visualización
framebuffer_visualizado = el que se está mostrando ahora
framebuffer_trabajo = el que está oculto a la visualización
bucle infinito:
esperar retrazo vertical (vsync)
cambiar área visualización a framebuffer_trabajo
intercambiar en GPU framebuffer_visualizado y framebuffer_trabajo
pintar_escena(framebuffer_trabajo)
fin bucle
Si asumimos una profundidad de color de 16 bits para el área de visualización y un modo gráfico de 320x240 (relación de aspecto 4:3), podemos colocar dos framebuffers uno encima del otro, dejando el resto de la VRAM para sprites y texturas:
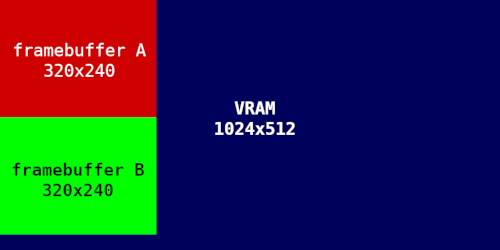
Si configuramos la GPU para que, en la ventana de visualización, cada pixel sea de 24 bits, cada frame ocupará 480 "pixels" de ancho, ya que cada 2 pixels de 24 bits equivalen a 3 pixels de 16 bits. Yo he optado por asumir siempre 16 bits por pixel para facilitar todas las operaciones gráficas.
Para inicializar la GPU en 320x240 PAL y 16 bits por pixel:
void psx::gpu_set_vertical_display_center(int16_t rel) { uint16_t y1 = 0x002B + rel; uint16_t y2 = 0x011B + rel; GP1 = 0x07000000 | ((((uint32_t) y2) << 10) & 0x000FFC00) | (((uint32_t) y1) & 0x000003FF); } void psx::gpu_init() { // reset GPU GP1 = 0x00000000; // display mode: 16 bit, 320x240, pal GP1 = 0x08000009; // horizontal display range, typical PAL values: x1 = 0x260, x2 = 0x260 + (320 *8) = 0xC60 //GP1 = 0x06C60260; GP1 = 0x06000000 | (((uint32_t) (0x270 + (320 * 8))) << 12) | ((uint32_t) 0x270); // vertical display range, typical PAL values: y1 = 0xA3 - (240 / 2) = 0xA3 - 120 = 0x2B, y2 = 0xA3 + (240 / 2) = 0xA3 + 120 = 0x11B // 00000111 0000 0100011011 0000101011 = 00000111 00000100 01101100 00101011 = 0x07046C2B // 0x11B 0x2B //GP1 = 0x07046C2B; gpu_set_vertical_display_center(0); // enable display GP1 = 0x03000000; // start of display area in VRAM (0, 0) // 00000101 00000 000000000 0000000000 // y x GP1 = 0x05000000; // start of display area in VRAM (0, 120) // 00000101 00000 001111000 0000000000 = 00000101 00000001 11100000 00000000 = 0x0501E000 // y x ////GP1 = 0x0501E000; while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; // allow drawing to display area (bit 10 = 1) GP0 = 0xE1000400; // set drawing area: top left (x1 = y1 = 0) GP0 = 0xE3000000; // set drawing area: bottom right: x2 = 1023 = 0b1111111111, y2 = 511 = 0b111111111 // 11100100 00000 000000000 0000000000 // 511 1023 // 111111111 1111111111 // 11100100 00000 111111111 1111111111 = 11100100 00000111 11111111 11111111 = 0xE407FFFF GP0 = 0xE407FFFF; // set drawing offset = 0 GP0 = 0xE5000000; // disable all interrupts I_MASK = 0; // fill entire VRAM with 0 GP0 = 0x02000000; GP0 = 0x00000000; GP0 = (((uint32_t) 512) << 16) | ((uint32_t) 1024); while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; }
Como se puede comprobar, trabajar con la GPU consiste en enviar comandos seguidos de datos a las direcciones de memoria GP0 y GP1. A continuación se puede ver el código de lo que sería el comando "monochrome rectangle":
void psx::gpu_draw_rectangle(uint16_t x, uint16_t y, uint16_t width, uint16_t height, uint32_t color) { while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; GP0 = 0x60000000 | (color & 0x00FFFFFF); GP0 = (((uint32_t) y) << 16) | ((uint32_t) x); GP0 = (((uint32_t) height) << 16) | ((uint32_t) width); }
Como se comentó al principio, la RAM de la CPU es independiente de la VRAM y para hacer transferencias entre ambas hay que usar comandos GPU acompañados de escrituras/lecturas de datos a través de un registro o mediante DMA.
void psx::gpu_copy_ram_to_vram(const uint32_t *src, uint32_t n, uint16_t dst_x, uint16_t dst_y, uint16_t dst_width, uint16_t dst_height) { while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; GP0 = 0xE6000000; // mask setting: draw always, leave bit 15 as transfered while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; GP0 = 0xA0000000; // copy rectangle CPU to VRAM GP0 = (((uint32_t) dst_y) << 16) | ((uint32_t) dst_x); // destination coords GP0 = (((uint32_t) dst_height) << 16) | ((uint32_t) dst_width); // size while (n > 0) { GP0 = *src; src++; n--; } }
Al contrario que las GPUs de las consolas predecesoras de su época, la PlayStation 1 no maneja el concepto de sprites: se dibuja directamente en el framebuffer, por lo que los sprites deben ser gestionados "a mano", copiando regiones de un sitio a otro de la VRAM (por ejemplo, el comando "textured rectangle" permite copiar rectángulos de una zona a otra de la VRAM sin escalar y asumiendo que el los pixels con el valor 0x0000 son transparentes).
void psx::gpu_draw_8x8_tile(uint8_t src_x, uint8_t src_y, uint16_t dst_x, uint16_t dst_y, uint8_t tp_x, uint8_t tp_y) { // tp_x = 0..15, tp_y = 0..1 while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; GP0 = 0xE6000000; // mask setting: draw always, leave bit 15 as transfered while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; GP0 = 0xE1000500 | (((uint32_t) tp_x) & 0x0000000F) | ((((uint32_t) tp_y) << 4) & 0x00000010); // texture page, drawing enabled, 15 bit texture while (!(GPUSTAT & (((uint32_t) 1) << 26))) ; GP0 = 0x75000000; // texture rectangle, opaque, 8x8, raw texture GP0 = (((uint32_t) dst_y) << 16) | ((uint32_t) dst_x); GP0 = (((uint32_t) src_y) << 8) | ((uint32_t) src_x); }
Como se puede ver, en todos los comandos de pintado se indican directamente coordenadas en el framebuffer, no direcciones de memoria en la VRAM.
Compilar el compilador
De la misma forma que se ha hecho para otras plataformas, compilaremos una toolchain de GNU sin sistema operativo, basada en binutils, gcc y newlib para el target "mipsel-none-elf" (aunque la arquitectura MIPS puede funcionar tanto en modo big endian como en modo little endian, en la PlayStation 1, la CPU está fijada a modo little endian y por eso el primer elemento de la terna de la toolchain debe ser "mipsel").
binutils
mkdir -p /opt/baremetalmipsel/src
cd /opt/baremetalmipsel/src
wget https://ftp.gnu.org/gnu/binutils/binutils-2.46.0.tar.xz
tar xf binutils-2.46.0.tar.xz
mkdir -p /opt/baremetalmipsel/build/binutils-2.46.0
cd /opt/baremetalmipsel/build/binutils-2.46.0
../../src/binutils-2.46.0/configure --prefix=/opt/baremetalmipsel --target=mipsel-none-elf --disable-nls
make
make install
gcc (fase 1)
cd /opt/baremetalmipsel/src
wget https://ftp.gnu.org/gnu/gcc/gcc-15.1.0/gcc-15.2.0.tar.xz
wget https://ftp.gnu.org/gnu/gmp/gmp-6.3.0.tar.xz
wget https://ftp.gnu.org/gnu/mpc/mpc-1.4.1.tar.gz
wget https://ftp.gnu.org/gnu/mpfr/mpfr-4.2.2.tar.xz
tar xf gcc-15.2.0.tar.xz
tar xf gmp-6.3.0.tar.xz
tar xf mpc-1.4.1.tar.gz
tar xf mpfr-4.2.2.tar.xz
mv gmp-6.3.0 gcc-15.2.0/gmp
mv mpc-1.4.1 gcc-15.2.0/mpc
mv mpfr-4.2.2 gcc-15.2.0/mpfr
mkdir -p /opt/baremetalmipsel/build/gcc-15.2.0-stage-1
cd /opt/baremetalmipsel/build/gcc-15.2.0-stage-1
export PATH=/opt/baremetalmipsel/bin:${PATH}
../../src/gcc-15.2.0/configure --prefix=/opt/baremetalmipsel --target=mipsel-none-elf --enable-languages=c,c++ --without-headers --disable-nls --disable-threads --disable-shared --disable-libssp --with-newlib –disable-libstdcxx
make all-gcc all-target-libgcc
make install-gcc install-target-libgcc
newlib
cd /opt/baremetalmipsel/src
git clone https://sourceware.org/git/newlib-cygwin.git
mkdir -p /opt/baremetalmipsel/build/newlib
cd /opt/baremetalmipsel/build/newlib
../../src/newlib-cygwin/configure --prefix=/opt/baremetalmipsel --target=mipsel-none-elf
make
make install
gcc (fase 2)
mkdir -p /opt/baremetalmipsel/build/gcc-15.2.0-stage-2
cd /opt/baremetalmipsel/build/gcc-15.2.0-stage-2
../../src/gcc-15.2.0/configure --prefix=/opt/baremetalmipsel --target=mipsel-none-elf --enable-languages=c,c++ --disable-nls --disable-threads --disable-shared --disable-libssp --with-newlib --with-headers=../../src/newlib-cygwin/newlib/libc/include
make
make install
De esta manera ya tendríamos instalada nuestra toolchain en "/opt/baremetalmipsel/bin".
Script de enlazado y código de arranque
El script de enlazado que se usará está basado en el publicado por Xoddiel con algunas modificaciones menores. Le he añadido la referencia a "startup.o" que es mi forma preferida de implementar las funciones de arranque antes de invocar la función "main":
RAM_BASE = 0x80000000; /* this is the start of our main memory segment */
RAM_SIZE = 2M; /* PSX has 2 MiB of RAM */
BIOS_SIZE = 64K; /* PSX reserves the lower 64 KiB of RAM for BIOS/kernel */
HEADER_SIZE = 2K; /* PSX EXE files must start with a 2 KiB header */
LOAD_ADDR = RAM_BASE + BIOS_SIZE; /* address where our binary will be loaded (0x80010000) */
STACK_INIT = RAM_BASE + 0x001FFF00; /* the top of our stack (remember, stack grows downwards) */
/* the layout of our memory */
MEMORY {
HEADER : ORIGIN = LOAD_ADDR - HEADER_SIZE, LENGTH = HEADER_SIZE
RAM (rwx) : ORIGIN = LOAD_ADDR, LENGTH = RAM_SIZE - (LOAD_ADDR - RAM_BASE)
}
/* here we tell the linker how should the file be filled with data */
SECTIONS {
/* this is our PSX EXE header */
.psx_exe_header : {
/* magic number (ASCII string "PS-X EXE") */
BYTE(0x50); BYTE(0x53); BYTE(0x2d); BYTE(0x58);
BYTE(0x20); BYTE(0x45); BYTE(0x58); BYTE(0x45);
/* 8 unused bytes */
QUAD(0);
/* our entry point */
LONG(ABSOLUTE(__text_start));
/* intial value of global pointer (I don't think this is used by Rust) */
LONG(0);
/* address where our binary gets loaded to */
LONG(LOAD_ADDR);
/* number of bytes that should be loaded (after this header) */
LONG(__bss_start - __text_start);
/* 16 unused bytes */
QUAD(0); QUAD(0);
/* stack base pointer */
LONG(STACK_INIT);
/* initial stack offset */
LONG(0);
/* 24 unused bytes */
QUAD(0); QUAD(0); LONG(0);
/* region indicator (North America, Europe, Japan) */
KEEP(*(.region));
/* alignment to 2 KiB */
. = ALIGN(HEADER_SIZE);
} > HEADER
/* here is where our code lives */
.text : {
__text_start = .;
startup.o (.startup)
/* our constructors table */
__ctors_start = .;
,*(.ctors*)
__ctors_end = .;
ASSERT((__ctors_end - __ctors_start) % 4 == 0, "Invalid .ctors section");
/* our destructors table */
__dtors_start = .;
,*(.dtors*)
__dtors_end = .;
ASSERT((__dtors_end - __dtors_start) % 4 == 0, "Invalid .dtors section");
/* the majority of our code */
,*(.text*)
__text_end = .;
} > RAM
/* this is where all of our static variables, strings, etc. live */
.data : {
__data_start = .;
,*(.data*)
,*(.rodata*)
,*(.got)
/* padding to a multiple of 2K is required for loading from ISO */
. = ALIGN(2048);
__data_end = .;
} > RAM
/* this is that uninitialized .bss section, I was talking about */
.bss (NOLOAD) : {
__bss_start = .;
,*(.bss*)
,*(COMMON)
__bss_end = .;
} > RAM
/* make the heap word-aligned */
. = ALIGN(4);
__heap_start = .;
/* drop all sorts of useless metadata */
/DISCARD/ : {
*(.MIPS.abiflags)
*(.reginfo)
*(.eh_frame_hdr)
*(.eh_frame)
}
}
En "startup.cpp" defino la función "_startup" en la sección ".startup" (los nombres son arbitrarios, no tienen por qué ser esos) y en el script de enlazado indico que el punto de entrada es el código que está en la sección ".startup".
using namespace std; extern "C" { extern void (*__ctors_start)(); extern void (*__ctors_end)(); extern void (*__dtors_start)(); extern void (*__dtors_end)(); } void _callConstructors() { void (**constructor)() = &__ctors_start; while (constructor != &__ctors_end) { (*constructor)(); constructor++; } } void _callDestructors() { void (**destructor)() = &__dtors_start; while (destructor != &__dtors_end) { (*destructor)(); destructor++; } } extern int main(); extern "C" { extern unsigned char __bss_start; extern unsigned char __bss_end; } void _initBssRAM() { // init .bss section with zeros unsigned char *p = &__bss_start; while (p != &__bss_end) { *p = 0; p++; } } void _startup() __attribute__((section(".startup"))); // startup located at begining of EXE void _startup() { _initBssRAM(); _callConstructors(); main(); _callDestructors(); while (true) ; } extern "C" void __cxa_pure_virtual() {} void *__dso_handle = 0; extern "C" void __cxa_atexit() {}
Como todo el .EXE se carga en RAM, las variables globales inicializadas no hace falta que sean copiadas y sólo es necesario inicializar a cero la zona de memoria "BSS" (función "_initBssRam") e invocar los constructores globales que defina el compilador en la sección ".ctors" (función "_callConstructors").
Compilación de un proyecto
Para compilar un proyecto, compilamos todos los fuentes del mismo de la siguiente manera:
$ mipsel-none-elf-g++ -std=c++20 -march=r3000 -fno-exceptions -fno-rtti -nostartfiles -nodefaultlibs -G 0 -c -o fichero1.o fichero1.cpp
$ mipsel-none-elf-g++ -std=c++20 -march=r3000 -fno-exceptions -fno-rtti -nostartfiles -nodefaultlibs -G 0 -c -o fichero2.o fichero2.cpp
$ ...
$ mipsel-none-elf-g++ -std=c++20 -march=r3000 -fno-exceptions -fno-rtti -nostartfiles -nodefaultlibs -G 0 -c -o startup.o startup.cpp
Enlazamos los ficheros objeto que acabamos de generar con el script de enlazado:
$ mipsel-none-elf-g++ -std=c++20 -march=r3000 -fno-exceptions -fno-rtti -nostartfiles -nodefaultlibs -G 0 -T ps1.ld -o main.elf startup.o fichero1.o fichero2.o ...
Esto produce un fichero "main.elf" que se puede convertir a PSX.EXE fácilmente de la siguiente manera:
$ mipsel-none-elf-objcopy -O binary main.elf psx.exe
En la cabecera del fichero "psx.exe", el campo "filesize" contiene el tamaño del fichero "psx.exe" excluyendo la cabecera de 2048 bytes y dicho valor debe ser múltiplo de 2048 bytes (2048 bytes es el tamaño de un sector del CD-ROM). Para asegurarnos de que este campo tiene un valor múltiplo de 2048 hice el script "round_up_size.sh", que hace un redondeo hacia arriba de dicho valor en caso necesario en la misma cabecera del fichero "psx.exe".
Después de obtener el fichero PSX.EXE y tras invocar el script "round_up_size.sh" montamos la imagen del CD-ROM que lo contendrá (junto con otros ficheros que queramos incluir en el CD-ROM: datos de juego, sprites, texturas, audio, etc.). Para crear una imagen de CD-ROM compatible con PlayStation 1 lo mejor es usar la herramienta psximager mediante los siguientes pasos.
1. Creamos un fichero "catálogo" para el psximager que describa la estructura del CD-ROM:
system_area {
file "license.sys"
}
volume {
system_id [PLAYSTATION]
volume_id [MYGAME]
publisher_id [AVELI]
creation_date 2026-05-04 22:00:00.00 0
}
dir {
file PSX.EXE
}El fichero "license.sys" incluye los datos de licencia del juego. En mi caso los extraje de un juego comercial para la misma región (Europa) que mi PlayStation 1 (incluí el fichero "license.sys" en el targz del proyecto).
2. Los ficheros que queremos que vayan en el CD-ROM los colocaremos en una carpeta que se llame igual que el fichero catálogo sin la extensión:
$ mkdir MYGAME
$ cp psx.exe MYGAME/PSX.EXE # SIEMPRE en mayúsculas para cumplir ISO9660
$ psxbuild -c MYGAME.cat
Tras estos pasos ya tendremos nuestros dos ficheros "MYGAME.bin" y "MYGAME.cue", que podremos tostar en un CD-ROM físico y ejecutarlo en una PlayStation 1 o en un emulador.
Nótese que la "licencia" de los programas que hagamos así no será válida (no está firmada digitalmente por Sony), por lo que, para ejecutar nuestro juego en una PlayStation 1 real, ésta deberá estar "chipeada" o permitir, mediante algún tipo de mod, la ejecución de código no firmado. En mi caso, modifiqué mi PlayStation 1 con el mod PSIO,que permite lanzar juegos desde tarjeta de memoria SD sin desactivar el lector de CD de la consola.
Prueba de concepto
Como primera prueba de concepto mostraremos un rectángulo alternativamente de dos colores diferentes en pantalla a razón de un cambio de color por segundo, sincronizado con el retrazo vertical de la GPU. Uno de los colores será verde o amarillo en función de si detectamos que se está pulsando el botón "derecha" en el gamepad del jugador 1.
int main() { gpu_init(); gpu_copy_font(); gpu_draw_rectangle(0, 0, 320, 240, 0x00FF0000); gpu_draw_text(0, 0, "A simple GPU example"); uint32_t n = 50; bool b = false; while (true) { gpu_wait_vblank(); uint16_t m = get_controller_mask(); n--; if (n == 0) { b = !b; if (b) { if ((m & ((uint16_t) 1) << 5) == 0) gpu_draw_rectangle(10, 10, 300, 220, 0x0000FF00); // right button pressed = green rectangle else gpu_draw_rectangle(10, 10, 300, 220, 0x0000FFFF); // no button pressed = yellow rectangle } else gpu_draw_rectangle(10, 10, 300, 220, 0x000000FF); n = 50; } } return 0; }
El resultado es fondo azul, el texto arriba a la derecha y el rectángulo central cambiando 1 vez por segundo y cambiando de color en función de si se está pulsando el botón "derecha" del gamepad.

Diseño de un juego 2D sencillo
Haremos un clon del Arkanoid o Breakout: el típico juego con la pelotita que rebota y en el que hay que romper todos los bloques. Definimos el siguiente grafo de pantallas:
Y utilizaremos la abstracción de la clase "screen_t" que se ha utilizado en otros proyectos de desarrollo de otras consolas:
extern "C++" { namespace psx { using namespace std; class shared_data_t { }; class screen_t { public: shared_data_t &shared_data; screen_t(shared_data_t &shared) : shared_data(shared) { }; virtual void on_load() = 0; virtual screen_t *on_vblank(uint16_t drawable_y_origin, bool &swap_fb, uint16_t controller_buttons) = 0; virtual void on_unload() = 0; }; class game_shared_data_t : public shared_data_t { public: uint16_t current_level_index; int16_t vertical_adjust_rel; }; } }
Características principales de este patrón de diseño:
- El constructor de "screen_t" recibe una referencia a un objeto de tipo "shared_data_t", que contiene los datos que compartirán todas las pantallas.
- La función miembro "void on_load()" se invoca cuando la pantalla se carga.
- La función miembro "screen_t *on_vblank(uint16_t drawable_y_origin, bool &swap_fb, uint16_t controller_buttons)" recibe la coordenada "y" del framebuffer donde la pantalla puede escribir si quiere, una referencia a un booleano donde devolverá si ha escrito en dicho framebuffer y, por tanto, hay que hace swap de los framebuffers en el siguiente retrazo vertical. Esta función miembro recibe también el estado de los botones del gamepad. Devuelve "nullptr" si no hay que cambiar de pantalla y un puntero a un objeto te tipo "screen_t" en caso de que haya que cambiar de pantalla.
- La función miembro "void on_unload()" se invoca en el caso de que la invocación a "on_vblank" haya devuelto diferente de nullptr y antes de invocar el "on_load" de la siguiente pantalla.
El bucle principal del juego quedaría de la siguiente manera:
int main() { controller_t controller; random_t random; game_shared_data_t shared_data; shared_data.vertical_adjust_rel = 0; // construct all the screens ... // link the screens ... // start with menu screen screen_t *current_screen = &menu_screen; // init GPU and double buffer gpu_init(); gpu_copy_font(); uint16_t drawable_y_origin = 240; gpu_set_visible(0, 0); bool swap_fb = false; current_screen->on_load(); // load first screen while (true) { gpu_wait_vblank(); controller.update(); random.update(controller.buttons); if (swap_fb) { if (drawable_y_origin == 0) { drawable_y_origin = 240; gpu_set_visible(0, 0); } else { drawable_y_origin = 0; gpu_set_visible(0, 240); } } screen_t *next_screen = current_screen->on_vblank(drawable_y_origin, swap_fb, controller.buttons); if (next_screen != nullptr) { current_screen->on_unload(); current_screen = next_screen; current_screen->on_load(); } } return 0; }
Siguiendo este modelo, la programación de las diferentes pantallas se hace más sencilla ya que nos podemos centrar en resolver cada problema. A continuación en términos generales, los aspectos más importantes de cada pantalla:
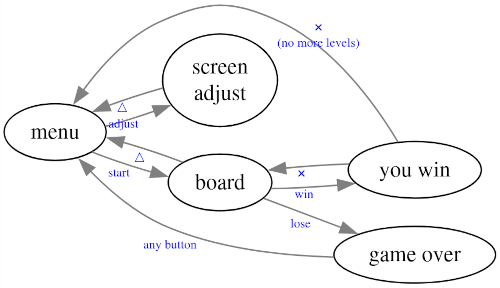
- menu_screen_t: Muestra el menú principal de 2 opciones con el que se navega con izquierda y derecha en el gamepad y se elige opción con el botón aspa.
- adjust_screen_t: Muestra una pantalla con bordes de color. Pulsando arriba y abajo en el gamepad nos permite centrar la imagen en la TV (la señal de vídeo de la PlayStation 1 es analógica y, en aquella época, había televisiones donde era necesario ajustar la visualización para que se viese la imagen centrada). En el caso de la PlayStation 1, el ajuste horizontal no es necesario, por lo que sólo se permite el ajuste vertical.
- board_screen_t: Es la pantalla principal, donde sale el tablero, los bloques, la bola que rebota, etc. Incluye las mecánicas de rebote y de puntuación, así como un timer que cuando llega a cero pasa a la pantalla de game over, un "score" y un "level" para indicar en qué nivel nos encontramos. Cuando terminamos un nivel (borramos todos sus bloques antes de que acabe el tiempo) pasamos a la pantalla "you win". Si la pelota toca suelo y tenemos un "score" de 0 o de 1 también pasamos a la pantalla de game over.
- you_win_screen_t: En esta pantalla mostramos el nivel que se ha terminado correctamente. Si quedan niveles aún, se cambia de nivel y se espera a que el jugador pulse aspa para pasar de nivel o, si no quedan niveles por pasar, se muestra un "you win!" y se pasa a la pantalla de menú.
- game_over_screen_t: En esta pantalla mostramos un "game over" y espera unos segundos antes de volver a la pantalla de menú.
Se dispone de 2 conjuntos de elementos gráficos. Por un lado una fuente 8x8: que va desde el carácter espacio hasta el carácter tilde (~), por lo que abarca todos los caracteres imprimibles en inglés:

Y por otro lado, 5 sprites también de 8x8: 3 se usan para los bloques (blanco, azul y oro), uno para la pelota y otro para la barra del jugador:

Estos dos conjuntos de elementos gráficos se cargan, en el arranque del juego, de forma fija en la VRAM y "a un lado" de los framebuffers:

De esta manera, tanto para escribir texto como para pintar bloques, la pelota o la barra del jugador, simplemente se hacen copias de bloques de datos dentro de la VRAM.
El juego es muy básico y no permite guardar partidas ni puntuaciones. A continuación puede verse el juego en acción en una PlayStation 1 real.



Todo el código está disponible en la sección soft.
[ añadir comentario ] ( 302 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 545 )La consola Nintendo Entertainment System (NES) fue una consola lanzada por Nintendo en 1983 y fue su primera consola de sobremesa basada en cartuchos de juegos. Está equipada con el procesador de 8 bits MOS6502 (mismo procesador que la Atari 2600, que el Apple II y que otros ordenadores de principios de los 80). A lo largo de esta entrada intentaré explicar de forma sencilla cómo programarla en C desarrollando un sencillo juego de buscaminas usando el compilador SDCC.
La NES dispone de una CPU y una PPU (Picture Processing Unit) con memorias separadas. La CPU accede a:
- 2 Kb de memoria RAM interna de la consola.
- Registros específicos para acceder a la PPU, la APU (audio) y E/S.
- Cartucho (ROM y, opcionalmente, RAM).
La PPU accede a:
- 2 Kb de memoria de vídeo.
- Memoria de paletas.
- Memoria de sprites.
- Otra parte del cartucho donde puede haber almacenadas baldosas, por ejemplo o RAM adicional para la PPU, aunque suele ser ROM (denominada CHR-ROM).
Como se puede ver, los cartucho NES traen, por lo general mínimo dos chips ROM: uno con el programa para la CPU (el código del juego) y un chip con las baldosas para ser mapeado directamente en la memoria de vídeo de la PPU. Esta es la configuración más sencilla y en la que nos centraremos nosotros.
Mapa de memoria
La NES permite una cantidad enorme de mapeados de memoria en los cartuchos tanto para la CPU como para la PPU. Documentar los diferentes mapeos en esta entrada sería excesivo así que me centraré en el mapeador "NROM" (https://www.nesdev.org/wiki/NROM) por ser el más sencillo:
- 16 ó 32 Kb de memoria de programa PRG-ROM.
- 8 Kb de memoria de caracteres (o baldosas) CHR-ROM.
Este mapper no requiere hacer bank-switching: toda la memoria de programa PRG-ROM se mapea directamente a partir de la dirección de memoria 0x8000 de la CPU (hasta los 32 Kb) y toda la memoria de caracteres o baldosas CHR-ROM se mapea directamente en los primeros 8 Kb de la memoria de vídeo (accesible por la PPU como "pattern table 0" y "pattern table 1").
El mapa de memoria accesible por la CPU es el siguiente (bus de direcciones de 16 bits):
| Desde | Hasta | Tamaño | Descripción |
| 0x0000 | 0x07FF | 0x0800 | RAM interna NES (2 Kb) |
| 0x2000 | 0x2007 | 0x0008 | Registros PPU |
| 0x4000 | 0x4017 | 0x0018 | Registros APU (audio) y E/S |
| 0x4020 | 0xFFFF | 0xBFE0 | Cartucho 0x6000 - 0x7FFF para RAM en el cartucho 0x8000 - 0xFFFF para ROM de programa |
Poner RAM en el cartucho es opcional y sólo lo hacen algunos juegos que permiten guardar partidas usando una RAM no volátil, por ejemplo.
El mapa de memoria accesible por la PPU es el siguiente (bus de direcciones de 14 bits):
| Desde | Hasta | Tamaño | Descripción |
| 0x0000 | 0x0FFF | 0x1000 | Pattern table 0 (4 Kb) en el cartucho |
| 0x1000 | 0x1FFF | 0x1000 | Pattern table 1 (4 Kb) en el cartucho |
| 0x2000 | 0x23BF | 0x03C0 | Name table 0 (32 x 30 bytes, uno por baldosa) |
| 0x23C0 | 0x23FF | 0x0040 | Attribute table 0 (paletas name table 0) |
| 0x2400 | 0x27BF | 0x03C0 | Name table 1 (32 x 30 bytes, uno por baldosa) |
| 0x27C0 | 0x27FF | 0x0040 | Attribute table 1 (paletas name table 1) |
| 0x2800 | 0x2BBF | 0x03C0 | Name table 2 (32 x 30 bytes, uno por baldosa) |
| 0x2BC0 | 0x2BFF | 0x0040 | Attribute table 2 (paletas name table 2) |
| 0x2C00 | 0x2FBF | 0x03C0 | Name table 3 (32 x 30 bytes, uno por baldosa) |
| 0x2FC0 | 0x2FFF | 0x0040 | Attribute table 3 (paletas name table 3) |
| 0x3F00 | 0x3F1F | 0x0020 | Paletas internas de la PPU |
Los 8 Kb (4 + 4) correspondientes a las "pattern tables" (o baldosas en sí) se mapean en el cartucho (ya sea como ROM o como RAM). En nuestro caso, con el mapeador NROM, se mapean como una ROM (llamada CHR-ROM) de 8 Kb que almacena las dos "pattern tables" seguidas una después de la otra.
El resto de la memoria de vídeo son:
- 4 Kb correspondientes a las 4 "name tables". Realmente la PPU sólo dispone de 2 Kb y en un registro de la misma se establece cómo de hace el mirroring y se disponen para el caso de que se quiera hacer efectos de scroll, por ejemplo. No será nuestro caso.
- 32 bytes correspondientes a las paletas de color internas de la PPU.
- 256 bytes correspondientes a los sprites (64 sprites, 4 bytes por sprite) que no aparecen en la tabla anterior puesto que no se encuentran direccionados en una zona concreta de la VRAM sino en unos registros aparte de la PPU.
Con este mapper "NROM" podemos hacer juegos que no requieran alterar las "pattern tables" (las baldosas) ya que dichas baldosas estarán en una ROM del cartucho (CHR-ROM) de 8 Kb. En la práctica esta limitación no es importante pues rara vez necesitaremos modificar las baldosas a nivel de pixel y muchos juegos comerciales de NES utilizan este mapeo. En caso de que necesitemos que toda o parte de la memoria de caracteres (baldosas) sea RAM, tendríamos que utilizar otro tipo de mapper que no sea NROM.
Fichero .nes
Como lo que queremos al final es poder jugar a los juegos que hagamos para la NES, necesitamos que el proceso de compilación genere un fichero ".nes" que pueda ser ejecutado en un emulador o incluso cargado en un cartucho flash de una NES real. Para el mapeador "NROM" si lo que queremos es una ROM de programa (PRG-ROM) de 32 Kb más una memoria ROM de baldosas (CHR-ROM) de 8 Kb (para almacenar las "pattern tables" 0 y 1) el fichero tendrá que tener el siguiente formato interno:
| Desde | Hasta | Tamaño | Contenido |
| 0x0000 | 0x000F | 0x0010 | 4e 45 53 1a 02 01 00 00 00 00 03 00 00 00 00 00 |
| 0x0010 | 0x800F | 0x8000 | PRG-ROM o ROM del programa (32 Kb) |
| 0x8010 | 0xA00F | 0x2000 | CHR-ROM o ROM de caracteres (baldosas) (8 Kb) |
| Total | 0xA010 | ||
La cabecera y la disposición de los datos vienen explicados con más detalle en https://www.nesdev.org/wiki/INES y no me pararé a explicar lo que significa cada byte. Por ahora baste saber que con esa cabecera tenemos un fichero ".nes" con mapeador NROM, 32 Kb de memoria de programa y 8 Kb de memoria de baldosas (CHR-ROM). Al final el tamaño del fichero ".nes" generado en nuestro caso será siempre de 0xA010 bytes (40976 bytes).
Secuencia de arranque
La NES asume el siguiente contenido en estas posiciones de la memoria accesible por la CPU:
| Desde | Hasta | Tamaño | Descripción |
| 0xFFFA | 0xFFFB | 2 | Puntero a rutina de servicio de NMI (interrupción no enmascarable) |
| 0xFFFC | 0xFFFD | 2 | Puntero a código de arranque |
| 0xFFFE | 0xFFFF | 2 | Puntero a rutina de servicio de IRQ (interrupción enmascarable) |
Como nosotros usaremos el mapper NROM, podemos hacer una ROM de 32 Kb que se alojará a partir de la dirección 0x8000 y en los últimos 6 bytes de esa ROM podremos esos tres punteros indicados en la tabla.
A continuación puede verse el detalle del fichero "crt0nes.s" utilizado:
.module crt0nes
.globl _main ; programmer must define these functions in C
.globl _irq_isr
.globl _nmi_isr
.area _HEAD (ABS)
.org 0x8000
jmp init
jmp _irq_isr
jmp _nmi_isr
init:
sei ; ignore IRQs
cld ; disable decimal mode
ldx #0x40
stx 0x4017 ; disable APU frame IRQ
ldx #0xff
txs ; set stack pointer to $01ff
inx ; now X = 0
stx 0x2000 ; disable NMI
stx 0x2001 ; disable rendering
stx 0x4010 ; disable DMC IRQs
; The vblank flag is in an unknown state after reset,
; so it is cleared here to make sure that @vblankwait1
; does not exit immediately.
bit 0x2002
; First of two waits for vertical blank to make sure that the
; PPU has stabilized
vblankwait1:
bit 0x2002
bpl vblankwait1
; We now have about 30,000 cycles to burn before the PPU stabilizes.
; One thing we can do with this time is put RAM in a known state.
; Here we fill it with $00, which matches what (say) a C compiler
; expects for BSS. Since we haven't modified the X register since
; the earlier code above, it's still set to 0, so we can just
; transfer it to the Accumulator and save a byte
txa
clrmem:
sta 0x00,x
sta 0x100,x
sta 0x200,x
sta 0x300,x
sta 0x400,x
sta 0x500,x
sta 0x600,x
sta 0x700,x
inx
bne clrmem
vblankwait2:
bit 0x2002
bpl vblankwait2
; init global variables
jsr gsinit
; main function
jsr _main
inf_loop:
jmp inf_loop
; ordering of segments for the linker.
.area _HOME
.area _CODE
.area CODE
.area _INITIALIZER
.area _GSINIT
gsinit::
.area _GSFINAL
rts
.area RODATA
.area _TAIL (ABS)
.org 0xFFFA
.dw #0x8006
.org 0xFFFC
.dw #0x8000
.org 0xFFFE
.dw #0x8003
Como se puede comprobar en las posiciones de memoria finales se incluyen esos tres punteros descritos. El programador está obligado a definir en C las funciones:
- "irq_isr": para atender la interrupción enmascarable (relacionada con el audio).
- "nmi_isr": para atender la interrupción no enmascarable (asociada al vblank de la PPU).
- "main": para escribir el código de arranque del juego.
De la siguiente manera:
void irq_isr(void) __interrupt { // atender interrupción de audio } void nmi_isr(void) __interrupt { // atender interrupción de retrazo vertical (vblank) } void main(void) { // código principal del juego }
Interrupciones
La CPU de la NES tiene 2 fuentes de interrupción:
-NMI (interrupción no enmascarable): no puede deshabilitarse y se dispara en cada retrazo vertical de la pantalla (60 veces por segundo, después de cada frame, en sistemas de televisión NTSC y 50 veces por segundo en sistemas de televisión PAL). La genera la PPU y, aunque no puede deshabilitarse desde la CPU, sí puede configurarse la PPU para que la genere o no. Lo normal es usarla y basar el timing de nuestro juego en esta interrupción.
- IRQ (interrupción enmascarable): puede deshabilitarse y habilitarse desde la CPU y normalmente está asociada a la APU, aunque algunos mappers y periféricos también la utilizar. En nuestro caso, como no la usaremos, definimos la función "irq_isr" vacía.
Compilar el compilador
Para programar en C el 6502 hay varios compiladores y proyectos pero yo siempre he tenido "debilidad" por el SDCC, por ser un compilador muy completo, con licencia GPL y con buen soporte por parte de la comunidad. Compilar el compilador SDCC es muy sencillo, basta descargarlo de https://sdcc.sourceforge.net/, decomprimirlo y realizar los siguientes pasos:
$ cd /ruta/fuente/sdcc
$ ./configure --prefix=/ruta/destino/sdcc --disable-pic14-port --disable-pic16-port
$ make
$ make install
Ahora ya tendremos instalado el SDCC en la carpeta "/ruta/destino/sdcc".
Ejemplo sencillo
Como ejemplo sencillo tenemos que partir de una CHR-ROM que hagamos nosotros o que esté ya hecha y podamos usar. La web https://jimmarshall35.github.io/TileEditor/index.html permite cargar ROM de NES y extraerles y editarles la CHR-ROM. En mi caso he extraido la CHR-ROM del juego homebrew "Thwaite" que tiene licencia GPL. La CHR-ROM de este juego tiene la ventaja de que las baldosas 32 a la 127 mapean los caracteres imprimibles del alfabeto ASCII.
#define PPUCTRL *((volatile uint8_t *) 0x2000) #define PPUMASK *((volatile uint8_t *) 0x2001) #define PPUSTATUS *((volatile uint8_t *) 0x2002) #define OAMADDR *((volatile uint8_t *) 0x2003) #define OAMDATA *((volatile uint8_t *) 0x2004) #define PPUSCROLL *((volatile uint8_t *) 0x2005) #define PPUADDR *((volatile uint8_t *) 0x2006) #define PPUDATA *((volatile uint8_t *) 0x2007) void irq_isr(void) __interrupt { } volatile uint16_t v; void nmi_isr(void) __interrupt { PPUSTATUS; PPUADDR = 0x20; PPUADDR = 0x05; PPUDATA = (v >> 3) & 0x00FF; // change some tile each 2^3 = 8 frames PPUCTRL = 0x80; // base nametable = 0x2000, VRAM increment = 1, sprite pattern table = 0, background pattern table = 0, sprite size = 8x8, enable VBlank NMI PPUSTATUS; PPUSCROLL = 0x00; PPUSCROLL = 0x00; v++; } const char STR_1[] = "TEST1"; const char STR_2[] = "TEST2"; void show_str(const char *p) { while (*p != 0) { PPUDATA = *p; p++; } } void main(void) { v = 0; // disable rendering PPUCTRL = 0x00; PPUMASK = 0x00; // put STR_1 and STR_2 string in nametable (at 1st and 2nd line respectively) PPUSTATUS; PPUADDR = 0x20; // STR_1 at 1st line of nametable 0x2000 PPUADDR = 0x00; show_str(STR_1); PPUSTATUS; PPUADDR = 0x20; // STR_2 at 2nd line of nametable 0x2000 PPUADDR = 0x20; show_str(STR_2); // init palette PPUSTATUS; PPUADDR = 0x3F; PPUADDR = 0x00; PPUDATA = 0x0F; // palette 0, color 0, black PPUDATA = 0x12; // palette 0, color 1, blue PPUDATA = 0x2A; // palette 0, color 2, green PPUDATA = 0x30; // palette 0, color 3, white // enable rendering PPUMASK = 0x0A; // color, show background in leftmost 8 pixels, enable background rendering PPUCTRL = 0x80; // base nametable = 0x2000 (bits 1 and 0 = 0), VRAM increment = 1, sprite pattern table = 0, background pattern table = 0, sprite size = 8x8, enable VBlank NMI PPUSTATUS; PPUSCROLL = 0x00; // update "t" internal register so top-left at beginning of nametable PPUSCROLL = 0x00; // infinite loop (wait vblank NMI) while (1) ; }
El programa imprime dos cadenas de texto al principio de la "name table" 0, habilita la interrupción NMI (la que se dispara en cada retrazo vertical (VBlank)) para hacer que una baldosa cambie varias veces por segundo.
Para generar la ROM haremos lo siguiente:
# ensamblamos el crt0
$ sdas6500 -o crt0nes.rel crt0nes.s
# compilamos el main.c
$ sdcc -mmos6502 --stack-auto -c -o main.rel main.c
# enlazamos todo y generamos el ejecutable main.ihx (formato intel hex)
$ sdcc -mmos6502 --stack-auto --no-std-crt0 -o main.ihx crt0nes.rel main.rel
# generamos el PRG-ROM a partir del intel hex (main.ihx)
$ objcopy -I ihex -O binary main.ihx main.prg-rom
# generamos la ROM en formato ".nes" (como si fuese un cartucho)
$ cat main.header main.prg-rom main.chr-rom > main.nes
Ya podemos ejecutar la ROM "main.nes" con un emulador o pasarlo a un cartucho flash y ejecutarlo en una consola real.

El fichero "main.header" es un fichero de 16 bytes que contiene la cabecera del fichero ".nes" mientras que el fichero "main.chr-rom" es un fichero de 8 Kb que contiene las baldosas extraidas del juego "Thwaite". Ambos ficheros están en el "nes.tar.gz" de la sección soft.
RAM y pila
La pila en la gran mayoría de procesadores de 8 y más bits puede ser alojada en cualquier sitio de la RAM teniendo el puntero de pila la misma cantidad de bits que el bus de direcciones. Ese no es el caso del 6502.
En el 6502 el puntero de pila (registro S) es un registro de 8 bits por lo que la pila del sistema sólo puede almacenar 256 bytes y, además, dicha pila está localizada siempre entre 0x0100 y 0x01FF. En el arranque se recomienda inicializar S a 0xFF ya que la pila crece hacia direcciones de memoria inferiores cuando se hace PUSH (instrucciones "PHA" y "PHP") y viceversa, decrece hacia direcciones de memoria superiores cuando se hace POP (instrucciones "PLA" y "PLP").
Con respecto al resto de la RAM, hay que tener en cuenta que los accesos a la "página 0" (o "Zero Page", ZP) de la memoria (direcciones 0x0000 a 0x00FF) son más rápidos en ciclos de reloj que los accesos al resto de la memoria. Por tanto, lo lógico es intentar que la mayor cantidad posible de variables que se usen con frecuencia se alojen en la página 0 (ZP) entre 0x0000 y 0x00FF. El compilador se encarga de esas cosas aunque el SDCC no es muy "inteligente" y al final las coloca por orden de declaración en el código.
Éstas son algunas de las consideraciones que hay que tener en cuenta a la hora de programar:
- La cantidad de bytes que necesitemos para variables globales determinarán si pueden ser alojadas todas en la página 0 o no. Cuando se excedan los 256 bytes de variables globales se empezarán a alojar después de la pila a partir de 0x0200 (que es una zona de memoria RAM más lenta que la página 0).
- El SDCC en el caso del 6502 trata de optimizar el uso de la pila y este tipo de optimización suele ser incompatible con algunos mecanismos avanzados del lenguaje como punteros a funciones o recursividad. Para estos casos existe la opción "--stack-auto" que hace que la pila sea usada de forma "habitual" como se haría con cualquier otro procesador: permitiendo punteros a funciones y recursividad, con la penalización de que la pila crecerá muy rápido y la profundidad de llamadas anidadas que podamos hacer será limitada.
- Se debe tener en cuenta que las variables locales se alojan en pila por lo que hay que ser cuidadosos a la hora de declararlas y evitar meter objetos o estructuras muy grandes en ellas.
- Las constantes ("const") se alojan en la memoria de programa (PRG-ROM), por lo que no ocupan RAM (ni pila).
Consideraciones especiales con respecto a la VRAM de la PPU
La PPU de la NES es extremadamente sencilla y adolece de un "problema" de diseño que hace que el registro interno utilizado para direccionar la VRAM sea el mismo tanto para acceder desde la CPU como para renderizar.
La CPU se comunica con la PPU escribiendo y leyendo en una serie de registros mapeados en la RAM de la CPU (https://www.nesdev.org/wiki/PPU_registers) por lo que cada vez que la CPU necesite acceder a la VRAM debe escribir en el registro PPUADDR la dirección en la VRAM a la que quiere acceder y a continuación escribir o leer en el registro PPUDATA el byte. Estos accesos a la VRAM por parte de la CPU "ensucian" un registro interno que utiliza la PPU para el renderizado, por lo que, antes de que se empiece a renderizar el siguiente frame, se deben actualizar los registros PPUCTRL y PPUSCROLL (aunque sea para poner un 0 si no hay scroll). De esta forma nos aseguramos que cuando empieza a dibujarse la pantalla se hace desde la coordenada que realmente queremos.
Por ejemplo, si, durante el retrazo vertical queremos escribir en una posición de la VRAM haremos:
PPUSTATUS; // se fuerza el reset del flip-flop que determina qué parte de la dirección se carga primero PPUADDR = byte alto de la direccion VRAM PPUADDR = byte bajo de la direccion VRAM PPUDATA = primer byte PPUDATA = segundo byte // antes de terminar “limpiamos” el registro interno que hemos “ensuciado” PPUCTRL = 0x80; // nametable = 0x2000, VRAM increment = 1, sprite pattern table = 0, background pattern table = 0, sprite size = 8x8, enable VBlank NMI PPUSTATUS; PPUSCROLL = 0x00; // sin scroll PPUSCROLL = 0x00;
Sprites
la PPU de la NES permite trabajar con hasta 64 sprites simultáneamente. Los sprites pueden ser de 8x8 o de 8x16 (en nuestro caso opté por sprites de 8x8 por ser más sencillos de manejar). Cada sprite está definido por 4 bytes (la memoria de sprites de la PPU es de 256 bytes):
- byte 0: coordenada Y: byte sin signo. No se admiten valores negativos.
- byte 1: índice de baldosa a usar
- byte 2: atributos: paleta a utilizar, si está delante o detrás del fondo, si hay que invertir la baldosa horizontalmente y/o verticalmente. Útil para cuando tengamos sprites con algún tipo de simetría y ahorrarnos baldosas.
- byte 3: coordenada X: sin signo. No se admiten valores negativos.
Como en muchas otras consolas, el color 0 es el color transparente, por tanto cada sprite de 8x8 sólo tiene 3 colores más el fondo. Para poder "esconder" suavemente un sprite por el lado izquierdo de la pantalla hay un truco que se usa mucho que es decirle a la PPU que no renderice los 8 pixels de la izquierda de la pantalla para el fondo y/o para los sprites (mediante el registro PPUCTRL que tienes dos bits para esto). "Esconder" sprites por el lado superior (coordenada Y negativa) no era necesario pues en la práctica ni las primeras 8 líneas de arriba ni las últimas 8 líneas de abajo llegaban a ser visibles en la mayoría de las pantallas (ni PAL ni NTSC).
A la hora de manipular y modificar los sprites hay dos formas de hacerlo:
- Accediendo a los registros OAMADDR y OAMDATA para poner la dirección y el dato respectivamente.
- Accediendo mediante DMA (la mejor forma y más eficiente): Se decide una zona de la RAM de la CPU (dentro de los 2 Kb) donde se podrá una copia de los 256 bytes de configuración de los sprites. Esa zona de 256 bytes debe estar alineada con una página de la RAM, es decir, tiene q ser unadirección de memoria de la forma 0xXX00 y, tras escribir en los 256 bytes de esa zona (entre 0xXX00 y 0xXXFF), escribimos en el registro OAMADDR un 0 y en el registro OAMDMA el byte alto de la dirección (OAMDMA = 0xXX).
Por ejemplo, usando el mecanismo de DMA, si decidimos configurar los sprites en la dirección 0x0700 (al final de la RAM), la coordenada Y del sprite 0 estará en 0x0700, el índice de la baldosa del sprite 0 en 0x0701 y así con el resto de sprites hasta la posición 0x07FF que será la coordenada X del sprite 63. De esta forma basta con hacer:
OAMADDR = 0;
OAMDMA = 0x07;
Para que el controlador DMA de la PPU se encargue de mandar todos esos valores más rápido de lo que lo haría la CPU (la cantidad de bytes que se manda es siempre 256 y siempre desde la memoria de la CPU a la memoria de sprites del la PPU, no en sentido contrario).
Este mecanismo es el más rápido y elegante para mover y manipular sprites de forma rápida. Es el que se utiliza en el ejemplo de juego que se describe a continuación.
Desarrollo de un pequeño juego
Se plantea el desarrollo de un Buscaminas (Minesweeper) sencillo. El guión del juego sería el siguiente:
En el que cada nodo será una pantalla del juego. La forma en que se implementará la dinámica y los estados del juego será a través de una estructura de datos que simulará orientación a objetos mediante estructuras con punteros a funciones. Definimos la estructura "screen_t":
struct screen_t { void (*on_load)(struct inter_screen_data_t *); const struct screen_t *(*on_vblank)(uint8_t, struct inter_screen_data_t *); void (*on_unload)(struct inter_screen_data_t *); };
Dicha estructura define tres punteros a funciones:
- void on_load(struct inter_screen_data_t *): Se invoca justo cuando entramos en una pantalla (nodo del guión) y se encarga de configurarla (definir paletas, baldosas, sprites, variables globales, etc). Debe dejar la pantalla ya preparada y activada. Recibe como parámetro un puntero a una estructura que se usa para pasar valores entre pantallas (nodos del guión).
- const struct screen_t *on_vblank(uint8_t, struct inter_screen_data_t *): Se invoca después de cada retrazo vertical. Recibe por parámetros, además de la estructura "inter_screen_data_t" un byte indicando el estado del controlador (botones A, B, start, select y cruceta, en forma de bits a 0 o a 1). La función devuelve un puntero a una estructura "screen_t" o NULL. En caso de devolver una estructura "screen_t" que no sea la misma que la actual, significa que el juego debe cambiar de pantalla.
- void on_unload(struct inter_screen_data_t *): Se invoca en caso de que "on_vblank" devuelva un puntero a una "screen_t" que no sea la propia y justo antes de invocar el "on_load" de la siguiente pantalla.
Nótese que, al utilizar el mecanismo de punteros a funciones, estamos obligados a utilizar la opción "--stack-auto" del compilador, que produce una penalización en la cantidad de datos que se meten en la pila.
El esqueleto principal del juego quedaría como sigue:
volatile struct inter_screen_data_t isd; void irq_isr(void) __interrupt { } volatile uint8_t vblank; void nmi_isr(void) __interrupt { vblank = 1; } const struct screen_t screens[] = { { title_screen_on_load, title_screen_on_vblank, title_screen_on_unload }, { board_screen_on_load, board_screen_on_vblank, board_screen_on_unload }, { end_screen_on_load, end_screen_on_vblank, end_screen_on_unload } }; void main(void) { vblank = 0; const struct screen_t *current_screen = screens; current_screen->on_load(&isd); uint8_t controller_mask = controller_read(); // infinite loop (wait vblank NMI) while (1) { if (vblank) { vblank = 0; const struct screen_t *next_screen = current_screen->on_vblank(controller_mask, &isd); if ((next_screen != NULL) && (next_screen != current_screen)) { current_screen = next_screen; current_screen->on_load(&isd); } controller_mask = controller_read(); } } }
Para cada nodo del guión del juego definimos un ".h" y un ".c" que definirá como mínimo esas tres funciones para ese nodo. Por ejemplo, para la pantalla de título tenemos el fichero "title_screen.h":
void title_screen_on_load(struct inter_screen_data_t *d); const struct screen_t *title_screen_on_vblank(uint8_t controller_mask, struct inter_screen_data_t *d); void title_screen_on_unload(struct inter_screen_data_t *d);
Y el fichero "title_screen.c":
void title_screen_on_load(struct inter_screen_data_t *d) { // deshabilitar renderizado // inicializar esta pantalla // configurar PPU (baldosas, paletas, sprites, etc.) para esta pantallaines); // habilitar renderizado } const struct screen_t *title_screen_on_vblank(uint8_t controller_mask, struct inter_screen_data_t *d) { // rutina porincipal de vblank // devolver NULL para permanecer en esta pantalla // devolver puntero a otra screen si se quiere cambiar de pantalla } void title_screen_on_unload(struct inter_screen_data_t *d) { // código a ejecutar antes de irse de esta pantalla (puede estar vacío) }
En "main.c" incluimos los ".h" de todas las pantallas y definimos el array "screens" como constante que guarda los punteros a todas las funciones definidas.
La ventaja de esta aproximación es que en cada ".c" nos podemos centrar en el problema de pintar, leer las entradas y gestionar esa pantalla en concreto, sin preocuparnos por las demás y añadir nodos o cambiar el comportamiento de algunos apenas requerirá cambiar "main.c".
La paleta de colores no se cambia en este juego: se define una sola vez y se escribe en la PPU en "main.c" antes de empezar el bucle principal del juego. A continuación se comentan algunas cosas de interés:
CHR-ROM
La CHR-ROM utilizada es la del juego Thwaite con licencia GPL a la que se le han realizado algunos retoques para incluir baldosas para el tablero de minas y para los sprites encargados de resaltar la posición en la que nos encontramos en cada momento.

Nótese que como cada baldosa son 8x8 pixels, si queremos que el sprite haga de "marco exterior" de la baldosa donde se encuentra en cada momento, debe medir 10x10 pixels, por lo que necesitamos 4 sprites (ocupar 16x16 pixels) para generar un sprite de 10x10.
Pantalla de título
Para indicar la cantidad de minas con las que queremos inicializar el tablero lo lógico es usar un byte para almacenar el valor. Sin embargo a la hora de mostrar un byte por pantalla en formato decimal (para 2 cifras) hay que hacer una división entre 10, siendo las decenas el cociente y el resto de la división las unidades. Algo que parece trivial para un procesador actual, pero que para el 6502 es todo un mundo. Lo que hace el SDCC es implementar un algoritmo de división por software que funciona bien pero consume muchos ciclos de reloj.
Teniendo en cuenta que con respecto a la cantidad de minas sólo se iban a realizar operaciones de incremento, decremento y visualizar, y que la cantidad máxima de minas sería 99, se optó por almacenar dicho valor en formato BCD: por ejemplo el valor 45 en decimal es 0x2D en hexadecimal y 0x45 en BCD. Haciéndolo de esta forma la visualización es muy rápida:
decenas = (valor >> 4) + '0'
unidades = (valor & 0x0F) + '0'
Y, aunque los incrementos y decrementos son algo más complejos, compensa no tener que hacer una división entera para visualizar el valor cada vez que cambia.
#define BCD_INC(bcd_v) ((((bcd_v) & 0x0F) == 0x09) ? (((bcd_v) + 0x10) & 0xF0) : ((bcd_v) + 1)) #define BCD_DEC(bcd_v) ((((bcd_v) & 0x0F) == 0x00) ? ((((bcd_v) - 0x10) & 0xF0) | 0x09) : ((bcd_v) - 1))
Pantalla de tablero
El tablero es de 16 x 16 = 256 baldosas y está centrado en la pantalla. Al tener esa cantidad de posiciones, el offset en el tablero puede ser definido con un solo byte (0x00 a 0xFF) y, además, el nibble menos significativo de ese byte es la coordenada X mientras que el nibble más significativo es la coordenada Y:
// obtener offset a partir de coordenadas uint8_t offset = (y << 4) | x; uint8_t valor = tablero[offset]; // obtener coordenadas a partir de offset uint8_t x = offset & 0x0F; uint8_t y = offset >> 4;
Cada posición del tablero es un byte con los siguientes valores:
- 0x0F: para indicar que en esa posición hay una mina
- 0x01 a 0x08: para indicar que alrededor hay 1 a 8 minas. Al descubrirse esta baldosa aparece el número correspondiente.
0x00: para indicar que alrededor hay 0 minas. Igual que el anterior caso con la diferencia de que en este caso se muestra un hueco negro (no se muestra un "0").
Y las siguientes máscaras:
- 0x80: es una máscara que indica si esa posición está "pisada" o "descubierta". Por ejemplo una posición con el valor 0x84 es una posición descubierta que tiene alrededor 4 minas (y por tanto visualiza el número 4). El valor 0x8F nunca se va a dar pues en cuanto se pisa una mina termina en juego con "game over". Para pisar una posición presionamos el botón A del mando de la NES.
- 0x40: es una máscara que indica si en esa posición hemos puesto una banderita para ayudarnos a localizar las posiciones donde sospechamos que hay minas. Las posiciones donde haya una bandera no puede ser pisadas ("descubiertas"). Para colocar o quitar una bandera presionamos el botón B del mando de la NES.
En caso de que se pise una posición con bomba y sin banderita se terminará el juego con "game over" mientras que si se descubren todas las posiciones que no tengan minas y quedan cubiertas sólo las posiciones que tienen minas (tengan banderita o no), se terminará el juego con un "you win!".
La pantalla de "game over" o "you win!" permanece unos segundos antes de regresar a la pantalla de título de nuevo. A continuación puede verse el juego cargado en un emulador:
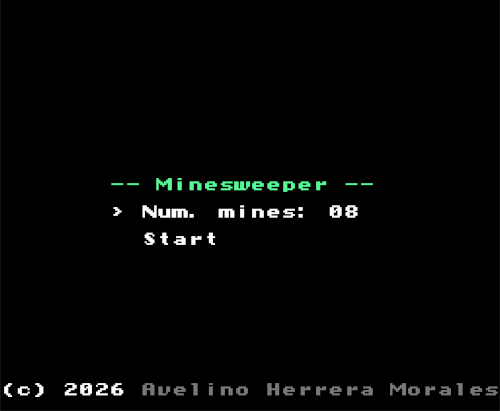

El marco azul que se va moviendo son 4 sprites dispuestos en cuadrado (2x2 sprites, 16x16 pixels) asociados a las baldosas 0x93, 0x94, 0xA3 y 0xA4. Esas baldosas juntas crean la imagen de un marco de 10x10 pixels con el centro de 8x8 pixels transparente y son los 4 sprites que se van moviendo de forma solidaria al pulsar los botones de la cruceta.
A continuación puede verse de forma resumida cómo se definen los sprites y cómo se mueven utilizando la técnica de transferencia DMA:
struct sprite_t { uint8_t y; uint8_t tile; uint8_t attr; uint8_t x; }; // sprites al final de la RAM #define SPRITES ((struct sprite_t *) 0x0700) // En el on_load situamos los 4 sprites // en la esquina superior izquierda del tablero SPRITES[0].x = 63; // top left sprite SPRITES[0].y = 54; SPRITES[0].tile = 0x93; SPRITES[0].attr = 0x00; SPRITES[1].x = 71; // top right sprite SPRITES[1].y = 54; SPRITES[1].tile = 0x94; SPRITES[1].attr = 0x00; SPRITES[2].x = 63; // bottom left sprite SPRITES[2].y = 62; SPRITES[2].tile = 0xA3; SPRITES[2].attr = 0x00; SPRITES[3].x = 71; // bottom right sprite SPRITES[3].y = 62; SPRITES[3].tile = 0xA4; SPRITES[3].attr = 0x00; OAMADDR = 0; // transferencia DMA OAMDMA = 0x07; // Para moverlos una posición del tablero // a la derecha en on_vblank bastaría con hacer SPRITES[0].x += 8; SPRITES[1].x += 8; SPRITES[2].x += 8; SPRITES[3].x += 8; OAMADDR = 0; OAMDMA = 0x07; // transferencia DMA
Así es cómo se ve el juego en una NES real:


Todo el código está disponible en la sección soft.
[ añadir comentario ] ( 760 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 2.9 / 991 )Tras estudiar, en la anterior entrega, el desarrollo en la consola Sega Master System, le toca el turno ahora a la Sega Mega Drive. La consola de cuarta generación de Sega salió entre 1988 y 1990 y fue la primera consola de 16 bits de Sega, compitiendo con la SNES de Nintendo. La Mega Drive (conocida en EEUU como Sega Genesis) incluye un procesador Motorola 68000 (bus de 16 bits y registros de 32 bits) y un coprocesador Z80 dedicado para el sonido. El VDP es mucho más potente que su predecesora, la Master System (más colores, scroll vertical y horizontal, varios planos, mayor cantidad de sprites, etc.), e incluye, además del PSG, un chip de sonido con síntesis FM y un canal de sonido muestreado.
Breve repaso a la arquitectura de la Sega Mega Drive
La Sega Mega Drive tiene, como procesador principal, un 68000 de Motorola (la consola disponen también de un procesador Z80 auxiliar destinado al procesamiento de sonido que se verá más adelante). El 68000 dispone de un bus de direcciones de 24 bits, que le permite direccionar un total de 16 Mbytes de memoria distribuidos de la siguiente manera.
Mapa de memoria
| Inicio | Fin | Descripción |
| 0x000000 | 0x3FFFFF | ROM y RAM del cartucho (4 Mbytes) |
| 0x400000 | 0x9FFFFF | Espacio reservado para Mega-CD y 32X |
| 0xA00000 | 0xA0FFFF | RAM: Espacio de memoria del Z80 (YM2612 y PSG) |
| 0xA10000 | 0xBFFFFF | E/S y reservado |
| 0xC00000 | 0xC0000F | VDP |
| 0xFF0000 | 0xFFFFFF | RAM de trabajo del 68000 (64 Kbytes) |
Esta tabla es una simplificación para facilitar la comprensión del tema. Una versión más exhaustiva del mapa de memoria puede encontrarse aquí.
El espacio de memoria que está entre 0xA00000 y 0xA0FFFF (desde el punto de vista del 68000) se corresponde con todo el espacio de memoria del procesador Z80 (0x0000 a 0xFFFF). Es una memoria RAM compartida entre ambos procesadores pero no accesible de forma simultánea por ambos. Cuando veamos la parte de la interacción entre el 68000 y el coprocesador Z80 se explicará este tema con más detalle.
Interrupciones
El 68000 dispone de múltiples fuentes de interrupción, pero en el caso de la Sega Mega Drive, la cantidad de fuentes de interrupción se limita a 3:
- Interrupción externa: provocada por accesorios externos (pistola óptica, por ejemplo).
- Interrupción de H Blank: generada cuando se pinta una línea concreta de la pantalla (configurable en los registros del VDP).
- Interrupción de V Blank: generada en cada retrazo vertical (después de que se pinte cada frame de pantalla).
Mapa de memoria del cartucho
Los 4 Mbytes de la ROM y la RAM del cartucho se disfribuyen de la siguiente manera:
| Inicio | Tamaño | Descripción |
| 0x000000 | 4 bytes | Puntero de pila (A7) en el arranque |
| 0x000004 | 4 bytes | Vector de reset (donde empieza la ejecución) |
| 0x000068 | 4 bytes | Puntero a rutina de interrupción externa |
| 0x000070 | 4 bytes | Puntero a rutina de interrupción H Blank |
| 0x000078 | 4 bytes | Puntero a rutina de interrupción V Blank |
| 0x000100 | 256 bytes | Cabecera del cartucho (nombre, checksum, etc.) |
| 0x000200 | 2 Mbytes - 512 bytes | Resto del código del cartucho |
| 0x200000 | 64 Kbytes | SRAM del cartucho (opcional, para guardar partidas) |
| 0x210000 | 2 MBytes - 64 KBytes | Continúa la ROM del cartucho |
La localización y el tamaño de la RAM del cartucho es arbitraria y puede alojarse en cualquier parte entre 0x000000 y 0x3FFFFF. Es en la cabecera del cartucho (0x000100) donde se indica dónde se encuentra, en caso de haberla, la SRAM del cartucho para almacenar las partidas guardadas.
En la cabecera (los 256 bytes alojados en 0x000100) se indica el nombre del juego, fabricante, distribuidor, las zonas compatibles (Japón, EE.UU., Europa, etc.), mandos compatibles, checksum, etc.
Compilar la toolchain para Motorola 68000
La toolchain estándar de GNU (binutils + gcc) junto con la newlib pueden ser compilados para el target "m68k-none-elf" siguiendo los pasos estándar:
binutils
mkdir -p /opt/baremetalm68k/src
cd /opt/baremetalm68k/src
wget https://ftp.gnu.org/gnu/binutils/binutils-2.44.tar.xz
tar xf binutils-2.44.tar.xz
mkdir -p /opt/baremetalm68k/build/binutils-2.44
cd /opt/baremetalm68k/build/binutils-2.44
../../src/binutils-2.44/configure --prefix=/opt/baremetalm68k --target=m68k-none-elf --disable-nls
make
make install
gcc (fase 1)
cd /opt/baremetalm68k/src
wget https://ftp.gnu.org/gnu/gcc/gcc-15.1.0/gcc-15.1.0.tar.xz
wget https://ftp.gnu.org/gnu/gmp/gmp-6.3.0.tar.xz
wget https://ftp.gnu.org/gnu/mpc/mpc-1.3.1.tar.gz
wget https://ftp.gnu.org/gnu/mpfr/mpfr-4.2.2.tar.xz
tar xf gcc-15.1.0.tar.xz
tar xf gmp-6.3.0.tar.xz
tar xf mpc-1.3.1.tar.gz
tar xf mpfr-4.2.2.tar.xz
mv gmp-6.3.0 gcc-15.1.0/gmp
mv mpc-1.3.1 gcc-15.1.0/mpc
mv mpfr-4.2.2 gcc-15.1.0/mpfr
mkdir -p /opt/baremetalm68k/build/gcc-15.1.0-stage-1
cd /opt/baremetalm68k/build/gcc-15.1.0-stage-1
export PATH=/opt/baremetalm68k/bin:${PATH}
../../src/gcc-15.1.0/configure --prefix=/opt/baremetalm68k --target=m68k-none-elf --enable-languages=c --without-headers --disable-nls --disable-threads --disable-shared --disable-libssp --with-newlib
make all-gcc all-target-libgcc
make install-gcc install-target-libgcc
newlib
cd /opt/baremetalm68k/src
git clone https://sourceware.org/git/newlib-cygwin.git
mkdir -p /opt/baremetalm68k/build/newlib
cd /opt/baremetalm68k/build/newlib
../../src/newlib-cygwin/configure --prefix=/opt/baremetalm68k --target=m68k-none-elf
make
make install
En la última versión de newlib utilizada en el momento de realizar este proyecto se produjeron algunos errores de compilación derivados de la falta de definición de varias de las primitivas ("stat", "open", etc.). Como no haremos uso de dichas características de la newlib, me limité a crear "stubs" (funciones vacías) para dichas primitivas, con lo que se consigue compilar la newlib y, a su vez, poder compilar también la STL para C++. De todas formas en los proyectos realizados no se hace uso de la STL.
gcc (fase 2)
mkdir -p /opt/baremetalm68k/build/gcc-15.1.0-stage-2
cd /opt/baremetalm68k/build/gcc-15.1.0-stage-2
../../src/gcc-15.1.0/configure --prefix=/opt/baremetalm68k --target=m68k-none-elf --enable-languages=c,c++ --disable-nls --disable-threads --disable-shared --disable-libssp --with-newlib --with-headers=../../src/newlib-cygwin/newlib/libc/include
make
make install
Ahora ya tenemos en /opt/baremetalm68k/bin el GCC para el target 68000.
Generación de código y linker script
Teniendo el cuenta el mapa de memoria de la Mega Drive, puede hacerse un linker script que incluya las secciones de interrupciones (externa, H Blank y V Blank), así como la cabecera que permite identificar la ROM como una ROM de Sega Mega Drive.
SECTIONS {
. = 0x000000 ;
.vectors : {
LONG(0x01000000); /* stack pointer at end or work RAM */
LONG(0x00000200); /* reset vector at 0x200 */
}
. = 0x000068 ;
.level2_autovector : {
LONG(EXT_ISR_ADDRESS);
}
. = 0x000070 ;
.level4_autovector : {
LONG(H_BLANK_ISR_ADDRESS);
}
. = 0x000078 ;
.level6_autovector : {
LONG(V_BLANK_ISR_ADDRESS);
}
. = 0x000100 ;
.header : {
KEEP(header.o (.header))
}
. = 0x000200 ;
.text : { /* all the code here */
_linker_code = . ;
KEEP(startup.o (.startup))
KEEP(*(.text))
KEEP(*(.text.*))
KEEP(*(.gnu.linkonce.t*))
KEEP(*(.gnu.linkonce.r*))
KEEP(*(.rodata*))
KEEP(*(.got*))
}
. = ALIGN(4);
EXT_ISR_ADDRESS = . ;
.ext_isr : {
KEEP(*(.ext_isr))
}
. = ALIGN(4);
H_BLANK_ISR_ADDRESS = . ;
.h_blank_isr : {
KEEP(*(.h_blank_isr))
}
. = ALIGN(4);
V_BLANK_ISR_ADDRESS = . ;
.v_blank_isr : {
KEEP(*(.v_blank_isr))
}
. = ALIGN(4);
.preinit_array : {
__preinit_array_start = . ;
KEEP(*(.preinit_array))
__preinit_array_end = . ;
}
. = ALIGN(4);
.init_array : {
__init_array_start = . ;
KEEP(*(.init_array))
__init_array_end = . ;
}
. = ALIGN(4);
.fini_array : {
__fini_array_start = . ;
KEEP(*(.fini_array))
__fini_array_end = . ;
}
. = ALIGN(4);
.ctors : {
__CTOR_LIST__ = . ;
LONG((__CTOR_END__ - __CTOR_LIST__) / 2 - 2)
KEEP(*(.ctors))
LONG(0)
__CTOR_END__ = . ;
}
. = ALIGN(4);
.dtors : {
__DTOR_LIST__ = . ;
LONG((__DTOR_END__ - __DTOR_LIST__) / 2 - 2)
KEEP(*(.dtors))
LONG(0)
__DTOR_END__ = . ;
}
. = 0x1F8000 ; /* sound loop right before save ram */
.sound_loop : {
KEEP(*(.sound_loop))
}
_flash_sdata = . ;
. = 0xFF0000 ; /* work RAM starting at 0xFF0000 */
_ram_sdata = . ;
.data : AT (LOADADDR(.dtors) + SIZEOF(.dtors)) {
_linker_data = . ;
*(.data)
*(.data.*)
*(.sdata)
*(.sdata.*)
*(.gnu.linkonce.d*)
}
_ram_edata = . ;
_ram_sbssdata = . ;
.bss : AT (LOADADDR(.data) + SIZEOF(.data)) {
_linker_bss = . ;
*(.bss)
*(.bss.*)
*(.sbss)
*(.sbss.*)
*(.gnu.linkonce.b.*)
*(.COMMON)
}
_ram_ebssdata = . ;
_linker_end = . ;
end = . ;
}
Como se puede ver, toda la ROM se aloja en los primeros 4Mb del cartucho y la RAM en los 64Kb de Work RAM. El puntero de pila se inicializa al final de la Work RAM y el puntero de reset apunta a justo después de la cabecera del cartucho.
Nótese que el puntero de pila se inicializa a 0x010000. La pila en el 68000 (y en la mayoría de las arquitecturas) crece hacia direcciones bajas de memoria, además, la operación de PUSH realiza un pre-decremento del puntero de pila, mientras que la operación POP realiza un post-incremento del puntero de pila. De esta forma la "pila vacía" la implementamos haciendo que el puntero de pila SP (A7) apunte a 0x010000, una dirección inexistente pero que, cuando se pre-decremente (PUSH) sí apuntará una dirección de memoria válida. De esta manera aprovechamos el 100% de la memoria RAM de trabajo que no es muy extensa (sólo tenemos 64 KBytes para las variables globales y para la pila del sistema).
Prueba de concepto
Como primera prueba generaremos la ROM de un cartucho que simplemente inicializará el VPD y la VRAM para poner una imagen estática en pantalla. El VDP de la Mega Drive dispone de varios planos destinados a hacer scroll y efectos (plano B, plano A, Plano Window y los sprites). Cada plano, a su vez tiene un bit de prioridad que permite jugar con las superposiciones de pixels y los efectos.
No me pararé a destallar de forma pormenorizada los detalles de VDP en este sentido, remito al lector a la wiki de Railgun para más información.
El VDP de la Mega Drive, al igual que casitodos los VDPs de la época (tanto de consolas como de ordenadores como el MSX, el Spectrum, etc.) está basado en el concepto de baldosas o "tiles": en una zona de la VRAM se definen las baldosas como agrupaciones de 8x8 pixels (en el caso de la megadrive, cada baldosa ocupa 32 bytes, ya que cada pixel son 4 bits, 16 colores, cada fila de pixels en la baldosa son 4 bytes), mientras que en otra zona de la VRAM se definen los planos, siendo cada plano un conjunto de MxN índices de baldosa (en terminología VDP se suelen llamas las "name tables"). No existe el concepto de "frame buffer" y todo debe ser dibujado a base de baldosas.

(Imagen extraida de un tileset gratuito publicado por al autor Vexed en itch.io)
using namespace std; void ext_isr() __attribute__((interrupt, section(".ext_isr"))); void ext_isr() { // } void h_blank_isr() __attribute__((interrupt, section(".h_blank_isr"))); void h_blank_isr() { // } void v_blank_isr() __attribute__((interrupt, section(".v_blank_isr"))); void v_blank_isr() { // } #define W_VDP_DATA *((uint16_t *) 0xC00000) #define W_VDP_CTRL *((uint16_t *) 0xC00004) #define W_VDP_HV_COUNTER *((uint16_t *) 0xC00008) #define L_VDP_DATA *((uint32_t *) 0xC00000) #define L_VDP_CTRL *((uint32_t *) 0xC00004) #define VDPREG_MODE1 0x8000 // Mode register #1 #define VDPREG_MODE2 0x8100 // Mode register #2 #define VDPREG_PLANEA 0x8200 // Plane A table address #define VDPREG_WINDOW 0x8300 // Window table address #define VDPREG_PLANEB 0x8400 // Plane B table address #define VDPREG_SPRITE 0x8500 // Sprite table address #define VDPREG_BGCOL 0x8700 // Background color #define VDPREG_HRATE 0x8A00 // HBlank interrupt rate #define VDPREG_MODE3 0x8B00 // Mode register #3 #define VDPREG_MODE4 0x8C00 // Mode register #4 #define VDPREG_HSCROLL 0x8D00 // HScroll table address #define VDPREG_INCR 0x8F00 // Autoincrement #define VDPREG_SIZE 0x9000 // Plane A and B size #define VDPREG_WINX 0x9100 // Window X split position #define VDPREG_WINY 0x9200 // Window Y split position #define VDPREG_DMALEN_L 0x9300 // DMA length (low) #define VDPREG_DMALEN_H 0x9400 // DMA length (high) #define VDPREG_DMASRC_L 0x9500 // DMA source (low) #define VDPREG_DMASRC_M 0x9600 // DMA source (mid) #define VDPREG_DMASRC_H 0x9700 // DMA source (high) /* screen width : 40 tiles * 8 = 320 screen height: 28 tiles * 8 = 224 Plane A table : 0xC000 Window name table : 0xD000 Plane B table : 0xE000 Sprite attribute table : 0xF000 H scroll data : 0xF400 */ void vdp_init() { W_VDP_CTRL = VDPREG_MODE1 | 0x04; // mode register #1: display disabled W_VDP_CTRL = VDPREG_MODE2 | 0x04; // mode register #2: display disabled, v blank interrupt disabled, mode 5 video mode, 28 tiles height W_VDP_CTRL = VDPREG_PLANEA | 0x30; // plane A address: upper 3 bits of VRAM location of plane A name table = 0xC000 W_VDP_CTRL = VDPREG_WINDOW | 0x34; // window address: upper 5 bits of VRAM location of window name table = 0xD000 W_VDP_CTRL = VDPREG_PLANEB | 0x07; // plane B address: upper 3 bits of VRAM location of plane B name table = 0xE000 W_VDP_CTRL = VDPREG_SPRITE | 0x78; // sprite address: upper 7 bits of VRAM location of sprite attribute table = 0xF000 W_VDP_CTRL = VDPREG_BGCOL | 0x00; // background color: palette 0, index 0 W_VDP_CTRL = VDPREG_HRATE | 0xFF; // h blank irq rate: horizontal line at wich the h blank interrupt will be triggered W_VDP_CTRL = VDPREG_MODE3 | 0x00; // mode register #3: external interrupt disabled, entire panel vertical scroll, entire panel horizontal scroll W_VDP_CTRL = VDPREG_MODE4 | 0x81; // mode register #4: 40 tiles width, no interlaced mode W_VDP_CTRL = VDPREG_HSCROLL | 0x3D; // H scroll address: upper 6 bits of VRAM location of horizontal scroll table = 0xF400 W_VDP_CTRL = VDPREG_INCR | 0x02; // autoincrement: 2 (each VRAM data write will autoincrement VRAM pointer by 2, one 16 bit word at once) W_VDP_CTRL = VDPREG_SIZE | 0x00; // tilemap size: 32x32 tiles for both A and B planes W_VDP_CTRL = VDPREG_WINX | 0x00; // window x split: window plane x = 0 W_VDP_CTRL = VDPREG_WINY | 0x00; // window y split: window plane y = 0 // clear vram L_VDP_CTRL = 0x40000000; uint16_t n = 65536 >> 1; while (n > 0) { W_VDP_DATA = 0; n--; } // clear cram L_VDP_CTRL = 0xC0000000; n = 128 >> 1; while (n > 0) { W_VDP_DATA = 0; n--; } // clear vsram L_VDP_CTRL = 0x40000010; n = 80 >> 1; while (n > 0) { W_VDP_DATA = 0; n--; } } void vdp_vram_write(const uint16_t *src, uint16_t size_bytes, uint16_t vram_addr) { uint16_t test = W_VDP_CTRL; // prepare vdp L_VDP_CTRL = 0x40000000 | ((((uint32_t) vram_addr) & 0x3FFF) << 16) | (((uint32_t) vram_addr) >> 14); size_bytes >>= 1; while (size_bytes > 0) { W_VDP_DATA = *src; size_bytes--; src++; } } void vdp_cram_write(const uint16_t *src, uint16_t size_bytes, uint16_t cram_addr) { uint16_t test = W_VDP_CTRL; // prepare vdp L_VDP_CTRL = 0xC0000000 | ((((uint32_t) cram_addr) & 0x3FFF) << 16) | (((uint32_t) cram_addr) >> 14); size_bytes >>= 1; while (size_bytes > 0) { W_VDP_DATA = *src; size_bytes--; src++; } } void vdp_vsram_write(const uint16_t *src, uint16_t size_bytes, uint16_t vsram_addr) { uint16_t test = W_VDP_CTRL; // prepare vdp L_VDP_CTRL = 0x40000010 | ((((uint32_t) vsram_addr) & 0x3FFF) << 16) | (((uint32_t) vsram_addr) >> 14); size_bytes >>= 1; while (size_bytes > 0) { W_VDP_DATA = *src; size_bytes--; src++; } } void vdp_enable(bool v) { uint16_t test = W_VDP_CTRL; // prepare vdp if (v) { W_VDP_CTRL = VDPREG_MODE1 | 0x05; // mode register #1: display enabled W_VDP_CTRL = VDPREG_MODE2 | 0x64; // mode register #2: display enabled, v blank interrupt enabled, mode 5 video mode } else { W_VDP_CTRL = VDPREG_MODE1 | 0x04; // mode register #1: display enabled W_VDP_CTRL = VDPREG_MODE2 | 0x04; // mode register #2: display disabled, v blank interrupt disabled, mode 5 video mode } } void vdp_vram_write_tile_indices() { uint16_t test = W_VDP_CTRL; // prepare vdp uint16_t vram_addr = 0xE000; // draw tiles on plane b with low priority L_VDP_CTRL = 0x40000000 | ((((uint32_t) vram_addr) & 0x3FFF) << 16) | (((uint32_t) vram_addr) >> 14); uint16_t i = 1; // put tiles 1, 2, 3, 4, 5, 6, 7, 8... 1023 and 1024 (tile 0 is full transparent) int16_t n = 32 * 32; while (n > 0) { W_VDP_DATA = i; n--; i++; } } #include "ghg.h" // include "s_tile" constant with all 1024 (32 * 32) tiles int main() { vdp_init(); vdp_cram_write(s_palette, 32, 0); // palette 0 vdp_vram_write((const uint16_t *) s_tiles, 32 * 32 * 8 * 4, 32); // 1st tile at tile index 1 in VRAM (keep tile 0 full transparent) vdp_vram_write_tile_indices(); vdp_enable(true); asm volatile ("move.w #0x2300, %sr"); // enable interrupts while (true) ; return 0; }
Los pasos principales son los siguientes:
- Se inicializa el VDP: resolución de 320x224 pixels (40x28 baldosas) y planos A y B de 32x32 baldosas. Cuando se pinta un plano que es más chico que la pantalla, el pintado "da la vuelta" y vuelve a empezar en cada plano, por lo que se ve como un mosaico en pantalla. La inicialización también llena de ceros la VRAM. La "name table" del plano B se configura para estar en la dirección 0xE000 de la VRAM.
- Se inicializa la paleta: se aloja en una zona de memoria especial del VDP llamada CRAM (Color RAM).
- Se escribe en la VRAM las baldosas: en nuestro caso se precalculan las baldosas a partir de una imagen exportada desde el GIMP (ver código "ghg_256_256.cpp").
- Se escribe en la VRAM la table name: en nuestro caso, como es una imagen estática, se genera simplemente la secuencia 1, 2, 3, 4, 5... etc, hasta llegar a la cantidad de baldosas que se quieren poner (32x32 = 1024). La baldosa con índice 0 se deja intacta con todos los pixels a 0 (transparentes), puesto que la rutina de inicialización de la VRAM deja toda la VRAM a 0.
- Se habilitan las interrupciones: "move.w #0x2300, %sr"
- Nos quedamos en un bucle infinito: Por ahora las rutinas de interrupción externa, H blank y V blank se dejan vacías.

Uso de scroll y sprites
Los planos A y B pueden hacer scroll tanto horizontal como vertical de forma independiente escribiendo en unas zonas de memoria concretas de la VRAM y de la VSRAM. Sin apenas cambiar el código anterior podemos genera un efecto de scroll en el plano B simplemente actualizando el offset de scroll horizontal y vertical en cada interrupción de retrazo vertical (V Blank).
En nuestro caso generamos una lista de offsets verticales y horizontales fija mediante un script:
- Con el script "generate_circ_coords.sh" generamos un .h con un array de offsets que sigen un trayectoria circular.
- En "main.cpp" incluimos dicho .h
- En cada interrupción de V Blank obtenemos un offset de scroll horizontal (que escribimos en la posición adecuada de la VRAM), un offset de scroll vertical (que escribimos en la posición adecuada de la VSRAM) y avanzamos en el array de offsets para que en el siguiente V Blank se cambie el scroll a un nuevo valor. Cuando se llega al final de la lista de offsets se empieza por el principio de nuevo.
#include "circular_scroll_offsets.h" // precalculated circular scroll offsets uint16_t next_circular_scroll_offset; void v_blank_isr() __attribute__((interrupt, section(".v_blank_isr"))); void v_blank_isr() { // update VRAM and VSRAM vdp_vram_write((const uint16_t *) (s_circular_scroll_offsets + next_circular_scroll_offset), 2, 0xF402); // update plane B (background) horizontal scroll vdp_vsram_write((const uint16_t *) (s_circular_scroll_offsets + next_circular_scroll_offset + 1), 2, 2); // update plane B (background) vertical scroll . . . // update scroll offsets for next frame next_circular_scroll_offset += 2; if (next_circular_scroll_offset == (s_circular_scroll_offsets_steps << 1)) next_circular_scroll_offset = 0; }
Por otro lado definimos un sprite sencillo mediante una baldosa de 8x8 pixels:
const uint32_t s_sprite_tile[] __attribute__((aligned(2))) = { 0xFFFFFFFF, 0xF000000F, 0xF0F00F0F, 0xF000000F, 0xF0F00F0F, 0xF00FF00F, 0xF000000F, 0xFFFFFFFF };
Que metemos al final de la lista de baldosas:
int main() { . . . // sprite tile at tile index 1121 in VRAM vdp_vram_write((const uint16_t *) s_sprite_tile, 32, 32 + (32 * 32 * 8 * 4)); . . . }
Definimos la estructura "sprite_attribute_t" que rellenamos para hacer referencia al sprite recién definido:
struct sprite_attribute_t { uint16_t y; uint16_t size_and_link_data; uint16_t pattern; uint16_t x; } __attribute__((packed)); sprite_attribute_t sa __attribute__((aligned(2))); int16_t x; int16_t y; int16_t dx; int16_t dy . . . int main() { . . . sa.x = 128; sa.y = 128; x = y = 0; dx = dy = 1; sa.size_and_link_data = 0; // priority = 0, palette = 0, no vertical flip, no horizontal flip, // pattern = 1025 (pattern 0 = transparent, patterns 1...1024 = plane B) sa.pattern = 1025; . . . }
Y actualizamos sus coordenadas en cada V Blank.
void v_blank_isr() { . . . // first sprite in the sprite attribute table // sprite = 8 bytes, sizeof(sprite_attribute_t) vdp_vram_write((const uint16_t *) &sa, 8, 0xF000); // update sprite position for next frame x += dx; if (x >= (320 - 8)) dx = -1; else if (x <= 0) dx = 1; y += dy; if (y >= (224 - 8)) dy = -1; else if (y <= 0) dy = 1; sa.x = (128 + x) & 0x01FF; sa.y = (128 + y) & 0x03FF; . . . }
Con muy poco código pueden hacerse cosas muy elaboradas:
Uso del Z80 como coprocesador
El Z80 que incluye la Sega Mega Drive tiene dos funcionalidades: actuar como coprocesador para sonido del 68000 en modo Mega Drive o actuar como procesador principal cuando la consola se utiliza en modo de compatibilidad con Master System (se utiliza un accesorio especial que permite insertar cartuchos de SMS en la Mega Drive). En nuestro caso usaremos el Z80 como coprocesador de sonido y liberar al 68000 de ese trabajo.
La memoria del Z80, entre 0x0000 y 0xFFFF se corresponde con las direcciones 0xA00000 y 0xA0FFFF del 68000:
| Inicio | Fin | Descripción |
| 0x0000 | 0x1FFF | RAM principal (8 Kbytes) |
| 0x2000 | 0x3FFF | reservado |
| 0x4000 | 0x4003 | YM2612 (sonido FM y PCM) |
| 0x4004 | 0x5FFF | reservado |
| 0x6000 | 0x6000 | registro de banco |
| 0x6001 | 0x7F10 | reservado |
| 0x7F11 | 0x7F11 | SN76489 (sonido PSG) |
| 0x7F12 | 0x7FFF | reservado |
| 0x8000 | 0xFFFF | banco ROM 68000 |
Como se puede ver, este coprocesador está destinado más bien para controlar el sonido, puesto que tanto el YM2612 como el PSG se encuentran en su espacio de direcciones. En el Z80 se dispara también la interrupción V Blank (a la par que en el 68000).
La zona de memoria entre 0x8000 y 0xFFFF (32 Kbytes) accesible desde el Z80 permite leer desde el Z80 cualquier zona de la ROM del cartucho de la Mega Drive sin intervención del 68000. En la dirección 0x6000, el Z80 escribe (de una forma particular) los 9 bits más significativos del bus de direcciones del 68000 (del A15 al A23) y a continuación el Z80 puede acceder en modo de solo lectura, al banco seleccionado entre 0x8000 y 0xFFFF (32 KBytes).
Iniciar el coprocesador Z80
Para arrancar el coprocesador Z80 de la Mega Drive, lo primero que hay que hacer es copiar el código Z80 que queremos que ejecute en los primeros 8 Kbytes de 0xA00000. Es necesario poner los buses del Z80 en alta impedancia realizando una petición de bus ("bus request") ya que esta zona de la memoria, aunque sea compartida entre el 68000 y el Z80, ambos procesadores no pueden estar accediendo a ella de forma simultánea. En este caso concreto lo que se hace es:
1. Activar el reset del Z80
2. Activar el pin BUSREQ del Z80
3. Liberar el reset del Z80
A partir de ese momento la memoria desde 0xA00000 a 0xA02000 (8 KBytes) es totalmente accesible desde el 68000 (el Z80 ha puesto sus pines de bus en alta impedancia). Dicha memoria debe ser accedida byte a byte (no deben realizarse accesos de 16 ni de 32 bits) por parte del 68000. Lo habitual es este paso es que el código del Z80 se transfiera desde algún tipo de array constante en la zona de memoria de la ROM del cartucho hacia 0xA00000.
Cuando todo el programa del Z80 está cargado se libera el estado de reset del Z80 y se libera el bus por parte del 68000. En ese momento el Z80 empieza a funcionar de forma independiente del 68000 (la zona de memoria desde 0xA00000 a 0xA0FFFF ahora "es del Z80") ejecutando el programa recién transferido (el vector del reset del Z80 es 0x0000, es decir la dirección 0xA00000 desde el punto de vista del 68000).
Comunicación entre el 68000 y el Z80
La única forma de compartir memoria RAM entre el 68000 y el Z80 es utilizando el procedimiento de petición de bus ("bus request") por parte del 68000:
1. Pedir el bus desde el 68000 ("bus request").
2. Esperar a que el Z80 termine de ejecutar la instrucción actual y que active la señal "bus ack".
3. En ese momento el 68000 es "dueño" del bus y puede acceder a cualquier sitio del espacio de direcciones del Z80 (0xA00000 a 0xA0FFFF).
4. El 68000 libera el bus para que el Z80 continue la ejecución por donde iba.
Esta forma de acceso provoca retrasos y ciclos de más en el Z80 que deben ser tenidos en cuenta a la hora de controlar los tiempos de acceso. El Z80 se encarga del sonido y no es desable que la música y los efectos de sonido sufran de retrasos, clicks o underruns.
Una forma alternativa de comunicación permite al Z80 acceder a una zona de la memoria ROM del cartucho del juego sin necesidad de realizar peticiones de bus.
1. El Z80 escribe de una forma particular en la dirección de memoria 0x6000 de su espacio de memoria para indicar los 9 bits más significativos del bus de direcciones del 68000 (líneas A15 a A23).
2. A partir de ese instante, en los 32 KBytes de memoria que van desde 0x8000 a 0xFFFF el Z80 accede al banco de memoria correspondiente en el cartucho ROM del juego (espacio de memoria del 68000).
Sólo se puede elegir una zona de memoria del cartucho que sea ROM, no es posible acceder a ningún tipo de RAM mediante este método. Por ejemplo, si desde el Z80 queremos acceder a la zona de memoria que va desde 0x1F8000 hasta 0x1FFFFF en el cartucho ROM (espacio de memoria del 68000), el Z80 debe indicar en 0x6000 que los bits A23 a A15 son 000111111 y a continuación accediendo a la zona de memoria que va desde 0x8000 a 0xFFFF, el Z80 accederá a los 32 Kbytes del cartucho ROM que van desde 0x1F8000 hasta 0x1FFFFF.
Esta forma de acceso es muy útil cuando el Z80 va a reproducir sonido muestreado o canciones en formato VGM directamente desde la ROM del cartucho, ya que no requiere utilizar el mecanismo de "bus request"/"bus ack" y tanto el 68000 como el Z80 pueden ir a máxima velocidad.
Compilar la toolchain para Z80
Desgraciadamente, para el Z80 no disponemos de toolchain GCC, por lo que no podemos programarlo en C++, pero sí disponemos de toolchain C gracias al proyecto SDCC. Basta con descargar el fuente desde http://sdcc.sourceforge.net y compilar:
cd /ruta/fuente/sdcc
./configure --prefix=/opt/sdcc --disable-pic14-port --disable-pic16-port
make
make install
De esta forma tendremos en /opt/sdcc una toolchain de C operativa para Z80 (y otros procesadores pequeños). El código 68000 podemos hacerlo en C o C++ con GCC mientras que el código Z80 tenemos que hacerlo en C con SDCC.
Todo junto
Crearemos un código para Z80 que lea un buffer de sonido muestreado desde un banco de memoria del cartucho ROM del juego y lo reproduzca de forma indefinida (en bucle). El sonido muestreado lo fijaremos en la posición de memoria 0x1F8000, ocupando como máximo 32 Kbytes (para no tener que estar haciendo conmutación entre bancos de memoria).
El sonido del bucle lo extraemos del banco de muestras libre de regalías samplefocus.com. En concreto descargamos este bucle (creado por ichikabreakcore) del cual extraemos sólo el primer compás. Dicha muestra se ajusta para ocupar 32 Kbytes y se le cambia en formato a mono y 8 bits sin signo por muestra (para que sea compatible directamente con el canal PCM del YM2612). El fichero .raw generado con las muestras en crudo en convertido a fichero ELF para ser enlazado dentro del código de la ROM del cartucho de la Mega Drive (en el linker script del 68000 se fuerza el contenido de este fichero para que sea alojado en la posición 0x1F8000 del cartucho).
SECTIONS {
/* ... */
. = 0x1F8000 ; /* sound loop right before save ram */
.sound_loop : {
KEEP(*(.sound_loop))
}
/* ... */
}
A continuación puede verse cómo queda el código del Z80 (en C, compilable con SDCC) que accede al banco de memoria 0x1F8000 de la ROM del cartucho y reproduce en bucle los bytes de ese banco de memoria.
void vblankISR(void) __critical __interrupt(0) { } void nmISR(void) __critical __interrupt { } #define YM2612_STATUS *((volatile uint8_t *) 0x4000) #define YM2612_A0 *((volatile uint8_t *) 0x4000) #define YM2612_D0 *((volatile uint8_t *) 0x4001) #define YM2612_A1 *((volatile uint8_t *) 0x4002) #define YM2612_D1 *((volatile uint8_t *) 0x4003) #define M68K_BANK_SELECT *((volatile uint8_t *) 0x6000) #define M68K_BANK ((const volatile uint8_t *) 0x8000) #ifndef LOOP_SIZE #error "LOOP_SIZE must be defined" #endif void ym2612_write(uint8_t address, uint8_t value) { while (YM2612_STATUS & 0x80) ; YM2612_A0 = address; YM2612_D0 = value; } uint8_t ym2612_read(uint8_t address) { while (YM2612_STATUS & 0x80) ; YM2612_A0 = address; return YM2612_D0; } void main(void) { __asm__ ("di"); // sound loop at address 0x1F8000 on 68000 memory: A23...A15 = 0001 1111 1xxx xxxx xxxx xxxx M68K_BANK_SELECT = 1; // A15 M68K_BANK_SELECT = 1; M68K_BANK_SELECT = 1; M68K_BANK_SELECT = 1; M68K_BANK_SELECT = 1; M68K_BANK_SELECT = 1; M68K_BANK_SELECT = 0; M68K_BANK_SELECT = 0; M68K_BANK_SELECT = 0; // A23 // enable DAC on YM2612 ym2612_write(0x2B, 0x80); const uint8_t *p = M68K_BANK; uint16_t n = LOOP_SIZE; while (1) { // write sample ym2612_write(0x2A, *p); // next sample p++; n--; if (n == 0) { p = M68K_BANK; n = LOOP_SIZE; } } }
En la carpeta "z80" tenemos un Makefile que compila este código C para Z80 utilizando el compilador SDCC y genera, como salida un fichero "mdz80binary.h". Este fichero "mdz80binary.h" define un array de bytes constante con el código binario (compilado por SDCC) que queremos que ejecute el Z80.
const unsigned char s_z80_binary[] = { 0xf3, 0xed, 0x56, 0xc3, 0x69, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xc3, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xc3, 0x03, 0x02, 0x31, 0x00, 0x20, 0xcd, 0x75, 0x02, 0xfb, 0xcd, 0x24, 0x02, 0xc3, 0x73, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xfb, 0xed, 0x4d, 0xed, 0x45, 0x47, 0x4d, 0x3a, 0x00, 0x40, 0x07, 0x38, 0xfa, 0x21, 0x00, 0x40, 0x70, 0x2e, 0x01, 0x71, 0xc9, 0x4f, 0x3a, 0x00, 0x40, 0x07, 0x38, 0xfa, 0x21, 0x00, 0x40, 0x71, 0x3a, 0x01, 0x40, 0xc9, 0xf3, 0x21, 0x00, 0x60, 0x36, 0x01, 0x36, 0x01, 0x36, 0x01, 0x36, 0x01, 0x36, 0x01, 0x36, 0x01, 0x36, 0x00, 0x36, 0x00, 0x36, 0x00, 0x2e, 0x80, 0x3e, 0x2b, 0xcd, 0x05, 0x02, 0x2e, 0xff, 0x3e, 0x24, 0xcd, 0x05, 0x02, 0x2e, 0x01, 0x3e, 0x25, 0xcd, 0x05, 0x02, 0x2e, 0x10, 0x3e, 0x27, 0xcd, 0x05, 0x02, 0x21, 0x00, 0x80, 0x01, 0x83, 0x6c, 0x7e, 0xe5, 0xc5, 0x6f, 0x3e, 0x2a, 0xcd, 0x05, 0x02, 0xc1, 0xe1, 0x23, 0x0b, 0x78, 0xb1, 0x20, 0xef, 0x21, 0x00, 0x80, 0x01, 0x83, 0x6c, 0x18, 0xe7, 0xc9 }; const unsigned int s_z80_binary_len = 630;
Ese .h (con el código binario del programa del Z80) es, a continuación, incluido por el main.cpp del 68000 (como un array de bytes constante) para ser compilado con el GCC (C++) para 68000:
#include "z80/mdz80binary.h" #define Z80RAM ((uint8_t *) 0xA00000) #define Z80BUSREQ *((uint16_t *) 0xA11100) #define Z80RESET *((uint16_t *) 0xA11200) void z80_init(const uint8_t *code, const uint16_t code_size) { // request z80 bus to load z80 code Z80RESET = 0; Z80BUSREQ = 0x0100; Z80RESET = 0x0100; // copy z80 code const uint8_t *src = code; uint8_t *dst = Z80RAM; uint16_t n = code_size; while (n > 0) { *dst = *src; src++; dst++; n--; } // release bus and reset z80 Z80RESET = 0; for (int i = 0; i < 192; i++) ; Z80RESET = 0x0100; Z80BUSREQ = 0; } int main() { . . . // load and start running z80 code z80_init(s_z80_binary, s_z80_binary_len); . . . }
De esta forma el 68000 se encarga de la parte principal de la gestión de los gráficos y el Z80 de la gestión del sonido de forma concurrente.
Todo el código puede descargarse de la sección soft.
[ añadir comentario ] ( 1261 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3.1 / 1759 )La consola Sega Master System fue una consola de videojuegos de finales de los 80, con un hardware muy de su época: basada en cartuchos, con una cpu Z80, procesador gráfico TMS9918 (derivado de los usados en MSX) y chip de sonido SN76489 (muy de su época: 3 canales de tonos con onda cuadrada más un canal de ruido). A lo largo de este post se desarrollará una pequeña prueba de concepto desde cero en C para genera la ROM de un juego compatible con Sega Master System.
Mapa de memoria y secuencia de arranque
El mapa de memoria de la SMS es muy sencillo, ya que las primeras posiciones de memoria (el vector de reset del Z80 es 0x0000) están en el cartucho, por lo que el cartucho de cada juego es responsable del arranque correcto de la CPU (vector de reset, puntero de pila e interrupciones).
$10000 -----------------------------------------------------------
Paging registers
$FFFC -----------------------------------------------------------
Mirror of RAM at $C000-$DFFF
$E000 -----------------------------------------------------------
8k of on-board RAM (mirrored at $E000-$FFFF)
$C000 -----------------------------------------------------------
16k ROM Page 2, or one of two pages of Cartridge RAM
$8000 -----------------------------------------------------------
16k ROM Page 1
$4000 -----------------------------------------------------------
15k ROM Page 0
$0400 -----------------------------------------------------------
First 1k of ROM Bank 0, never paged out with rest of Page 0
$0000 -----------------------------------------------------------
Aunque la SMS permite paginación de memoria, para ROMs de hasta 32Kb no es necesario y no será tenido en cuenta para este ejemplo. Los puntos clave en una ROM de la SMS son los siguientes:
- Vector de reset en 0x0000 (aquí empieza la ejecución del código)
- En 0x0038 está el vector de interrupción enmascarable: Las interrupciones en la SMS se gestionan con el modo 1 de la CPU, por lo que todas las interrupciones enmascarables (las "normales") van al vector 0x0038. En la SMS se puede configurar el chip gráfico (VDP) para que genere interrupciones cuando se produce un retrazo vertical o cuando se alcance determinada línea horizontal en el pintado.
- En 0x0066 está el vector de interrupción no enmastarable: en el caso de la SMS la interrupción no enmascarable está conectada al botón "pause" de la carcasa de la consola.
- La RAM de la consola empieza en 0xC000 y termina en 0xDFF0.
- En nuestro caso particular, para guardar las partidas, lo habitual es que en cartucho disponga de una RAM no volátil propia a partir de la dirección 0x8000 que se puede mapear en el espacio de direcciones de la CPU configurando unos registros especiales.
- Información sobre el cartucho (su cabecera) se encuentra alojada a partir de la dirección 0x7FF0 de la ROM del cartucho y consta de 16 bytes que indican tipo de ROM, tamaño y una pequeña firma ASCII para identificarla como ROM de SMS.
Aunque formalmente, la RAM termina en 0xDFFF, como dicha RAM tiene un espejo en 0xE000-0xFFFB y las últimas direcciones de memoria 0xFFFC-0xFFFF se usan para el control de la paginación de memoria, se considera que la RAM "termina" antes, en 0xDFF0. Por tanto, como la pila del Z80 crece hacia direcciones bajas de memoria (SP disminuye cuando se hace PUSH y aumenta cuando se hace POP), lo habitual es inicializar el puntero de pila SP a 0xDFF0 y que el compilador coloque las variables globales a partir de 0xC000.
Para la prueba de concepto se utilizará el compilador SDCC que se puede instalar siguiendo las instrucciones indicadas en este post, y que viene acompañado de todos los compiladores y enlazadores necesarios. A continuación se puede ver un típico esqueleto de código de arranque de ROM de Sega Master System en ensamblador:
.module crt0sms
.globl _main
.globl _vblankISR
.globl _nmISR
.area _HEADER (ABS)
.org 0x0000
di
im 1 ; SMS runs in z80 interrupt mode 1
jp init
.org 0x0038
jp _vblankISR
.org 0x0066
jp _nmISR
init:
; init stack pointer
ld sp, #0xDFF0 ; at end of onboard RAM
; init memory mapper
ld hl,#0x0008 ; first page of cartridge RAM at 0x8000
ld (#0xfffc),hl ; [0xfffc] = 0x08, [0xfffd] = 0x00
ld hl,#0x0201
ld (#0xfffe),hl ; [0xfffe] = 0x01, [0xffff] = 0x02
; init global variables
call gsinit
; main function
ei
call _main
inf_loop:
jp inf_loop
; ordering of segments for the linker.
.area _HOME
.area _CODE
.area _INITIALIZER
.area _GSINIT
.area _GSFINAL
.area _CODE
.area _GSINIT
gsinit::
.area _GSFINAL
ret
.area _DATA
.area _INITIALIZED
.area _BSEG
.area _BSS
.area _HEAP
.area _TAIL (ABS)
.org 0x7FF0 ; cartridge "header"
.ascii "TMR SEGA" ; https://www.smspower.org/Development/ROMHeader
.db #0x00, #0x00 ; reserved
.db #0x00, #0x00 ; checksum
.db #0x26, #0x70, #0xA0 ; product code 107026, version 0
.db #0x4C ; SMS export, rom size = 32 Kb
Los pasos para la inicialización son los siguientes:
- Deshabilitar interrupciones
- Poner el modo 1 de interrupciones (vector único en 0x0038).
- Poner el puntero de pila en 0xDFF0
- Configuramos en los registros de paginación (0xFFFC y 0xFFFE) que los primeros 8K de la RAM del cartucho (para guardar partidas) estarán mapeados a partir de la dirección 0x8000.
- Invocamos la función "gsinit", que es proporcionada por el compilador (no la tenemos que escribir nosotros) y es la encargada de inicializar las variables globales que tengamos..
- Invocamos la función "main".
El código anterior asume que se deben definir como mínimo 3 funciones:
void vblankISR(void) __critical __interrupt(0): rutina de servicio de interrupción sólo interrumpible por una interrupción no enmascarable (NMI). En la práctica es una rutina "normal" de interrupción que lo primero que hacer nada más entrar es deshabilitar las interrupciones y volver a habilitarlas antes de salir.
void nmISR(void) __critical __interrupt: rutina de servicio de interrupción no interrumpible y no enmascarable (NMI). Se ejecuta cuando se pulsa en botón "pause" de la consola.
void main(void): el punto de entrada de nuestro código.
Chip gráfico (VDP)
El chip gráfico de la Sega Master System es una versión simplificada del chip gráfico del MSX y sólo soporta un único modo de vídeo. El chip tiene una VRAM (RAM de vídeo) dedicada y separada de la RAM de la CPU. A dicha VRAM se accede mediante operaciones de puerto (instrucciones "in", "out" del Z80). La VRAM está organizada como sigue:
$4000 ---------------------------------------------------------------
Sprite info table: contains x,y and tile number for each sprite
$3F00 ---------------------------------------------------------------
Screen display: 32x28 table of tile numbers/attributes
$3800 ---------------------------------------------------------------
Sprite/tile patterns, 256..447
$2000 ---------------------------------------------------------------
Sprite/tile patterns, 0..255
$0000 ---------------------------------------------------------------
Esta forma de organizar la VRAM no es fija y puede cambiarse escribiendo en registros especiales del VDP aunque es la más habitual en todos los juegos de SMS y la que usaremos para la prueba de concepto.
Lo habitual para asegurarnos de que el VDP está correctamente inicializado es:
- Inicializar sus registros a unos valores por defecto.
- Inicializar toda la VRAM a 0.
A continuación el código utilizado para inicializar el VDP y que se coloca justo antes de llamar "gsinit" (que inicializa las variables globales):
init_vdp_data:
.db #0x04, #0x80, #0x00, #0x81, #0xff, #0x82, #0xff, #0x85, #0xff, #0x86, #0xff, #0x87, #0x00, #0x88, #0x00, #0x89, #0xff, #0x8a
init_vdp_data_end:
...
; init vdp
ld hl, #init_vdp_data
ld b, #init_vdp_data_end - #init_vdp_data
ld c, #0xbf
otir
; clear vram
ld a, #0x00
out (#0xbf), a
ld a, #0x40
out (#0xbf), a
ld bc, #0x4000 ; 16384 bytes of vram
clear_vram_loop:
ld a, #0x00
out (#0xbe), a
dec bc
ld a, b
or c
jp nz, clear_vram_loop
...Para comprender el significado detallado de los datos "init_vdp_data" es mejor recurrir a la documentación del VDP, por ahora nos basta saber que con esos comandos, el VDP queda correctamente inicializado.
Fondo de la pantalla
La imagen en la pantalla de la Sega Master System está compuesta por 32 x 24 baldosas de 8 x 8 pixels cada bandolsa. Cada pixel está definido por 4 bits (máximo 15 colores simultáneos más el color 0 que siempre es transparente o negro). Cada color está definido por una paleta con dos bits por cada componente ("rrggbb").
La forma de definir los colores en las baldosas es algo críptica por la forma en que se definen los bits así que lo mejor es poner un ejemplo. Imaginemos que queremos que una baldosa sea un corazón rojo de bordes blancos y fondo transparente:
color | símbolo | índice en la paleta -------+---------+---------------------- transp | - | 0b0000 (0) rojo | * | 0b0001 (1) blanco | + | 0b0010 (2) -------- -++-++-- +**+**+- +*****+- -+***+-- --+*+--- ---+---- --------
Para este caso, la baldosa quedaría definida de la siguiente manera:
const uint8_t HEART_PATTERN[32] = { // bit // 0 1 2 3 cada byte: msb=pixel más izq, lsb=pixel más derecha 0x00, 0x00, 0x00, 0x00, 0x00, 0x6C, 0x00, 0x00, 0x6C, 0x92, 0x00, 0x00, 0x7C, 0x82, 0x00, 0x00, 0x38, 0x44, 0x00, 0x00, 0x10, 0x28, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };
Cada fila de la baldosa está definida por 4 bytes (total 4 x 8 = 32 bytes por baldosa). Y en cada fila el byte 0 tiene los bits 0 de cada pixel, el byte 1 tiene los bits 1 de cada pixel, el tercer byte 2 los bits 2 de cada pixel y el byte 3 los bits 3 de cada pixel. En el ejemplo anterior, el dibujo sólo utiliza 3 colores (0, 1 y 2), por eso los bytes 2 y 3 están a 0 siempre.
En nuestro caso, a partir de una foto y utilizando el Gimp para aplicar el algoritmo de reducción de paleta Floyd-Steinberg, generamos una imagen de 128 x 120 pixels (16 x 15 baldosas) junto con una paleta reducida de 16 colores.
#include <stdint.h> #include "ana.h" __sfr __at (0xBE) VDP_DATA; __sfr __at (0xBF) VDP_ADDRESS; #define PALETTE_OFFSET_TILES 0 #define PALETTE_OFFSET_SPRITES 16 void write_palette(uint8_t offset, const uint8_t *palette) { VDP_ADDRESS = offset; // start at color 0 VDP_ADDRESS = 0b11000000; uint8_t n = 16; while (n > 0) { VDP_DATA = *palette; palette++; n--; } } void write_vram(const uint8_t *src, uint16_t size, uint16_t vram_addr) { VDP_ADDRESS = (uint8_t) (vram_addr & 0x00FF); VDP_ADDRESS = 0b01000000 | ((uint8_t) ((vram_addr >> 8) & 0x3F)); while (size > 0) { VDP_DATA = *src; src++; size--; } } void write_vram_2(const uint8_t *src, uint16_t size, uint16_t vram_addr) { VDP_ADDRESS = (uint8_t) (vram_addr & 0x00FF); VDP_ADDRESS = 0b01000000 | ((uint8_t) ((vram_addr >> 8) & 0x3F)); while (size > 0) { VDP_DATA = *src; VDP_DATA = 0; src++; size--; } } void vblankISR(void) __critical __interrupt(0) { uint8_t vdp_status = VDP_ADDRESS; } void nmISR(void) __critical __interrupt { } void main(void) { __asm__ ("di"); // draw background image write_palette(PALETTE_OFFSET_TILES, ANA_PALETTE); write_vram(ANA_TILE_PATTERNS, 241 * 4 * 8, 0); // 240 + 1 tile patterns --> vram pattern address (0x0000) write_vram_2(ANA_TILE_MAP, 32 * 24, 0x3800); // 32 * 24 tiles --> vram tile map address (0x3800) // enable display VDP_ADDRESS = 0b01100000; VDP_ADDRESS = 0x81; __asm__ ("ei"); while (1) ; }
Compilamos:
$ /opt/sdcc/bin/sdasz80 -o crt0sms.rel crt0sms.s $ /opt/sdcc/bin/sdcc -mz80 -c -o main.rel main.c $ /opt/sdcc/bin/sdcc -mz80 --data-loc 0xC000 --no-std-crt0 -o main.ihx crt0sms.rel main.rel $ objcopy -I ihex -O binary main.ihx main.sms
Y el fichero "main.sms" podemos ahora ejecutarlo con un simulador o incluso pasarlo a un cartucho flash para ejecutarlo en una Sega Master System real:

Sprites
El formato de baldosas descritp es el que se utiliza tanto para el fondo como para los sprites, con el añadido de que los sprites tienen su propia paleta, que puede ser diferente de la paleta de las baldosas del fondo.
La Sega Master System puede manejar hasta 64 sprites por hardware. La tabla de información de sprites ("sprite info table"), alojada a partir de la dirección 0x3F00 de la VRAM es una tabla de 256 bytes que almacena las coordenadas (x, y) de cada sprite y el número de baldosa que se usará para el sprite. Si asumimos que n = 0 ... 63 (0x00 ... 0x3F) tenemos que, dentro de la VRAM:
- 0x3F00 + n: es la coordenada "y" del sprite (un valor de 208 aquí significa que este es el final de la tabla de sprites y ya no hay más sprites que pintar).
- 0x3F80 + (n x 2): es la coordenada "x" del sprite.
- 0x3F81 + (n x 2): índice de la baldosa (0 a 255).
La VRAM permite definir hasta 512 baldosas distintas y mediante el registro 6 del VDP se configura si el índice del sprite hace referencia a las primeras 256 baldosas o a las últimas 256 baldosas de las 512. En nuestro caso (a través de "init_vdp_data") configuramos este registro para que las baldosas de los sprites sean las últimas 256 de todas las 512.
Interrupción vblank
La interrupción vblank es la parte del código donde habitualmente se realiza la escritura o modificación de los sprites, las baldosas, etc. ya que es en ese momento cuando se está produciendo una pausa entre un cuadra y el siguiente en la pantalla .
En nuestro caso colocaremos ahí un sencillo código que hace moverse al sprite a través de la pantalla rebotando en los bordes.
Código de la parte gráfica
A continuación se ve cómo quedaría todo el código de la parte gráfica (acceso al VDP, a la VRAM y la interrupción vblank):
#include <stdint.h> #include "ana.h" __sfr __at (0xBE) VDP_DATA; __sfr __at (0xBF) VDP_ADDRESS; const uint8_t SPRITE_PALETTE[16] = { // red white 0x00, 0x03, 0x3f, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 }; const uint8_t SPRITE_PATTERN[32] = { // bit // 0 1 2 3 each byte: msb=leftmost pixel, lsb=rightmost pixel 0x00, 0x00, 0x00, 0x00, 0x00, 0x6C, 0x00, 0x00, 0x6C, 0x92, 0x00, 0x00, 0x7C, 0x82, 0x00, 0x00, 0x38, 0x44, 0x00, 0x00, 0x10, 0x28, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 }; #define PALETTE_OFFSET_TILES 0 #define PALETTE_OFFSET_SPRITES 16 void write_palette(uint8_t offset, const uint8_t *palette) { VDP_ADDRESS = offset; // start at color 0 VDP_ADDRESS = 0b11000000; uint8_t n = 16; while (n > 0) { VDP_DATA = *palette; palette++; n--; } } void write_vram(const uint8_t *src, uint16_t size, uint16_t vram_addr) { VDP_ADDRESS = (uint8_t) (vram_addr & 0x00FF); VDP_ADDRESS = 0b01000000 | ((uint8_t) ((vram_addr >> 8) & 0x3F)); while (size > 0) { VDP_DATA = *src; src++; size--; } } void write_vram_2(const uint8_t *src, uint16_t size, uint16_t vram_addr) { VDP_ADDRESS = (uint8_t) (vram_addr & 0x00FF); VDP_ADDRESS = 0b01000000 | ((uint8_t) ((vram_addr >> 8) & 0x3F)); while (size > 0) { VDP_DATA = *src; VDP_DATA = 0; src++; size--; } } uint8_t sprite_x; uint8_t sprite_y; int8_t sprite_x_inc; int8_t sprite_y_inc; void vblankISR(void) __critical __interrupt(0) { uint8_t vdp_status = VDP_ADDRESS; // apply (sprite_x, sprite_y) coordinates to sprite vram VDP_ADDRESS = 0; VDP_ADDRESS = 0b01000000 | 0x3F; VDP_DATA = sprite_y; VDP_ADDRESS = 0x80; VDP_ADDRESS = 0b01000000 | 0x3F; VDP_DATA = sprite_x; // update (sprite_x, sprite_y) sprite_x += sprite_x_inc; if (sprite_x == (256 - 8)) sprite_x_inc = -1; else if (sprite_x == 0) sprite_x_inc = 1; sprite_y += sprite_y_inc; if (sprite_y == (192 - 8)) sprite_y_inc = -1; else if (sprite_y == 0) sprite_y_inc = 1; } void nmISR(void) __critical __interrupt { } void main(void) { __asm__ ("di"); // draw background image write_palette(PALETTE_OFFSET_TILES, ANA_PALETTE); write_vram(ANA_TILE_PATTERNS, 241 * 4 * 8, 0); // 240 + 1 tile patterns --> vram pattern address (0x0000) write_vram_2(ANA_TILE_MAP, 32 * 24, 0x3800); // 32 * 24 tiles --> vram tile map address (0x3800) // draw sprite write_palette(PALETTE_OFFSET_SPRITES, SPRITE_PALETTE); VDP_ADDRESS = 0; // border color = color 0 of sprite palette VDP_ADDRESS = 0x87; write_vram(SPRITE_PATTERN, 4 * 8, 0x2000); // locate sprite sprite_x = 80; sprite_y = 80; sprite_x_inc = 1; sprite_y_inc = 1; VDP_ADDRESS = (uint8_t) (0x3F00 & 0x00FF); VDP_ADDRESS = 0b01000000 | ((uint8_t) ((0x3F00 >> 8) & 0x3F)); VDP_DATA = sprite_y; VDP_DATA = 208; // end of sprite list (sprite_y = 208) VDP_ADDRESS = (uint8_t) (0x3F80 & 0x00FF); VDP_ADDRESS = 0b01000000 | ((uint8_t) ((0x3F80 >> 8) & 0x3F)); VDP_DATA = sprite_x; VDP_DATA = 0; // tile 0 of sprite tiles // enable display VDP_ADDRESS = 0b01100000; VDP_ADDRESS = 0x81; __asm__ ("ei"); while (1) ; }
Chip de sonido (PSG)
El chip de sonido SN76489 es un chip muy sencillo al que se accede mediante escrituras sucesivas en el registro 0x7F (es de sólo escritura) y en la documentación se explicmuy bien cómo se programa. En nuestro caso, para evitar estar "componiendo" o haciendo música desde cero para la prueba de concepto, se ha optado por recurrir al formato de música VGM ("Video Game Music"), documentado aquí y que es muy fácil de leer y de procesar pues es simplemente un volcado de los valores que deben escribirse en el registro del chip junto con comandos de espera.
Se definen dos funciones:
- void vgm_init(vgm_info *vgm, const uint8_t *file_data): que inicializa una estructura "vgm_info" a partir de los datos de una canción en formato VGM.
- void vgm_tick(vgm_info *vgm): que se encarga de escribir los datos en el chip de sonido con la cadencia indicada por la canción VGM. Esta función debe ser invocada en cada vblank del VDP.
typedef struct { const uint8_t *first_byte; const uint8_t *next_byte; uint16_t wait_counter; } vgm_info; void vgm_init(vgm_info *vgm, const uint8_t *file_data) { uint32_t version = *((uint32_t *) (file_data + 0x08)); if (version < 0x00000150) vgm->next_byte = file_data + 0x40; else { uint32_t data_offset = *((uint32_t *) (file_data + 0x34)); if (data_offset == 0x0000000C) vgm->next_byte = file_data + 0x40; else vgm->next_byte = file_data + data_offset + 0x34; } vgm->first_byte = vgm->next_byte; vgm->wait_counter = 0; } void vgm_tick(vgm_info *vgm) { if (vgm->wait_counter > 0) { vgm->wait_counter--; return; } const uint8_t *p = vgm->next_byte; if (*p == 0x50) { vgm->wait_counter = 0; while (*p == 0x50) { p++; PSG = *p; p++; } } while ((*p == 0x61) || (*p == 0x62) || (*p == 0x63)) { if ((*p == 0x62) || (*p == 0x63)) { vgm->wait_counter++; p++; } else { p++; uint16_t num_samples = *((uint16_t *) p); p += 2; //vgm->wait_counter += num_samples / 882; // convert samples to ticks (requires stdlib because of integer division) // // aproximate num_samples / 882 with num_samples / 768 = num_samples / (256 * 3) // (1 / 3) * 65536 = 21845, so: // num_samples / 768 = ((num_samples / 256) * 21845) / 65536 // num_samples / 768 = ((num_samples >> 8) * 21845) >> 16 // num_samples / 768 = (ns * 21845) >> 24 // num_samples / 768 = (ns * (16384 + 4096 + 512 + 256 + 32 + 4)) >> 24 // num_samples / 768 = (ns * (16384 + 4096 + 512 + 256 + 32 + 4)) >> 24 // num_samples / 768 = ((ns << 14) + (ns << 12) + (ns << 8) + (ns << 5) + (ns << 2) + ns) >> 24 uint32_t aux = num_samples; aux = ((aux << 14) + (aux << 12) + (aux << 8) + (aux << 5) + (aux << 2)) >> 24; vgm->wait_counter = aux; } } while ((*p & 0x70) == 0x70) // wait n + 1 samples, 1 tick = 882 samples, so ignore 0x7X commands p++; if (*p == 0x66) { vgm->wait_counter = 0; vgm->next_byte = vgm->first_byte; } else vgm->next_byte = p; }
Como puede verse, desde la función main se invoca "vgm_init" indicando un puntero a los datos VGM a procesar y se invoca "vgm_tick" en cada interrupción vblank. La única parte algo críptica del código de "vgm_tick" es cuando hay que calcular la cantidad de ticks de espera a partir de los samples, pues la fórmula oficial es $\frac{samples}{882}$ para el caso PAL (50 Hz) y $\frac{samples}{735}$ para el caso NTSC (60 Hz).
En nuestro caso se ha optado por buscar un término medio y calcular los ticks de espera mediante la fórmula $\frac{samples}{768}$ (independientemente de que la consola se sea PAL o NTSC). Esta división entera se ha realizado mediante desplazamientos y sumas para evitar tener que usar la división proporcionada por la librería de SDCC (el Z80 no tiene instrucción de división).
Desde vgmrips.net pueden descargarse cientos de canciones en formato VGM para el chip SN76489.
Conclusiones
La Sega Master System es un sistema potente para su época y muy sencillo de programar comparado con la NES y otras consolas de su generación. El formato de baldosas es quizá lo más críptico que tiene pero en cuanto se le coge el truco, no es tan complicado aunque es mejor recurrir a herramientas externas para ayudarnos en las conversiones de datos. Todo el código puede descargarse de la sección soft.
[ añadir comentario ] ( 1149 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 2.9 / 2117 ) Calendario
Calendario




