
Plano z
La herramienta fundamental para el cálculo de filtros digitales es la transformada Z y su plano complejo asociado, denominado "plano z". Se asume que el lector está medianamente familiarizado con la transformada z y no se abordarán los detalles ni las propiedades de la misma.
La transformada z transforma una función, situada en el dominio discreto del tiempo $x[n]$, en otra función, situada en el dominio complejo de z $X(z)$. Esta transformación es equivalente a la transformada de Laplace en el dominio continuo y tiene ambas propiedades similares en cuanto a linealidad y estabilidad. Al igual que la transformada de Laplace, la transformada Z también se utiliza para modelar funciones de transferencia de sistemas, en el caso de la transformada Z, son sistemas discretos.
Es decir, si para un filtro analógico tenemos una función de transferencia $H(s)$, caracterizada principalmente por sus ceros y sus polos, para un filtro digital tendremos también una función de transferencia $H(z)$, caracterizada también por sus ceros y sus polos. Tanto en el caso de Laplace como en el caso Z los ceros determinan para qué tipo de señales el filtro "tiende a cancelar la entrada" y los polos determinan para qué tipo de señales el filtro "tiende a amplificar la entrada" o incluso entrar en resonancia. La regla básica que debe cumplirse en un filtro analógico es que los polos de $H(s)$ nunca deben tener parte real positiva (deben estar siempre localizados en el semiplano izquierdo del plano complejo $s$), mientras que en caso de un filtro digital, los polos de $H(z)$ nunca deben alojarse fuera de la circunferencia unitaria centrada en el origen del plano complejo $z$ (es decir, los polos en un filtro digital deben cumplir que $|z| < 1$).
Diseño de un filtro resonante sencillo
En el plano z no se mapean frecuencias absolutas como en el plano s, sino que se mapean frecuencias "relativas" a la frecuencia de muestreo y a lo largo de la longitud de la circunferencia de radio 1. La frecuencia asociada a un valor complejo del plano z se corresponde con el ángulo (argumento) de dicho valor: un ángulo de 0 radianes se corresponde con un valor en continua (0 Hz) mientras que un valor de $\pi$ radianes se corresponde con la mitad de la frecuencia de muestreo (frecuencia Nyquist). Si, por ejemplo, muestreamos a 44100 Hz, la frecuencia máxima ($\pi$) será de 22050 Hz, mientras que si muestreamos a 8000 Hz la misma frecuencia PI se corresponderá con 4000 Hz.
El diseño básico de filtros digitales es muy sencillo y se resume en cuatro reglas principales:
- Alojar tantos ceros sobre la circunferencia de radio 1 como frecuencias queramos cancelar. Lo importante de cada cero será su ángulo (= frecuencia) con respecto al origen. Por ejemplo si colocamos un cero en en punto $z = 1$, que se corresponde con un ángulo de 0 radianes, nuestro filtro eliminará la componente de continua de la señal.
- Alojar tantos polos DENTRO de la circunferencia de radio 1 ($|z| < 1$) como frecuencias queramos amplificar. En este caso es importante tanto el ángulo (= frecuencia que queremos reforzar) como su magnitud o módulo (= nivel de refuerzo). Si hacemos que la magnitud (el módulo) de un polo sea 1 ($|z| = 1$) el filtro auto-oscilará a esa frecuencia. Por ejemplo, si colocamos un polo en $z = -1$, que se corresponde con un ángulo $\pi$, estaremos reforzando las señales con frecuencia próxima a $\pi$ (= la mitad de la frecuencia de muestreo).
- Los polos y ceros que tengan parte imaginaria diferente de 0 deberán ponerse por pares conjugados para poder trabajar con señales reales (sin componente imaginaria). Por ejemplo, si estamos muestreando a 44100 Hz y queremos cancelar las frecuencias próximas a 11025 Hz (frecuencia ${\pi \over 2}$), debemos colocar DOS polos conjugados: uno en $(0, 1)$, formando un ángulo de 90 grados (${\pi \over 2}$) y otro en $(0, -1)$ (su conjugado).
- Al final lo habitual es también ajustar la ganancia global del filtro (aunque en este caso no lo hemos hecho por simplicidad). Esto se hace habitualmente debido a que a veces los polos meten mucha ganancia en la banda de paso y es necesario escalar la salida antes de emitirla o la entrada antes de procesarla.
Si, por ejemplo, queremos hacer un filtro paso bajo, lo habitual, es poner un cero en $z = -1$ (sobre la circunferencia de radio 1 con ángulo $\pi$) con el objetivo de anular las altas frecuencias y un polo (con su complejo conjugado) cerca de la frecuencia de corte de nuestro filtro. En nuestro caso de estudio, se trata de un filtro resonante sencillo, por lo que definiremos dos ceros: uno en $z = 1$ (0 radianes), y otro en $z = -1$, ($\pi$ radianes). Como queremos una única frecuencia de resonancia, definimos un único polo (junto con su complejo conjugado, por lo que realmente serán dos polos).
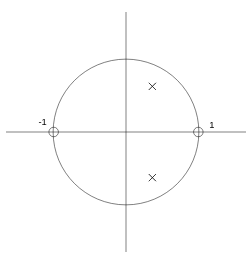
Con esta configuración de dos ceros reales en -1 y 1 y dos polos complejos conjugados en la frecuencia de resonancia tenemos la siguiente función de transferencia en Z:
$$H(z) = {(z + 1)(z - 1) \over (z - p_1)(z - p_1^\prime)}$$
Para la que se cumple que:
$$p_1 = a + bi \;\;\;\;\;\;\;\;\; p_1^\prime = a - bi$$
Desarrollando el denominador (los polos) de $H(z)$ tenemos que:
$$(z - p_1)(z - p_1^\prime) = z(z - p_1^\prime) - p_1(z - p_1^\prime)$$
$$ = z^2 - zp_1^\prime -p_1z + p_1p_1^\prime$$
$$ = z^2 - z(p_1^\prime + p_1) + p_1p_1^\prime$$
$$ = z^2 - z2a + p_1p_1^\prime$$
$$ = z^2 - z2a + a^2 + b^2$$
Nótese que, al ser los polos complejos conjugados, las operaciones
$(p_1^\prime + p_1)$ y $p_1p_1^\prime$ dan como resultado, valores reales (sin componente imaginaria). Por otro lado, si desarrollamos el numerador (los ceros) de $H(z)$ tenemos que:
$$(z + 1)(z - 1) = z(z - 1) + (z - 1)$$
$$ = z^2 - z + z - 1$$
$$ = z^2 - 1$$
Por tanto la función de transferencia $H(z)$ puede reescribirse de la siguiente manera:
$$H(z) = {{z^2 - 1} \over {z^2 - z2a + a^2 + b^2}}$$
Podemos visualizar la respuesta en frecuencia de este sistema asignando a z diferentes valores sobre la circunferencia unitaria $z = e^{iw} = cos(w) + i sen(w)$:
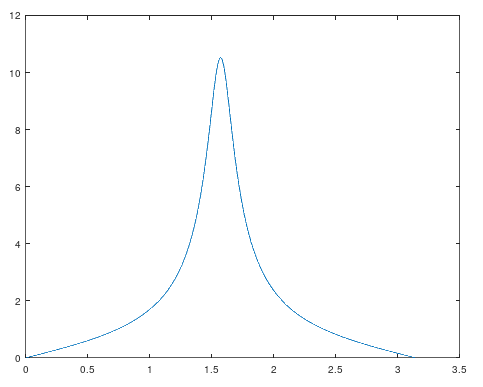
Para generar esta gráfica se ejecutó el siguiente código octave que sitúa el polo (= la frecuencia de resonancia del filtro) en ${\pi \over 2}$:
m = 0.9; w = pi / 2; a = m * cos(w); b = m * sin(w); # respuesta en frecuencia TAM = 1000; responseX = zeros(1, TAM); responseY = zeros(1, TAM); for n = 1:TAM w = (n / TAM) * pi; responseX(n) = w; z = cos(w) + (i * sin(w)); responseY(n) = abs(((z * z) - 1) / ((z * z) - (z * 2 * a) + (a * a) + (b * b))); endfor plot(responseX, responseY);
Implementación del filtro
Ahora que ya tenemos la función de transferencia en el dominio Z del filtro que queremos, el siguiente paso es pasar al dominio discreto y calcular los coeficientes en diferencias finitas para poder implementarlo. Lo primero que se hace es evitar que haya exponentes mayores que 0 para z (exponentes positivos de z se corresponden a muestras "futuras" en el tiempo). Esto se soluciona de forma muy sencilla multiplicando numerador y denominador de $H(z)$ por $z^{-2}$, esto mantiene $H(z)$ igual pero elimina los exponentes positivos:
$$H(z) = {{z^2 - 1} \over {z^2 - z2a + a^2 + b^2}}$$
$$H(z) = {{z^{-2}(z^2 - 1)} \over {z^{-2}(z^2 - z2a + a^2 + b^2)}}$$
$$H(z) = {{1 - z^{-2}} \over {1 - z^{-1}2a + z^{-2}(a^2 + b^2)}}$$
Ahora ya podemos calcular los coeficientes de forma más sencilla. Como $H(z)$ es una función de transferencia en Z tenemos que, si $X(z)$ es la transformada Z de la entrada e $Y(z)$ es la transformada Z de la salida, entonces:
$$Y(z) = H(z) X(z) = {{1 - z^{-2}} \over {1 - z^{-1}2a + z^{-2}(a^2 + b^2)}} X(z)$$
Y, por tanto:
$$Y(z)(1 - z^{-1}2a + z^{-2}(a^2 + b^2)) = X(z)(1 - z^{-2})$$
$$Y(z)-Y(z)z^{-1}2a+Y(z)z^{-2}(a^2 + b^2) = X(z) - X(z)z^{-2}$$
Como la transformada Z es lineal y se cumple que la transformada Z de un valor desplazado k muestras en el tiempo es la siguiente:
$$Z \left\{ x[n - k] \right\} = X(z)z^{-k}$$
Entonces podemos hacer la antitransformada Z de forma sencilla:
$$y[n] - y[n - 1]2a + y[n - 2](a^2 + b^2) = x[n] - x[n - 2]$$
Y, despejando $y[n]$ tenemos que:
$$y[n] = x[n] - x[n - 2] + y[n - 1]2a - y[n - 2](a^2 + b^2)$$
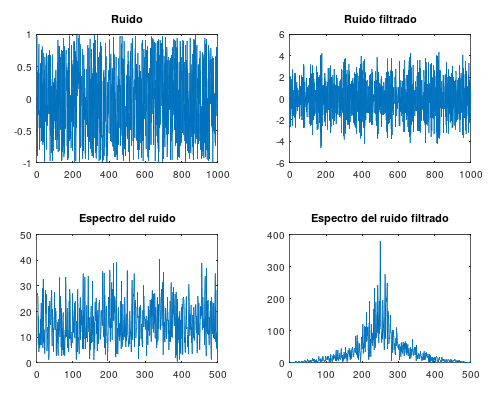
Esto, como se puede ver, es una ecuación en diferencias finitas, que es muy fácil de implementar tanto en hardware como en software. Veamos una ejemplo de código octave que genera ruido blanco y luego lo hace pasar por el filtro (aplica la ecuación en diferencias finitas con los mismos valores a y b, esto es, misma frecuencia de resonancia en ${\pi \over 2}$).
m = 0.9; w = pi / 2; a = m * cos(w); b = m * sin(w); TAM = 1000; input = (rand(1, N) .* 2) .- 1; # TAM valores aleatorios entre -1 y 1 ym1 = 0; ym2 = 0; xm1 = 0; xm2 = 0; output = zeros(1, TAM); for n = 1:TAM output(n) = input(n) - xm2 + (ym1 * 2 * a) - (ym2 * ((a * a) + (b * b))); ym2 = ym1; ym1 = output(n); xm2 = xm1; xm1 = input(n); endfor subplot(2, 2, 1) plot(input); title('Ruido'); subplot(2, 2, 2) plot(output); title('Ruido filtrado'); subplot(2, 2, 3) plot(abs(fft(input)(1:(N / 2)))); title('Espectro del ruido'); subplot(2, 2, 4) plot(abs(fft(output)(1:(N / 2)))); title('Espectro del ruido filtrado');
A continuación se pueden ver las señales y los espectros en frecuencia de las mismas y se puede comprobar como el funcionamiento del filtro es el esperado:
[ añadir comentario ] ( 3129 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |


 ( 3 / 3354 )
( 3 / 3354 )Tradicionalmente, la síntesis y el procesado de sonido digital siempre se ha delegado a nivel hardware en el uso de DSPs. El uso de FPGAs para sustituir DSPs es una tendencia actual derivada del abaratamiento de las FPGAs y de la incursión de las mismas dentro del mundo de la electrónica amateur y DIY. Actualmente una FPGA media tiene suficiente potencia para llevar a cabo múltiples operaciones DSP a una velocidad incluso mayor. El problema con las FPGAs es la forma de programarlas, que requiere un pensamiento abstracto de tipo diferente al razonamiento algorítmico tradicional que se utiliza para programar CPUs y DSPs estándar. Este post se introducirá en el diseño y la implementación de un sintetizador monofónico muy simple sobre una FPGA.
La idea
La idea de esta primera versión es implementar un sintetizador monofónico con un único oscilador de diente de sierra, que sólo lea mensajes de tipo NoteOn y NoteOff y que reproduzca el sonido a través de un DAC I2S.
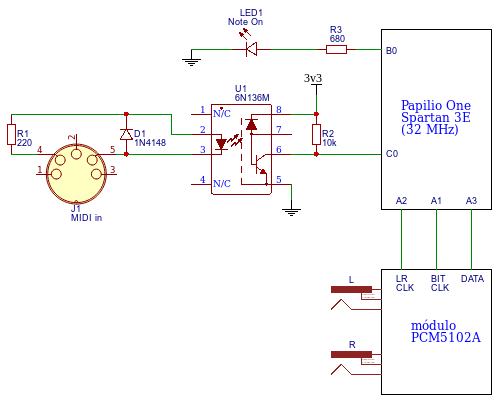
Como se puede apreciar se trata del típico circuito de entrada MIDI con optoacoplador más un PCM5102A como DAC I2S de alta calidad. Los mensajes MIDI de NoteOn se traducen en tonos que genera el oscilador.
El interfaz de salida I2S para el DAC externo
El protocolo I2S es un estándar definido para transportar sonido digital a muy cortas distancias (dentro de una misma placa, por ejemplo). Es estándar de facto en casi la totalidad de los conversores DAC y ADC de alta calidad del mercado de todos los fabricantes y se trata de un protocolo relativamente ligero y fácil de implementar.
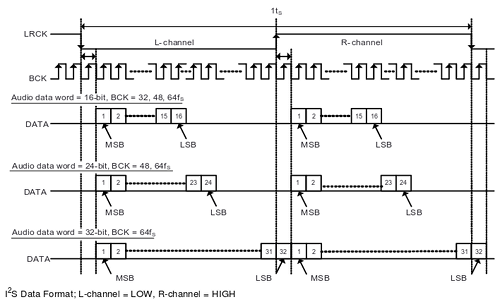
(imagen © Texas Instruments Incorporated, extraida con permiso de la hoja de datos del PCM5102A)
Existe una variante del I2S denominada "Left Justified" que simplifica el uso del reloj LR, evitando el desfase de un bit entre el envío de cada palabra para el canal izquierdo y el canal derecho:
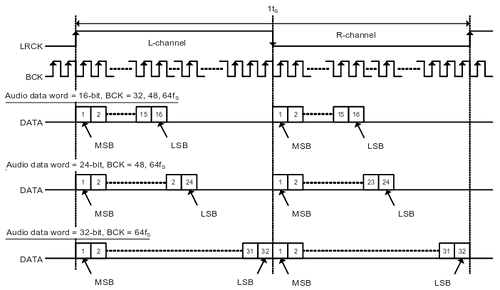
(imagen © Texas Instruments Incorporated, extraida con permiso de la hoja de datos del PCM5102A)
Y que es la variante I2S que se ha usado en este proyecto ya que es más fácil de implementar que el estándar original y actualmente todos los DACs del mercado la soportan. A continuación puede verse lo que sería el diagrama de bloques de la interfaz I2S-LJ dentro de la FPGA:
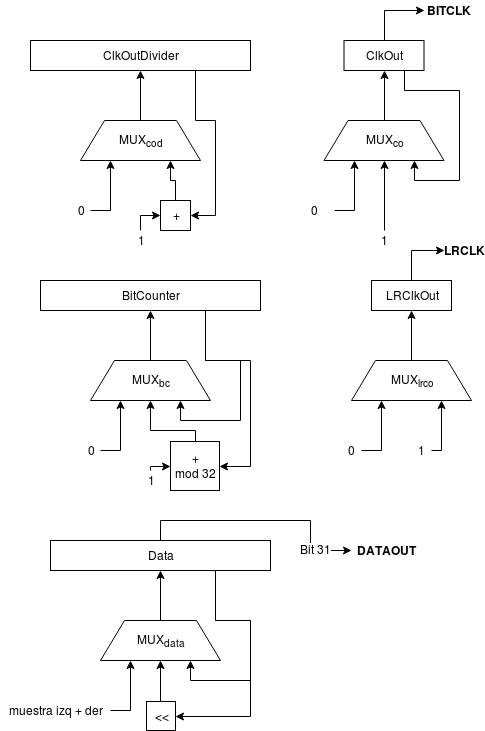
Las diferentes tablas de verdad de cada uno de los bloques combinacionales serían las siguientes:
| Entradas | Salidas | |
|---|---|---|
| ClkOutDivider == 22 | Reset | MUXcod |
| 0 | 0 | + |
| 0 | 1 | 0 |
| 1 | X | 0 |
| Entradas | Salidas | ||
|---|---|---|---|
| ClkOutDivider == 22 | ClkOutDivider == 10 | Reset | MUXco |
| 1 | 0 | 1 | 0 |
| 0 | 1 | 0 | 1 |
| en otro caso | ClkOut | ||
| Entradas | Salidas | |
|---|---|---|
| ClkOutDivider == 22 | Reset | MUXbc |
| X | 1 | 0 |
| 1 | 0 | + mod 32 |
| en otro caso | BitCounter | |
| Entradas | Salidas | |
|---|---|---|
| BitCounter < 16 | Reset | MUXlrco |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | X | 1 |
| Entradas | Salidas | |
|---|---|---|
| ClkOutDivider == 22 | BitCounter == 31 | MUXdata |
| 0 | X | data |
| 1 | 0 | << |
| 1 | 1 | muestra izq + der |
Como se puede apreciar el mecanismo se basa en meter en un registro de desplazamiento de 32 bits las dos palabras de 16 bits de cada canal (izquierdo + derecho) e ir emitiendo bit a bit ese registro cambiando la polaridad de la señal LRCLK cada 16 bits para indicar canal izquierdo o canal derecho.
El oscilador
El oscilador se ha implementado como un sencillo acumulador de fase.
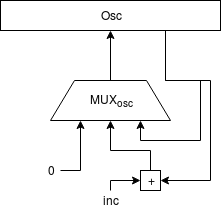
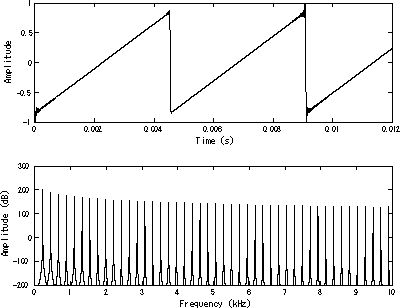
Como lo que se busca es un oscilador de diente de sierra, lo más sencillo es aprovechar el comportamiento natural de cualquier acumulador que, cuando se desborda "da la vuelta". Esto simplifica enormemente todo el diseño ya que, de forma natural, la señal resultante tiene forma de diente de sierra.
(imagen de dominio público extraida de Wikipedia)
Por cada nueva muestra que debe ser calculada, el acumulador es incrementado en una cantidad determinada, lo que provoca que su valor crezca de forma lineal (la rampa del diente de sierra). Al cabo de una cantidad suficiente de muestras, el acumulador se desbordará y "dará la vuelta" empezando de nuevo desde abajo (el "pico" del diente de sierra).
La cantidad que se use para ir incrementando el acumulador de fase determinará la frecuencia de la señal del oscilador:
$$DivisorFrecuenciaRelojI2S = {{32000000 Hz \over 44100 Hz} \over 32 bits}$$
$$inc = {{f \times 65536} \over {{32000000Hz \over DivisorFrecuenciaRelojI2S} \over 32 bits}} \times 65536$$
El incremento (inc) debe estar en formato Q16.16 (punto fijo de 16 bits de parte entera y 16 bits de parte fraccionaria), que es el formato usado por el acumulador de fase del oscilador.
Nótese que el oscilador no se incrementa en cada ciclo de reloj de la FPGA, sino cada vez que se requiere una nueva muestra por parte de la interfaz I2S-LJ para emitirla al DAC.
El parser MIDI
El módulo de procesamiento MIDI se encarga de implementar un receptor UART sencillo a 31250 baudios y una máquina de estados que vaya leyendos los datos MIDI de entrada y determinando en cada momento si hay que reproducir una nota en el oscilador (y con qué frecuencia) o no.
La UART se implementa de forma muy sencilla usando un registro de desplazamiento y un contador para medir el tiempo equivalente a 1.5 bits y a 1 bit.
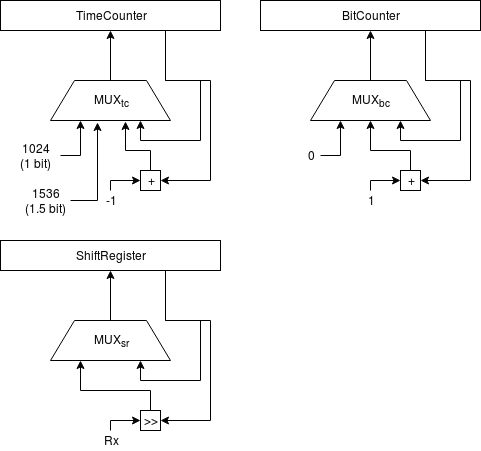
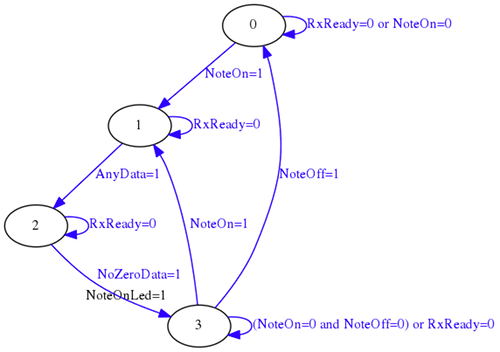
Y usando la siguiente máquina de estados:
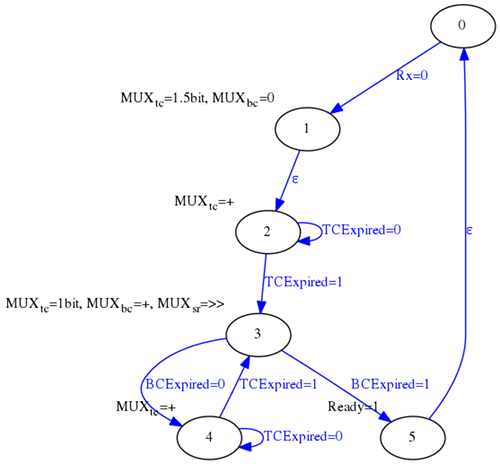
En una entrada anterior de este blog se abordó este proyecto de forma separada. Lo que se ha hecho en este caso ha sido simplificar aquel esquema para que cupiese todo dentro de un único fichero VHDL.
Una vez implementado el receptor UART, el parser MIDI se puede implementar mediante una sencilla máquina de estados que sólo detecte eventos NoteOn y NoteOff.
El parser MIDI en este caso no sólo determina qué nota debe ser reproducida, sino que usando una ROM interna, determina el valor de incremento que debe ser usado por el módulo oscilador para generar el tono correspondiente.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity NotesRom is port ( AddressIn : in std_logic_vector(6 downto 0); DataOut : out std_logic_vector(31 downto 0) ); end entity; architecture RTL of NotesRom is type RomType is array (0 to 127) of std_logic_vector(31 downto 0); constant Data : RomType := ( x"00000000", -- note 0 x"000cdf51", -- note 1 x"000da345", -- note 2 x"000e72df", -- note 3 x"000f4ed1", -- note 4 x"001037d7", -- note 5 x"00112eb9", -- note 6 x"00123449", -- note 7 x"00134966", -- note 8 x"00146efe", -- note 9 x"0015a60b", -- note 10 x"0016ef97", -- note 11 . . . . . . . . . x"368d1251", -- note 122 x"39cb7a59", -- note 123 x"3d3b4348", -- note 124 x"40df5cc9", -- note 125 x"44bae33a", -- note 126 x"48d12253" -- note 127 ); begin DataOut <= Data(to_integer(unsigned(AddressIn))); end architecture;
Para generar este conjunto de valores se hizo un pequeño programa en C++ que convirtió el valor de cada nota MIDI en el valor de incremento correspondiente para que el oscilador emita a esa frecuencia:
#include <iostream> #include <iomanip> #include <stdint.h> #include <math.h> using namespace std; double getFreq(uint8_t midiNote) { const double A4_FREQ = 440; const int32_t A4_MIDI_NOTE = 69; return A4_FREQ * pow(2.0, ((double) (((int32_t) midiNote) - A4_MIDI_NOTE)) / 12.0); } uint32_t getInc(uint8_t midiNote) { const uint32_t CLK_FREQ = 32000000; const uint32_t SAMPLE_RATE = 44100; double freq = getFreq(midiNote); double div = (((double) CLK_FREQ) / SAMPLE_RATE) / 32; double inc = (freq * 65536) / ((CLK_FREQ / div) / 32); uint32_t ret = round(inc * 65536); return ret; } int main() { for (uint8_t n = 0; n < 128; n++) cout << "\t\tx\"" << hex << setw(8) << setfill('0') << getInc(n) << "\", -- note " << dec << setw(0) << setfill(' ') << ((int) n) << endl; return 0; }
Compilando este programa y ejecutándolo, genera en la salida estándar los valores de incremento de todas las 127 notas MIDI posibles:
g++ -c -o notes_rom_generator.o notes_rom_generator.cc
g++ -o notes_rom_generator notes_rom_generator.o
./notes_rom_generator
Todo junto
A la hora de ponerlo todo junto, basta con interconectar los tres bloques:
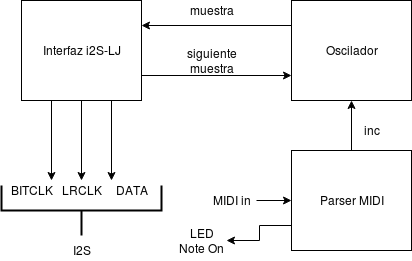
Implementación sobre cualquier FPGA
La implementación se ha desarrollado sobre una Spartan3E de Xilinx a 32 MHz pero el proyecto se puede meter en cualquier FPGA siempre y cuando se ajusten las ecuaciones y las constantes para tener en cuenta las diferentes frecuencias de reloj. En caso de que queramos meter el sintetizador en una FPGA que vaya a otra frecuencia de reloj habría que realizar los siguientes cambios:
1. Las constantes CLK_OUT_DIV y CLK_OUT_DIV_BITS de LJI2SOutput.vhd deben se recalculadas.
2. Las constantes TIME_COUNTER_BITS, TIME_COUNTER_1BIT y TIME_COUNTER_1_5BIT de UartRx.vhd deben ser recalculadas.
3. La constante CLK_FREQ dentro de notes_rom_generator.cc debe ser cambiada, hay que recompilar el programa y colocar la salida generada como los nuevos valores de NotesRom.vhd.
Todo el código fuente puede descargarse de la sección soft.
[ añadir comentario ] ( 3862 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 5359 )Transmitir una señal modulada en FM dentro de la banda de frecuencias de la FM comercial utilizando FPGAs es un tópico ampliamente cubierto en decenas de webs y vídeos online pero que en pocos casos es desgranado y explicado de forma entendible y rigurosa. A lo largo de este post se desarrollará tanto la base teórica como una prueba de concepto de un transmisor FM basado en FPGA.
Los fundamentos
La modulación FM consiste en hacer variar la frecuencia de la señal que estamos mandando a la antena en función de la amplitud de la señal moduladora (sonido, por ejemplo). El rango de frecuencias reservado para emisoras comerciales de audio abarca desde los 87.5 MHz hasta los 108 MHz (es el rango que recoge cualquier receptor FM analógico) con una profundidad de modulación de +- 75 KHz. Esto significa que si queremos emitir en la frecuencia de 100 MHz debemos hacer variar la frecuencia entre 99.925 MHz y 100.075 MHz en función de la amplitud de la señal moduladora.
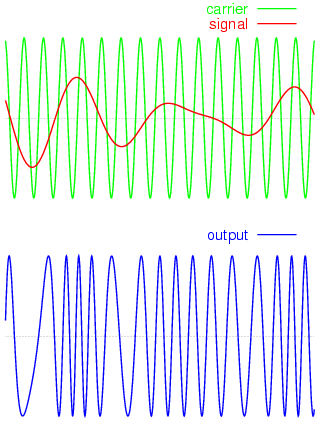
(imagen extraida de Wikipedia, con licencia Creative Commons Attribution - Share Alike 2.0, autor Gvf)
Generar la señal en el dominio digital
Intentar hacer un transmisor FM utilizando una FPGA nos hace chocar, a priori, con un primer impedimento: Poder generar una señal que varíe de frecuencia de una forma tan ligera. Hay que tener en cuenta que con una anchura de modulación de 150 KHz (75 KHz + 75 KHz) y asumiendo una señal sonora muestreada a 16 bits tenemos que la variación de la señal de salida de la antena debe de ser en pasos de:
$${150000 \over {2^{16}}} = {150000 \over 65536} = 2.2888 Hz$$
Esos son muy pocos hercios. En el dominio digital lo habitual para modificar la frecuencia de una señal es multiplicarla por una constante (mediante un PLL) o dividirla entre una constante (mediante un divisor de frecuencias). Los PLLs son circuitos híbridos (entre analógicos y digitales), no son todo lo rápido que nos gustaría (lo normal es que un PLL necesite varios ciclos hasta estabilizarse en la frecuencia deseada), normalmente trabajan con factores constantes (no variables como en nuestro caso) y no están siempre disponibles en las FPGAs para uso directo del usuario. Los divisores de frecuencia son más fáciles de hacer (no dejan de ser baterías de biestables) pero, como su propio nombre indica, sólo son capaces de dividir la frecuencia entre un valor entero.
Acumuladores de fase
Existe, sin embargo, una forma bastante ingeniosa para la síntesis directa de señales digitales sin necesidad del uso de PLLs ni de divisores de frecuencia: los acumuladores de fase. Un acumulador de fase es una de las partes que integran un oscilador digital basado en tabla de ondas. Imaginemos que queremos generar una onda senoidal mediante una tabla de ondas.
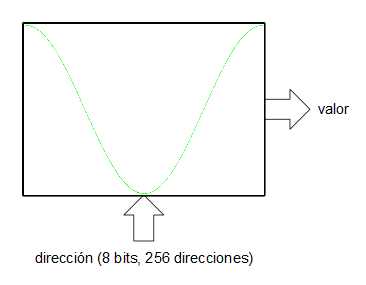
Asumiremos, por simplificar, que la tabla de la onda (realmente sería una ROM o una RAM) tiene un tamaño de 256 muestras ($2^8$). Por otro lado tenemos un registro (al que llamaremos acumulador de fase) de 16 bits y lo que hacemos es indexar la tabla de ondas utilizando los 8 bits más significativos del acumulador de fase. Las entradas D de los biestables de este registro se conectan a la salida un sumador que suma las salidas Q (el valor actual de registro) más un valor de entrada de 16 bits. En cada flanco de subida del reloj del sistema el registro (el acumulador de fase) se carga con el valor de las entradas D procedentes del sumador. En cada tick de reloj el acumulador va acumulando el valor de la entrada de 16 bits.
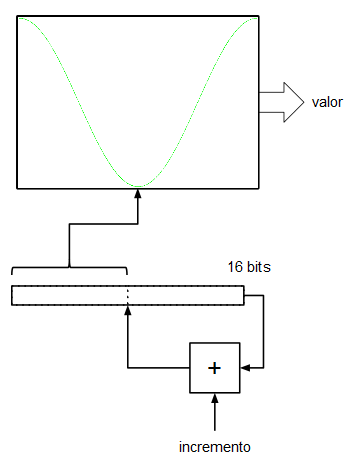
Si en la entrada de 16 bits ponemos un 0, el registro se quedará "quieto", no cambiará su valor y, por tanto la salida de datos de la ROM indexada por dicho registro sacará un valor constante (frecuencia de 0 Hz). Si en la entrada de 16 bits ponemos un 1, en registro se irá incrementando de 1 en 1, sin embargo, como lo que indexa a la tabla de valores son los 8 bits más significativos, este índice sólo avanzará cada 256 pulsos de reloj del sistema. Esto significa que con una frecuencia de reloj de 32 KHz, nuestro oscilador generaría una señal con una frecuencia de:
$${32000 \over 256} = 125 Hz$$
Yéndonos al otro extremo, si en la entrada de 16 bits metemos un valor de $2^{15} = 32768$, el acumulador de fase, al ser de 16 bits, se desbordará cada dos ciclos de reloj: el acumulador de fase generará la secuencia de valores 0, 32768, 0, 32768, 0, 32768, etc. que, a su vez, indexarán los valores mínimo y máximo de la onda senoidal que tenemos en la tabla. Esto significa que la salida del oscilador ha alcanzado su frecuencia máxima (su frecuencia de Nyquist, de 16 KHz).
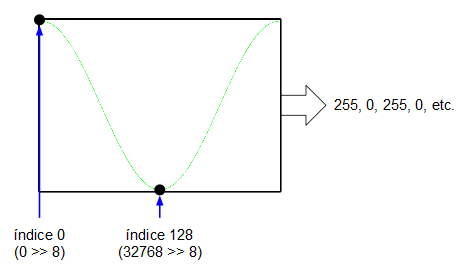
Como se puede comprobar, los incrementos en los pasos son lineales por lo que podemos establecer una especie de regla de tres para el cálculo de la frecuencia de salida de nuestro oscilador imaginario:
$$I_{acumulador fase} = {f_{deseada} \over 32000} \times 2^{16}$$
Vemos que si frecuencia_deseada = 0, entonces incremento_acumulador_fase = 0. Si frecuencia_deseada = 16000 (la frecuencia Nyquist, para 32 KHz), entonces:
$$I_{acumulador fase} = {16000 \over 32000} \times 2^{16} = {1 \over 2} \times 2^{16} = 2^{15} = 32768$$
Para 440 Hz (la nota LA de la cuarta octava del piano) tenemos que:
$$I_{acumulador fase} = {440 \over 32000} \times 2^{16} = 901.12$$
En estos casos, cuando el resultado es fraccionario, hay dos opciones: O quedarse con la parte entera (redondeando o truncando, incremento_acumulador_fase = 901), o, si no queremos perder precisión, incrementar el número de bits para reducir el error. Por ejemplo, utilizando un acumulador de fase de 59 bits conseguiríamos un valor de incremento entero (sin parte fraccionaria):
$$I_{acumulador fase} = {440 \over 32000} \times 2^{59} = 7926335344172073$$
De forma general se puede plantear la ecuación de la siguiente manera:
$$I_{acumulador fase} = {f_{deseada} \over f_{muestreo}} \times 2^{bits}$$
Nótese que la cantidad de bits que indexa la tabla de ondas no es relevante. Lo único importante es que la tabla de ondas está indexada por la parte alta del registro acumulador de fase. Como se puede apreciar, con este método es posible generar frecuencias arbitrarias con pasos relativamente pequeños y sólo limitados por el número de bits que utilicemos en el acumulador de fase.
El transmisor
Imaginemos que la frecuencia de muestreo es ahora de 320 MHz y que queremos generar una frecuencia de 100 MHz. Utilizando un acumulador de fase de 32 bits (la cantidad de bits elegida es arbitraria) tendríamos que:
$$I_{acumulador fase} = {100000000 \over 320000000} \times 2^{32} = 1342177280$$
Como se comentó antes, la cantidad de bits de resolución a la hora de indexar la tabla de ondas no es relevante a efectos de frecuencia (aunque sí a efectos de distorsión armónica y de relación señal/ruido). En nuestro caso, como no disponemos de un DAC sino que vamos a generar una señal cuadrada directamente, en teoría lo que necesitamos es una tabla con una onda cuadrada de tal forma que cuando esté en el máximo emita un 1 y cuando esté en el mínimo emita un 0.
Si asumimos que en la tabla de ondas vamos a meter una onda cuadrada con un ciclo de trabajo del 50% (perfectamente cuadrada), esto significará que la mitad de la tabla de ondas va a estar al valor mínimo (0 por ejemplo) y la otra mitad al valor máximo (255 por ejemplo, si es una ROM de 8 bits sin signo). Si al final vamos a traducir la salida de la tabla de ondas como un 0 si está en el valor mínimo y como un 1 si está en el valor máximo, es obvio que la salida de la tabla de ondas coincidirá con el valor del bit más significativo del acumulador de fase.
Y he aquí la "magia" del invento: Usando un único registro con un sumador podemos hacer un oscilador de onda cuadrada para el que podemos controlar la frecuencia de forma precisa entre 0 Hz y la mitad de la frecuencia de reloj. La precisión a la hora de ajustar la frecuencia nos la dará la cantidad de bits que usemos.
El jittering
Cualquier incremento en el acumulador de fase que no sea potencia de dos va a generar un efecto jitter en la señal de salida haciendo que ésta muchas veces diste de ser una señal cuadrada perfecta. Esto, como es obvio, provocará que la cantidad de armónicos que se generen se dispare. Vamos a verlo con un ejemplo.
Imaginemos el caso anterior: 320 MHz de frecuencia de reloj, un acumulador de fase de 32 bits y un incremento para el acumulador de fase igual a 1342177280. Aplicando este acumulador de fase obtenemos la siguiente salida (correspondiente al bit más significativo):
1 1 0 1 1 0 1 1 0 0 1 0 0 1 0 0 ... la secuencia se repite indefinidamente
Como se puede observar esta secuencia de bits dista mucho de parecerse a una señal cuadrada con ciclo de trabajo del 50%, en concreto genera tres pulsos anchos más juntos y luego dos pulsos estrechos más separados. Sin embargo si hacemos el análisis de Fourier de esta secuencia, tratándola como si fuese una señal, calculándole la transformada de Fourier usando un software numérico como Octave:
octave> abs(fft([1 1 0 1 1 0 1 1 0 0 1 0 0 1 0 0])) ans = 8.00000 1.79995 0.00000 1.01959 0.00000 5.12583 0.00000 1.20269 0.00000 1.20269 0.00000 5.12583 0.00000 1.01959 0.00000 1.79995
Vemos que la transformada de Fourier resultante es efectivamente simétrica (quitando la posición 0, que es la componente de continua), al tratarse de una señal real, y que, descartando la componente de continua (el índice 0 del vector), hay un máximo en el índice 5 del vector. Por las propiedades de la transformada de Fourier en este caso la posición 8 (el centro del vector y el centro de simetría) se corresponde con la frecuencia Nyquist que, al ser la frecuencia de reloj de 320 MHz, sería de 160 MHz (la mitad de la frecuencia del reloj). El máximo situado en la posición 5 del vector se corresponderá, siguiendo una regla de tres, con la frecuencia de:
$${{160000000 \times 5} \over 8} = 100000000 = 100 MHz$$
En efecto, la frecuencia fundamental (el máximo en la transformada de Fourier) de la señal de salida es de 100 MHz, que era nuestro objetivo, aunque como se puede ver en el análisis de Fourier, también se emitirán armónicos de 20 MHz (el valor 1.79995 se corresponde con la frecuencia ${{160 \times 1} \over 8}$), de 60 MHz (${{160 \times 3} \over 8}$) y de 140 MHz (${{160 \times 7} \over 8}$), aunque de menor amplitud.
Implementación y prueba de concepto
Como se va a emitir el sonido por radio FM y aún no disponemos de un ADC que permita la lectura de una fuente externa de audio, se generará la señal de audio dentro de la propia FPGA.
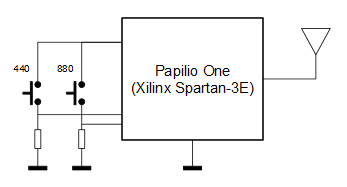
El sistema consta de dos entradas conectadas a sendos botones y que permiten seleccionar la frecuencia del tono a transmitir: cuando no se pulsa ningún botón no se modula (se genera la portadora sin modular), cuando se pulsa el botón 440 la portadora se modula con una señal cuadrada de 440 Hz (nota LA en la cuarta octava del piano), mientras que si se pulsa el botón 880 la portadora se modula con una señal cuadrada de 880 Hz (nota LA en la quinta octava del piano).
La única salida del sistema es la salida de la antena, que va a un trozo de cable que se coloca al aire. No es necesario nada más si vamos a colocar el receptor a pocos metros de la FPGA. En el caso de que queramos conectar la salida a una antena real y que queramos más potencia habría que colocar circuitos acondicionadores y/o amplificadores a la salida y, sobretodo, filtros: hay que recordar que la señal de salida es una onda cuadrada repleta de armónicos.
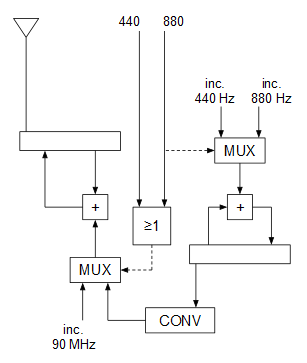
En reposo, las entradas 440 y 880 valen 0, por lo que el MUX inferior selecciona la entrada del incremento correspondiente a los 90 MHz (portadora sin modular). Cuando se pulsa sólo el botón 440 el MUX inferior deja pasar la señal moduladora (ya convertida en secuencias de incrementos en lugar de en 0 y 1) a la entrada del oscilador para modularlo, y cuando se pulsa el botón 880 ocurre lo mismo con el MUX inferior y, además, al cambiar la entrada de selección del MUX superior, cambia el incremento del oscilador que genera la señal moduladora para que genere 880 Hz en lugar de 440 Hz.
El módulo combinacional CONV convierte la entrada de 1 bit (0 o 1) proveniente del oscilador de 440 u 880 Hz, en una salida de 32 bits que es el incremento de fase de correspondiente a cada nivel de la señal moduladora:
0 --> 1341058799
1 --> 1343295761
En este caso se ha realizado una implementación sobre una FPGA Spartan-3E de Xilinx con un reloj externo de 32 MHz (papilio one). Las Spartan-3E disponen de varios DCM (Digital Clock Managers) que permiten subir la frecuencia de reloj mediante multiplicadores. En este caso, con un reloj a 32 MHz la máxima frecuencia que se puede alcanzar es de 288 MHz, por lo que ajustamos los cálculos a dicha frecuencia y asumiendo que vamos a transmitir en la banda de 90 MHz.
$$I_{acumulador fase} = {90000000 \over 288000000} \times 2^{32} = 1342177280$$
Como la señal moduladora (los tonos de 440 y 880 Hz) van a ser también ondas cuadradas, sólo hay que calcular los incrementos para el 0 y el 1 de la señal moduladora (en este caso no hay valores intermedios). El 0 de la señal moduladora lo asociaremos a 89,925 MHz y el 1 de la señal moduladora lo asociaremos a 90,075 MHz (recordemos que la profundidad de modulación en la FM comercial es de 75 KHz).
$$I_{89.925} = {89925000 \over 288000000} \times 2^{32} \approx 1341058799$$
$$I_{90.075} = {90075000 \over 288000000} \times 2^{32} \approx 1343295761$$
A continuación puede verse el código fuente:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity FMTransmitter is port ( Clk : in std_logic; Reset : in std_logic; Button440 : in std_logic; Button880 : in std_logic; AntOut : out std_logic ); end entity; architecture Architecture1 of FMTransmitter is component Oscillator is generic ( NBits : integer := 32 ); port ( IncrementIn : in std_logic_vector(31 downto 0); Clk : in std_logic; Reset : in std_logic; DataOut : out std_logic ); end component; component Mux2Inputs is generic ( NBits : integer := 32 ); port ( Sel : in std_logic; DataIn0 : in std_logic_vector((NBits - 1) downto 0); DataIn1 : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; signal Mux1Out : std_logic_vector(31 downto 0); signal Mux1Sel : std_logic; signal ConvOut : std_logic_vector(31 downto 0); signal ConvIn : std_logic; signal Mux2Out : std_logic_vector(31 downto 0); begin RadioOsc : Oscillator generic map ( NBits => 32 ) port map ( Clk => Clk, Reset => Reset, IncrementIn => Mux1Out, DataOut => AntOut ); Mux1Sel <= Button440 or Button880; Mux1 : Mux2Inputs generic map ( NBits => 32 ) port map ( Sel => Mux1Sel, DataIn0 => std_logic_vector(to_unsigned(1342177280, 32)), -- center freq = 90.0 MHz DataIn1 => ConvOut, DataOut => Mux1Out ); -- center freq - 75 KHz when 0 -- center freq + 75 KHz when 1 ConvOut <= std_logic_vector(to_unsigned(1341058799, 32)) when (ConvIn = '0') else std_logic_vector(to_unsigned(1343295761, 32)); AudioOsc : Oscillator generic map ( NBits => 32 ) port map ( Clk => Clk, Reset => Reset, IncrementIn => Mux2Out, DataOut => ConvIn ); Mux2 : Mux2Inputs generic map ( NBits => 32 ) port map ( Sel => Button880, DataIn0 => std_logic_vector(to_unsigned(6562, 32)), -- 440 Hz DataIn1 => std_logic_vector(to_unsigned(13124, 32)), -- 880 Hz DataOut => Mux2Out ); end architecture;
Tanto el oscilador de salida (el de alta frecuencia) como el oscilador de audio se han implementado usando el mismo componente Oscillator.vhd.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; use ieee.std_logic_signed.all; entity Oscillator is generic ( NBits : integer := 32 ); port ( IncrementIn : in std_logic_vector(31 downto 0); Clk : in std_logic; Reset : in std_logic; DataOut : out std_logic ); end entity; architecture Architecture1 of Oscillator is component Reg is generic ( NBits : integer := 32 ); port ( Enable : in std_logic; Clk : in std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; signal MuxOut : std_logic_vector((NBits - 1) downto 0); signal RegOut : std_logic_vector((NBits - 1) downto 0); begin PhaseAcc : Reg generic map ( NBits => NBits ) port map ( Enable => '1', Clk => Clk, DataIn => MuxOut, DataOut => RegOut ); MuxOut <= (others => '0') when (Reset = '1') else (RegOut + IncrementIn); DataOut <= RegOut(NBits - 1); end architecture;
El tipo de sumador
En otros proyectos FPGA anteriormente abordados en este blog, cada vez que hacía falta un sumador se tiraba de un sumador estándar implementado mediante lógica combinatoria (Adder.vhd). Hasta ahora se ha hecho así por razones pedagógicas. En este caso, sin embargo, al estar el reloj a una frecuencia extremadamente alta para la FGPA ha sido necesario el uso del operador +. Este operador garantiza la mejor implementación de la suma para la plataforma y esto se traduce, en el caso del Spartan-3E y en el caso de la mayoría de las FPGAs existentes, en que se va a hacer uso de sumadores que ya se encuentran integrados (hardwired) en el sustrato de todas las FPGA (todos los fabricantes los incluyen, de mayor o menor cantidad de bits).
¿Qué ventajas tienen estos sumadores con respecto al sumador que hemos estado usando hasta ahora? La principal diferencia es que en nuestro Adder.vhd el acarreo es en cascada, mientras que los sumadores implementados a fuego en las FPGAs están basados siempre en circuitos CLA (Carry Look Ahead), que permiten precalcular los acarreos de cada bit sin necesidad de que estén calculados los bits anteriores. Aún siendo circuitos combinacionales tanto los unos como los otros, el tiempo de propagación del resultado en el caso de sumadores con CLA es mucho menor que en el caso de sumadores con acarreo en cascada (como el Adder.vhd que hemos usado hasta ahora en los proyectos).
En nuestro caso concreto se da además la circunstancia que, con un reloj a 288 MHz, el sumador con acarreo en cascada (el Adder.vhd de siempre) da problemas de timing o, lo que es lo mismo, no le da tiempo de sumar tan rápido y no queda otra opción que tirar del operador + (cosa que, por otro lado, es lo recomendable ya que se garantiza siempre la mejor implementación).
Vídeo
A continuación un pequeño fragmento de vídeo donde se puede ver y escuchar el invento en funcionamiento. La calidad del audio es bastante baja: usé mi radio-despertador como receptor, en el receptor del móvil se oye mucho mejor pero no hubiese podido grabarlo :-)
Espero que haya resultado interesante. Todo el código fuente se puede descargar de la sección soft.
[ añadir comentario ] ( 3879 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 6686 )Aprovechando el post anterior en el que se usaba el DAC de la placa Teensy 3.1 para generar un bucle sonido, he ido un poco más allá y he implementado un pequeño sintetizador monofónico de modelado analógico. La secuenciación es por ahora interna (en una siguiente iteración, se le incorporará una entrada MIDI) e incluye un oscilador de onda en diente de sierra o cuadrada, un filtro de estado variable configurable como paso bajo, paso banda, paso alto y elimina-banda, una envolvente para la frecuencia de corte del filtro y una envolvente para la amplitud.
Punto de partida
En este post anterior se diseñó e implementó un reproductor de sonido para el Teensy que almacenaba un bucle en la memoria flash del microcontrolador. Se utilizó el DAC de 12 bits que viene de serie con el microcontrolador MK20 del Teensy y para el envío de muestras a dicho DAC se usó la interrupción periódica Systick, que traen de serie todos los microcontroladores ARM Cortex-M, ajustada a la frecuencia de muestreo.
void systick() __attribute__ ((section(".systick"))); void systick() { DACDAT = next sample } int main() { // configure DAC SIM_SCGC2 |= (1 << 12); // enable DAC clock generator DAC0_C1 = 0x00; // disable DAC DMA DAC0_C0 = 0xC0; // enable DAC for VREF2 (3.3v) // configure SYSTICK SYST_RVR = F_CPU / SAMPLE_RATE; SYST_CVR = 0; SYST_CSR |= 0x07; while (1) ; }
Objetivo
El objetivo planteado en este caso era implementar un pequeño sintetizador monofónico partiendo de ese mismo modelo (interrupción Systick + DAC). Los bloques planteados para el mini sintetizador son los siguientes:
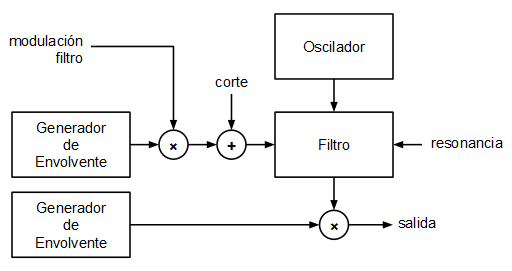
El oscilador
Se ha planteado un oscilador muy sencillo basado en tabla de ondas. Un oscilador basado en tabla de ondas consiste en uno o varios arrays con los valores de la onda que queremos generar, en cada array se guarda un único ciclo de onda y el oscilador lo que hace para emitir tonos a diferente frecuencia es recorrer dicha tabla a diferentes velocidades dando la vuelta cuando llega al final:
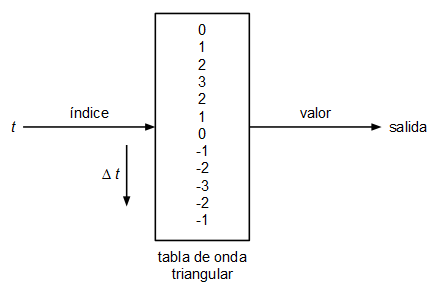
El tamaño de la tabla de ondas vendrá determinado por la resolución (calidad) que queramos darle y por la frecuencia de muestreo. Imaginemos que tenemos un array con 100 valores de una onda con forma de diente de sierra:
// 100 enteros con signo entre -50 y 49
[-50, -49, -48, -47, ... , 47, 48, 49]
Si la frecuencia de muestreo es de 44100 Hz (la frecuencia de muestreo estándar de calidad CD) y queremos reproducir un tono de 440 Hz (nota LA de la cuarta octava del piano) a partir de esta tabla de ondas el oscilador tendrá que usar un incremento de:
$$\Delta t = {440 \over {44100 \over 100}} = 0.9977324263$$
Esto es, el oscilador tomará la primera muestra de la posición 0 de la tabla, la siguiente muestra la tomará de la posición 0.9977324263, la siguiente de la posición 1.9954648526, y así sucesivamente. Como obviamente se trata de una tabla con posiciones enteras, en cada iteración se coge la muestra más próxima o se interpola.
En este caso se ha optado por usar la muestra en la posición de la parte entera del índice. No es la mejor forma de hacerlo pero sí la más rápida:
| t | índice (parte entera de t) |
|---|---|
| 0 | 0 |
| 0.9977324263 | 0 |
| 1.9954648526 | 1 |
| 2.9931972789 | 2 |
| 3.9909297052 | 3 |
| ... | |
| 99.77324263 | 99 |
| 100.7709750563 | |
| como la tabla mide 100, en este momento se vuelve a empezar, manteniendo la parte fraccionaria | |
| 0.7709750563 | 0 |
| 1.7687074826 | 1 |
| 2.7664399089 | 2 |
| ... | |
Debido a que estamos haciendo la implementación en un procesador sin unidad de coma flotante, se realizan todos los cálculos usando aritmética de punto fijo. El formato elegido es el Q16.16 (16 bits enteros + 16 bits fraccionarios = 32 bits que pueden alojarse en un tipo int32_t). Se definen, además, varias macros para facilitar la comprensión del código:
typedef int32_t fixedpoint_t; #define __FP_INTEGER_BITS 16 #define __FP_FRACTIONAL_BITS 16 #define __TO_FP(a) (((int32_t) (a)) << __FP_FRACTIONAL_BITS) #define __FP_1 (((int32_t) 1) << __FP_FRACTIONAL_BITS) #define __FP_ADD(a, b) (((int32_t) (a)) + ((int32_t) (b))) #define __FP_SUB(a, b) (((int32_t) (a)) - ((int32_t) (b))) #define __FP_MUL(a, b) ((int32_t) ((((int64_t) (a)) * ((int64_t) (b))) >> __FP_FRACTIONAL_BITS)) #define __FP_DIV(a, b) ((int32_t) ((((int64_t) (a)) << __FP_FRACTIONAL_BITS) / ((int64_t) (b))))
El código del método getNextSample del oscilador (el que se invoca para calcular cada muestra) queda, por tanto, como sigue:
fixedpoint_t Oscillator::getNextSample() { if (this->status == STATUS_STOPPED) return 0; else if (this->status == STATUS_STARTED) { fixedpoint_t v = ((fixedpoint_t) Wavetable::VALUES[this->t >> __FP_FRACTIONAL_BITS]); if (this->patch->waveform == OscillatorPatch::WAVEFORM_SQUARE) v = (v > 0) ? __TO_FP(1) : __TO_FP(-1); this->t = __FP_ADD(this->t, this->inc); if (this->t >= Wavetable::SIZE_FP) this->t = __FP_SUB(this->t, Wavetable::SIZE_FP); return v; } else return 0; }
Como se puede ver, el atributo t del objeto es el que se va incrementando y a la hora de determinar qué valor devuelve el método getNextSample() se usa como índice de la tabla simplemente la parte entera de t. Esta decisión no es gratuita e implica que hay que tratar de que los incrementos siempre sean mayores o iguales a 1 para que no se produzcan "escalones" en la señal de salida debido a que se repitan muestras de la tabla: en el ejemplo anterior la primera muestra (t = 0) y la segunda (t = 0.9977324263) serán la misma ya que la parte entera de ambos valores es 0. Para evitar que se produzcan estos escalones se ha optado por incrementar el tamaño de la tabla de ondas.
Si partimos de la base de que la frecuencia del tono es directamente proporcional al incremento de t, se puede buscar un tamaño de tabla tal que, para la frecuencia más baja que se quiera reproducir, se obtenga un incremento de t igual a 1. En efecto, si consideramos que no vamos a reproducir tonos por debajo de los 20 Hz (límite inferior del umbral de audición humano), definiendo las tablas de ondas con un tamaño de
$${44100 \over 20} = 2205 \thinspace muestras$$
Para cualquier tono que queramos reproducir, tendremos siempre un incremento de t mayor o igual a 1. Por otro lado podemos simplificar la ecuación del cálculo del incremento de t:
$$\Delta t = {f_{tono} \over 20}$$
Debido a que el propio cálculo del incremento de t implica una división y las divisiones consumen gran cantidad de recursos en procesadores sin unidad de división (como es el caso del ARM Cortex-M) se ha optado por meter en una tabla los diferentes valores del incremento de t. El índice de dicha tabla es el índice de la nota MIDI (entre 0 y 127).
const fixedpoint_t Wavetable::MIDI_FREQ_INC[128] = { 0, 28384, 30071, 31859, 33754, 35761, 37887, 40140, 42527, 45056 ... 34563955, 36619234, 38796727, 41103701 };
Con esta tabla precalculada sintonizar el oscilador solo requiere una indexación y una asignación:
void Oscillator::noteOn(uint8_t midiKey, uint8_t midiVelocity) { this->inc = Wavetable::MIDI_FREQ_INC[midiKey]; this->status = STATUS_STARTED; }
Generador de envolvente
Se utilizan dos generadores de envolvente independientes. Uno que modula la frecuencia de corte del filtro y otro que modula la amplitud del sonido final, antes de escribirlo en el DAC. El tipo de envolvente más común y el que se ha utilizado en este caso es el tipo ADSR (Attack-Decay-Sustain-Release). Cada envolvente de este tipo posee tres valores característicos: el tiempo de ataque (A), el tiempo de caída (D), el nivel de sostenido (S) y el tiempo de liberación (R). Se puede ver un generador de envolvente como una generador de una señal muy lenta que varía entre 0 y 1.
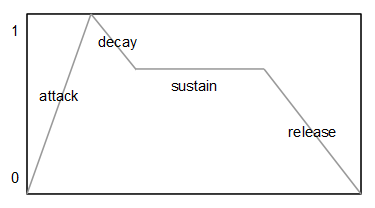
Si se define un nivel de sostenido igual a 0, tenemos una envolvente de tipo AD (Attack-Decay).
Aunque lo más común es definir los parámetro A, D y R en unidades de tiempo (milisegundos, microsegundos), en este caso se ha optado por indicar dichos valores en forma de incrementos, de esta forma no es necesario realizar ninguna multiplicación ni división por cada muestra que se calcula.
fixedpoint_t EnvelopeGenerator::getNextSample() { uint8_t localStatus = this->status; fixedpoint_t ret = 0; do { this->status = localStatus; if (localStatus == STATUS_STOP) ret = 0; else if (localStatus == STATUS_ATTACK) { ret = this->lastSample + this->patch->attackInc; if (ret >= __TO_FP(1)) { ret = __TO_FP(1); localStatus = STATUS_DECAY; } } else if (localStatus == STATUS_DECAY) { ret = this->lastSample - this->patch->decayInc; if (ret <= this->patch->sustainLevel) { ret = this->patch->sustainLevel; if (ret == 0) localStatus = STATUS_STOP; else localStatus = STATUS_SUSTAIN; } } else if (localStatus == STATUS_SUSTAIN) { ret = this->patch->sustainLevel; if (this->noteOffReceived) { this->noteOffReceived = false; localStatus = STATUS_RELEASE; } } else if (localStatus == STATUS_RELEASE) { ret = this->lastSample - this->patch->releaseInc; if (ret <= 0) { ret = 0; localStatus = STATUS_STOP; } } } while (localStatus != this->status); this->lastSample = ret; return __FP_MUL(ret, this->amplitude); }
En la fase de ataque (A) se va incrementando la señal de salida desde 0 hasta 1 en pasos attackInc, en la fase de caída (D) se va decrementando la señal de salida desde 1 hasta el nivel de sostenido en pasos decayInc. Si el nivel de sostenido es 0 la envolvente para al terminar la fase de caída (D), en caso contrario mantiene el nivel de sostenido hasta que se invoca el método noteOff. En ese momento se inicia la fase de liberación (R) decrementando la señal de salida desde el nivel de sostenido hasta 0 en pasos releaseInc.
Filtro
A la hora de implementar un filtro digital existen diferentes aproximaciones: discretización de filtros analógicos conocidos, diseño digital directo usando diagrama de polos y ceros, etc. En este caso se ha optado por una conocida implementación publicada en el libro Musical Applications of Microprocessors de Hal Chamberlin. Se trata de una implementación en digital de un filtro de estado variable que permite extraer señales paso bajo, paso banda, paso alto y elimina banda utilizando muy pocos cálculos.
Dicho filtro viene caracterizado por el siguiente sistema de ecuaciones en diferencias:
$$pasoAlto[n] = entrada - ({r \times pasoBanda[n-1]}) - pasoBajo[n]$$
$$pasoBanda[n] = ({f \times pasoAlto[n]}) + pasoBanda[n - 1]$$
$$pasoBajo[n] = ({f \times pasoBanda[n - 1]}) + pasoBajo[n - 1]$$
Siendo:
$$f = 2\sin\left({\pi F_c \over F_s}\right)$$
$$r = {1 \over Q}$$
Siendo $F_c$ la frecuencia de corte del filtro, $F_s$ la frecuencia de muestreo y $Q$ la Q del filtro (la resonancia).
Si se reordenan las ecuaciones en diferencias:
$$pasoBajo[n] = ({f \times pasoBanda[n - 1]}) + pasoBajo[n - 1]$$
$$pasoAlto[n] = entrada - ({r \times pasoBanda[n - 1]}) - pasoBajo[n]$$
$$pasoBanda[n] = ({f \times pasoAlto[n]}) + pasoBanda[n - 1]$$
Podemos olvidarnos de los índices:
pasoBajo += f * pasoBanda
pasoAlto = entrada - (r * pasoBanda) - pasoBajo
pasoBanda += f * pasoAlto
Como se puede apreciar es preciso mantener en memoria al menos las variables pasoBajo y pasoBanda entre que se procesa una muestra y la siguiente (se trata de un filtro digital de segundo orden).
fixedpoint_t StateVariableFilter::getNextSample(fixedpoint_t input) { this->lowPass = __FP_ADD(this->lowPass, __FP_MUL(this->cutoff, this->bandPass)); fixedpoint_t highPass = __FP_SUB(__FP_SUB(input, this->lowPass), __FP_MUL(this->resonance, this->bandPass)); this->bandPass = __FP_ADD(this->bandPass, __FP_MUL(this->cutoff, highPass)); if (this->mode == MODE_LOWPASS) return this->lowPass; else if (this->mode == MODE_BANDPASS) return this->bandPass; else if (this->mode == MODE_HIGHPASS) return highPass; else if (this->mode == MODE_NOTCH) return __FP_ADD(highPass, this->lowPass); return 0; }
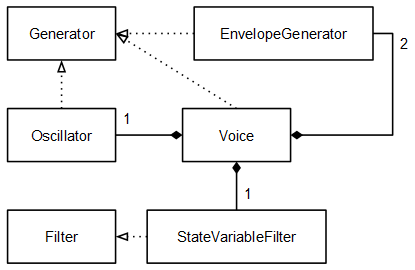
Voz
En la clase Voice juntamos los elementos que se han definido hasta ahora. Esta clase implementa también la interface Generator:
void Voice::noteOn(uint8_t midiKey, uint8_t midiVelocity) { this->oscillator.noteOn(midiKey, midiVelocity); this->ampEnv.noteOn(midiKey, midiVelocity); this->filterEnv.noteOn(midiKey, midiVelocity); } void Voice::noteOff(uint8_t midiKey) { this->oscillator.noteOff(midiKey); this->ampEnv.noteOff(midiKey); this->filterEnv.noteOff(midiKey); } fixedpoint_t Voice::getNextSample() { fixedpoint_t o = this->oscillator.getNextSample(); fixedpoint_t env = __FP_MUL(this->filterEnv.getNextSample(), this->filterEnvMod); fixedpoint_t cutoff = __FP_ADD(env, this->cutoff); if (cutoff < 0) cutoff = 0; else if (cutoff > __TO_FP(1)) cutoff = __TO_FP(1); this->filter.cutoff = cutoff; fixedpoint_t aux = this->filter.getNextSample(o); fixedpoint_t e = this->ampEnv.getNextSample(); return __FP_MUL(aux, e); }
Ahora cada objeto Voice es un sintetizador monofónico. Si en un futuro se quisiese implementar un sintetizador polifónico simplemente habría que instanciar tantos objetos Voice como voces de polifonía se quisieran.
Secuenciador
Aunque en el diagrama inicial no aparece, es fundamental implementar un secuenciador si se quiere probar el sintetizador y no podemos o no queremos pelearnos aún con la implementación de una entrada MIDI. El secuenciador se encarga de disparar notas en determinados instantes de tiempo, en otras palabras, es el objeto que toca el instrumento.
En este caso se ha optado por la implementación de un sencillo secuenciador de 16 pasos equidistantes en semicorcheas. 16 semicorcheas forman un compás de 4 por 4 por lo que toca un único compás. El secuenciador vuelve al empezar cuando llega al final: después de tocar la nota de la semicorchea 15, empieza de nuevo en la semicorchea 0.
void Sequencer::setBPM(uint16_t bpm) { uint32_t stepsPerMinute = bpm * 4; // semicorcheas (pasos de secuenciador) por minuto this->n = (Generator::SAMPLES_MS * ((uint32_t) 60000)) / stepsPerMinute; // muestras por semicorchea }
Como el método run se invoca cada vez que se va a generar una muestra (SAMPLE_RATE veces por segundo) se disparará una nota cada vez que un contador interno llegue a n.
void Sequencer::run() { if (this->status == STATUS_PLAY) { if (this->t == 0) { uint8_t note = this->midiNote[this->nextNoteIndex]; if ((note > 0) && (this->generator != NULL)) this->generator->noteOn(note, 100); this->nextNoteIndex++; if (this->nextNoteIndex == SEQUENCE_SIZE) this->nextNoteIndex = 0; } this->t++; if (this->t == this->n) this->t = 0; } }
Nótese que el secuenciador no envía eventos de tipo noteOff. Esto está hecho así adrede para este caso concreto por simplicidad, y porque las envolventes que se usan tienen siempre el nivel de sostenido a 0 (el sonido se acaba extinguiendo aunque el secuenciador no envíe eventos noteOff). Como la clase Voice implementa la interface Generator, le podemos decir al secuenciador que mande los disparos de nota (noteOn) al objeto de tipo Voice:
Voice v;
Sequencer seq;
...
seq.setBPM(120);
seq.setGenerator(v);
De esta forma ya tenemos adecuadamente inicializado el secuenciador. Ahora sólo falta meter las notas MIDI que queramos que toque. Un valor de nota igual a 0 indica al secuenciador que no queremos disparar ninguna nota en esa semicorchea:
seq.midiNote[0] = 36; // Do 1 seq.midiNote[1] = 24; // Do 0 seq.midiNote[2] = 0; seq.midiNote[3] = 36; // Do 1 seq.midiNote[4] = 39; // Re# 1 seq.midiNote[5] = 0; seq.midiNote[6] = 0; seq.midiNote[7] = 39; // Re# 1 seq.midiNote[8] = 36; // Do 1 seq.midiNote[9] = 24; // Do 0 seq.midiNote[10] = 0; seq.midiNote[11] = 36; // Do 1 seq.midiNote[12] = 39; // Re# 1 seq.midiNote[13] = 0; seq.midiNote[14] = 0; seq.midiNote[15] = 43; // Sol 1 seq.start(); // cambiamos el estado interno del secuenciador a STATUS_PLAY
En este caso se ha metido una sencilla secuencia típica de música electrónica, en la escala de Do menor.
Juntándolo todo
El secuenciador invoca al método noteOn del objeto Voice cada vez que hay una nota nueva que tocar y el valor devuelto por el método getNextSample del objeto de tipo Voice es el que se manda al DAC. La señal debe ser adaptada de fixedpoint_t a entero sin signo de 12 bits (0 - 4095):
void systick() { seq.run(); fixedpoint_t aux = v.getNextSample() >> 1; // evitar clipping uint16_t out; if (aux >= __TO_FP(1)) out = 4095; else if (aux <= __TO_FP(-1)) out = 0; else out = (uint16_t) (((aux + 32768) >> 4) & 0x00000FFF); DACDAT = out; }
Resultados
En la implementación final realizada se ha optado por utilizar una frecuencia de muestreo de 32 KHz. Usar esta frecuencia de muestreo permite generar tonos más precisos ya que 96 MHz no es divisible entre 44.1 KHz pero sí lo es entre 32 KHz (la frecuencia de muestreo es más precisa a 32 KHz que a 44.1 KHz).
A continuación un vídeo en el que puede verse y oirse el invento. No se oye muy alto porque tuve que poner el volumen bajo (era tarde cuando grabé) y encima pasó un camión en ese momento por la calle ¬¬
Todo el código fuente está disponible en la sección soft.
[ añadir comentario ] ( 3152 visualizaciones ) | [ 0 trackbacks ] | enlace permanente | enlace relacionado |
( 3 / 5084 )El procesador ARM Cortex-M4 (Un MK20DX256 de Freescale) incluido en la placa de desarrollo Teensy 3.1 viene equipado con una salida analógica (DAC, no PWM) de 12 bits de resolución con la que es posible generar audio con una calidad razonable y sin apenas hardware externo.
Punto de partida
Se parte del compilador gcc, las binutils y la newlib compilados para el target arm-none-eabi detallados en este post y del trabajo realizado anteriormente en este otro post.
DAC
El DAC del microcontrolador Freescale MK20DX256 tiene una resolución de 12 bits (sin signo) y puede ser utilizado tanto de forma sencilla como mediante DMA. En este caso se va a optar por un uso sencillo sin DMA: La escritura de los datos de las muestras la hará el propio código del programa.
... #define SIM_SCGC2 *((uint32_t *) 0x4004802C) #define DACDAT *((uint16_t *) 0x400CC000) #define DAC0_C0 *((uint8_t *) 0x400CC021) #define DAC0_C1 *((uint8_t *) 0x400CC022) ... SIM_SCGC2 |= (1 << 12); // habilitar el generador de reloj para el DAC DAC0_C1 = 0x00; // deshabilitar el modo DMA para el DAC DAC0_C0 = 0xC0; // habilitar el DAC para VREF2 (3.3v) // a partir de ahora ya se puede escribir en el DAC (DACDAT) ...
Hay que tener en cuenta que el registro DACDAT es un registro de 12 bits sin signo (unsigned).
Systick
La interrupción systick es una de las interrupciones estándar del núcleo ARM Cortex-M4 (de hecho está presente en todos los procesadores ARM Cortex). Se trata de una interrupción que se dispara cuando un contador de 24 bits llega a cero, dicho contador está gobernado por el reloj del núcleo (cuidado, suele ser diferente al reloj del bus) y carece de divisores (es muy simple).
El vector de la interrupción se encuentra en la dirección de memoria 0x0000003C. En esta dirección de memoria debe alojarse la dirección de memoria donde se encuentre la función que se ejecutará cada vez que el systick llegue a cero y vuelva a cargarse (una indirección).
Para implementar esta funcionalidad con el GCC se modifica el linker script (teensy31.ld) para incluir el nuevo vector de interrupción:
...
. = 0x00000000 ;
.cortex_m4_vectors : {
LONG(0x20007FFC);
LONG(0x00000411);
}
. = 0x0000003C ;
.cortex_m4_vector_systick : {
LONG(SYSTICK_ADDRESS + 1);
}
. = 0x00000400 ;
.flash_configuration : {
LONG(0xFFFFFFFF);
LONG(0xFFFFFFFF);
LONG(0xFFFFFFFF);
LONG(0xFFFFFFFE);
}
...
Y para incluir una nueva sección dentro de la memoria de programa con una dirección de memoria prefijada:
...
SYSTICK_ADDRESS = . ;
.systick : {
*(.systick)
}
...
Nótese que la dirección de memoria almacenada en 0x0000003C es la siguiente dirección impar después de SYSTICK_ADDRESS. Esto tiene una explicación y es muy sencilla:
Los procesadores ARM soportan dos repertorios de instrucciones: un repertorio muy amplio y potente en el que cada instrucción ocupa 32 bits (modo arm) y otro repertorio más reducido en el que cada instrucción ocupa 16 bits (modo thumb). El primero es más potente pero ocupa más, mientras que el segundo en menos potente pero ocupa mucho menos. Lo que se puede hacer en modo arm se puede hacer también en modo thumb aunque es posible que para hacer lo que hace una instrucción arm sean necesarias dos o tres instrucciones thumb.
La forma en que un procesador ARM sabe si una instrucción a la que apunta el PC forma parte de un repertorio de instrucciones u otro es mediante el bit 0 del PC. Si el bit 0 vale 0, se trata de una instrucción arm, mientras que si el bit vale 1 se trata de una instrucción thumb (nótese que sea cual sea el modo, todas las instrucciones se encuentran, como mínimo, en direcciones pares, en las direcciones impares nunca hay instrucciones).
Por otro lado según la especificación ARM, las excepciones (interrupciones) se deben ejecutar siempre en modo thumb. De todas formas en este caso no tenemos elección ya que la serie Cortex-M de ARM sólo soporta el repertorio de instrucciones thumb (http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0553a/CHDBIBGJ.html).
Con la nueva sección de código llamada .systick en el código fuente puede ahora definirse la función que va a manejar la interrupción:
... #define SYST_CSR *((uint32_t *) 0xE000E010) #define SYST_RVR *((uint32_t *) 0xE000E014) #define SYST_CVR *((uint32_t *) 0xE000E018) #define SAMPLE_RATE 44100 // indicamos al compilador que queremos alojar el cuerpo de esta función en la sección .systick void systick() __attribute__ ((section(".systick"))); void systick() { // TODO } ... ... // configuramos el systick para que se ejecute SAMPLE_RATE veces por segundo SYST_RVR = F_CPU / SAMPLE_RATE; SYST_CVR = 0; SYST_CSR |= 0x07; ...
F_CPU es la velocidad en Hz del núcleo (en este caso 96 MHz = 96000000 Hz) y hacemos que el systick se ejecute 44100 veces por segundo (la frecuencia de muestreo del sonido a reproducir).
No se debe utilizar el atributo interrupt al declarar la función systick ya que en ese caso el compilador intenta compilarla en modo arm en lugar de thumb.
Sonido
Partiendo de uno de los sonidos (un bucle de bateria) publicado con licencia Creative Commons Attribution-ShareAlike por el usuario de Soundcloud Phantom Hack3r (AKA Loop Studio, https://soundcloud.com/phantom-hack3r) se ha editado, se ha dejado sólo con un único compás (el inicial) y se ha exportado a WAV (drum_loop_1.wav).
A continuación, usando la herramienta de línea de comandos, sox se exporta a su vez este fichero WAV a un formato crudo de 8 bits, mono y sin signo:
sox drum_loop_1.wav -u -b 8 -c 1 -r 44100 drum_loop_1.rawLuego el fichero drum_loop_1.raw se convierte a un fichero objeto para meterlo como si fuese código dentro del microcontrolador:
/opt/teensy/bin/arm-none-eabi-objcopy --input binary --output elf32-littlearm --binary-architecture arm --rename-section .data=.text drum_loop_1.raw drum_loop_1.oLa opción --rename-section .data=.text es muy importante ya que marca los datos generados para que se alojen en la sección .text del fichero de salida. Esta sección es la sección que será alojada en la memoria flash del Teensy.
Ahora en drum_loop_1.o hay definidas dos variables _binary_drum_loop_1_raw_start y _binary_drum_loop_1_raw_end cuya dirección de memoria es el inicio y el final respectivamente de los datos crudos convertidos (drum_loop_1.raw).
Circuito de salida
A la hora de conectar la salida analógica del DAC a unos altavoces hay que hacerlo siempre a través de un amplificador ya que la corriente máxima que soporta la salida DAC es muy baja. De entre todas las opciones de amplificación, la más sencilla es, sin duda, el uso de unos altavoces amplificados de PC (solución sugerida por el propio creador del Teensy, Paul Stoffregen, aquí).
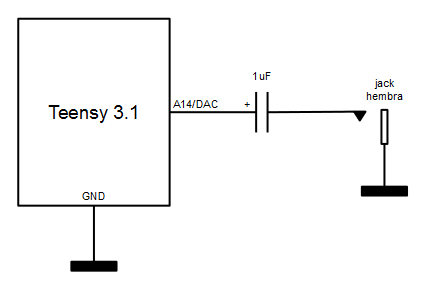
Se trata de un sencillo condensador electrolítico (para el desacoplo de continua) entre la salida del DAC y la entrada del amplificador de altavoces.
Resultado final
El código fuente final de main.cc es el siguiente:
#include <stdint.h> using namespace std; #define SYST_CSR *((uint32_t *) 0xE000E010) #define SYST_RVR *((uint32_t *) 0xE000E014) #define SYST_CVR *((uint32_t *) 0xE000E018) #define SIM_SCGC2 *((uint32_t *) 0x4004802C) #define DACDAT *((uint16_t *) 0x400CC000) #define DAC0_C0 *((uint8_t *) 0x400CC021) #define DAC0_C1 *((uint8_t *) 0x400CC022) #define SAMPLE_RATE 44100 extern char _binary_drum_loop_1_raw_start; extern char _binary_drum_loop_1_raw_end; volatile char *p; void systick() __attribute__ ((section(".systick"))); void systick() { DACDAT = ((uint16_t) *p) << 4; p++; if (p == &_binary_drum_loop_1_raw_end) p = &_binary_drum_loop_1_raw_start; } int main() { // configure DAC SIM_SCGC2 |= (1 << 12); // enable DAC clock generator DAC0_C1 = 0x00; // disable DAC DMA DAC0_C0 = 0xC0; // enable DAC for VREF2 (3.3v) // configure SYSTICK p = &_binary_drum_loop_1_raw_start; SYST_RVR = F_CPU / SAMPLE_RATE; SYST_CVR = 0; SYST_CSR |= 0x07; while (1) ; }
A continuación un vídeo donde puede verse (y oírse) el montaje en funcionamiento.
Todo el código fuente puede descargarse de la sección soft.
[ añadir comentario ] ( 3161 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 17477 ) Calendario
Calendario





{kind=link}
{kind=link}