
Breve introducción al protocolo USB
El protocolo USB es un protocolo serie basado en tramas de paquetes y con una arquitectura muy sencilla. En un bus USB hay un único host, cero o más dispositivos y cero o más hubs. En el protocolo USB es siempre el host el que lleva la voz cantante: un dispositivo nunca envía de forma asíncrona datos a su host, es el host el que interroga al dispositivo si tiene datos para él (esta forma de hacer las cosas, a priori enrevesada, facilita luego mucho la implementación del protocolo).
Cada conexión USB entre un host y un dispositivo está formada por varios endpoints, un endpoint es un canal de comunicación entre el host y el dispositivo y cada dispositivo puede tener hasta 16 endpoints (o canales) de comunicación con el host. Cada endpoint es unidireccional, esto es, cada endpoint debe ser definido como de entrada o de salida (siempre desde el punto de vista del host, IN es dispositivo->host, y OUT es host->dispositivo, siempre, aunque estemos en el contexto del dispositivo).
Hay cuatro tipos de endpoints: de control (estos son especiales y pueden ser bidireccionales), bulk, interrupt e isócronos:
Control: Endpoints usados para configurar el dispositivo.
Bulk: Endpoints para transferencias estándar de datos. No tienen latencia máxima garantizada.
Interrupt: Endpoints destinados a envíos asíncronos. Tienen una latencia máxima fija garantizada.
Isócronos: Endpoints para transferencias con alto ancho de banda, con detección de errores pero sin reintento de envío de paquetes. No se garantiza la entrega de los paquetes.
Cada dispositivo USB tiene una serie de tablas (normalmente alojadas en flash o en ROM) denominadas descriptores, que son transferidas al host en el arranque (mediante un endpoint de control) y que identifican de forma precisa y estándar la funcionalidad y los endpoints disponibles (tipo, dirección, etc.) en el dispositivo.
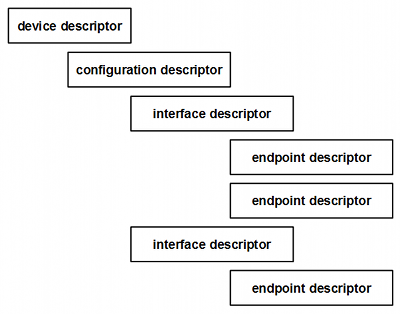
Cada dispositivo tiene un descriptor de dispositivo, dentro de cada descriptor de dispositivo podrá haber diferentes configuraciones (descriptores de configuración), a su vez dentro de cada configuración habrá descriptores de interfaces y dentro de éstos habrá descriptores de endpoints. Lo más habitual es que cada dispositivo sólo tenga un único descriptor de configuración. Hay un descriptor de endpoint por cada endpoint en uso por parte del dispositivo. No existe descriptor para el endpoint 0 ya que es un endpoint que siempre debe estar disponible y sólo puede ser de control.
Inicialización
La secuencia de inicialización es como sigue:
1. Cuando el host detecta un dispositivo conectado a un puerto USB realiza una secuencia de reset sobre dicho puerto.
2. A continuación, el host envía un paquete SETUP a través del endpoint de control 0 con el comando GET_DESCRIPTOR(device)
3. El dispositivo, como respuesta, devuelve su descriptor de dispositivo.
4. El host solicita a través del endpoint de control 0 los descriptores de cada una de las configuraciones con el comando GET_DESCRIPTOR(configuration). Normalmente cada dispositivo sólo tiene una única configuración.
5. El dispositivo envía como respuesta también a través del endpoint de control 0 los descriptores de configuración (normalmente uno). Cuando un dispositivo envía el descriptor de configuración, envía dentro de él los descriptores de interface y de endpoints asociados a dicha configuración (ver imagen anterior).
6. Cuando el host (el ordenador) ya sabe quién es el dispositivo lo enumera, esto es, le asigna una dirección en el bus USB y envía al dispositivo el comando SET_ADDRESS(dirección).
7. El dispositivo queda enumerado y pasa a escuchar en la dirección indicada por el host.
8. El host envía al dispositivo el comando SET_CONFIGURATION(configuracion) para decirle al dispositivo que quiere trabajar con una configuración en concreto (como vimos antes, normalmente sólo hay una configuración por cada dispositivo).
A partir de este momento el dispositivo queda listo para usar y para que se empiecen a usar el resto de sus endpoints.
El protocolo es mucho más complejo y es necesario tener en cuenta algunos comandos más (SET_FEATURE, GET_STATUS, etc.) pero a grosso modo así es como funciona el invento.
Recomiendo a todo aquel interesado en el tema, dos lecturas de referencia:
- USB in a Nutshell
- USB Made Simple
Son muy sencillas de leer y mucho más asequibles que el aterrador tocho de 650 páginas de la especificación oficial.
Implementación en el ATmega32u4
Este microcontrolador, incluido en el Arduino Leonardo, puede ser configurado como dispositivo USB. Debido a que los tiempos USB son extremadamente cortos, es necesario realizar una implementación orientada a interrupciones. Como prueba de concepto he decidido implementar un puerto serie virtual (al estilo de los cables conversores USB a RS232) basado en dos endpoints de tipo bulk, uno de entrada y otro de salida.
El pseudocódigo para implementar el dispositivo USB quedaría así:
interrupción de reset de bus USBLos descriptores se encuentran definidos en USBDescriptor.H:
configurar endpoints 0 como control, 1 como bulk in y 2 como bulk out
inicializar buffers
habilitar interrupción de endpoints
fin interrupción
interrupción de endpoints
si ha llegado un paquete de setup por el endpoint 0 entonces
si es de tipo GET_DESCRIPTOR entonces
devolver el descriptor correspondiente
en otro caso, si es de tipo SET_ADDRESS entonces
configurar el módulo USB del chip para usar la dirección indicada
en otro caso, si es de tipo GET_STATUS entonces
devolver 0 (todo ok)
en otro caso, si es de tipo GET_CONFIGURATION entonces
devolver un 1 (la configuración activa es siempre la 1)
en otro caso, si es de tipo SET_CONFIGURATION entonces
no hacer nada (sólo hay una configuración y es la que siempre está activa)
fin si
en otro caso, si ha llegado un token bulk out por el endpoint 2 entonces
transferir bytes del buffer del endpoint 2 al buffer de usuario
en otro caso, si ha llegado un token bulk in por el endpoint 1 entonces
transferir bytes del buffer de usuario al buffer del endpoint 1
fin si
fin interrupción
class USBSerialDescriptorContainer { public: USBDeviceDescriptor deviceDescriptor; USBConfigurationDescriptor configurationDescriptor; USBInterfaceDescriptor interfaceDescriptor; USBEndpointDescriptor inEndpointDescriptor; USBEndpointDescriptor outEndpointDescriptor; } __attribute__ ((packed)); const USBSerialDescriptorContainer MyUSBSerialDescriptorContainer = { { // device descriptor 0x12, // descriptor size 0x01, // descriptor type (device) 0x0100, // usb protocol version 0x00, 0x00, 0x00, 0x40, // bMaxPacketSize0 = 64 (for endpoint 0) 0xA4F6, // idVendor 0x5678, // idProduct 0x0100, // product version 0x00, 0x00, 0x00, 0x01 // one available configuration }, { // configuration descriptor 0x09, // descriptor size 0x02, // descriptor type (configuration) 0x0020, // total size of this descriptor and rest of descriptors inside this configuration 9 + 9 + 7 + 7 = 32 bytes 0x01, // num interfaces = 1 0x01, // this configuration number = 1 0x00, 0x80, // not self powered 0x04 // max power in units of 5 mA (4 * 5 = 20 mA) }, { // interface descriptor 0x09, // descriptor size 0x04, // descriptor type (interface) 0x00, // interface number (zero based) 0x00, 0x02, // num endpoints = 2 0xFF, // class = vendor specific 0x00, // subclass 0x00, 0x00 }, { // in endpoint descriptor 0x07, // descriptor size 0x05, // descriptor type (endpoint) 0x81, // in endpoint 1 0x02, // bulk endpoint 0x0040, // max packet size = 64 0x0A // 10ms for interval polling }, { // out endpoint descriptor 0x07, // descriptor size 0x05, // descriptor type (endpoint) 0x02, // out endpoint 2 0x02, // bulk endpoint 0x0040, // max packet size = 64 0x0A // 10ms for interval polling } };
Para hacer la prueba de concepto lo he implementado todo, por ahora, en una única clase USB a modo de utility class (con atributos y métodos estáticos):
ISR(USB_GEN_vect) {
USB::__general_isr();
}
void USB::__general_isr() {
if (UDINT & (1 << EORSTI))
USB::configureEndpoint0();
UDINT = 0;
}
ISR(USB_COM_vect) {
USB::__endpoint_isr();
}
void USB::sendDataToEndpoint0() {
while (USB::toSendSize > 0) {
// wait for host ready for in packet
while (!(UEINTX & ((1 << TXINI) | (1 << RXOUTI))))
;
if (UEINTX & (1 << RXOUTI))
break;
// send in packet
uint16_t n = (USB::toSendSize >= 64) ? 64 : USB::toSendSize;
USB::writeFromBuffer(n, USB::toSend);
USB::toSend += n;
USB::toSendSize -= n;
UEINTX = ~(1 << TXINI);
}
}
void USB::__endpoint_isr() {
if (USB::status == USB::STATUS_IDLE) {
UENUM = 0;
uint8_t aux = UEINTX;
if (aux & (1 << RXSTPI)) {
// setup packet received
USB::readOnBuffer(8, USB::buffer);
USB::setupPacketReceived = (USBSetupPacket *) USB::buffer;
UEINTX = ~((1 << RXSTPI) | (1 << RXOUTI) | (1 << TXINI));
if (USB::setupPacketReceived->bRequest == USBSetupPacket::REQUEST_GET_DESCRIPTOR) {
uint8_t descriptorType = USB::setupPacketReceived->wValue >> 8;
USB::toSendSize = 0;
if (descriptorType == 1) {
// get the device descriptor
USB::toSend = (uint8_t *) &MyUSBSerialDescriptorContainer.deviceDescriptor;
USB::toSendSize = sizeof(USBDeviceDescriptor);
USB::toSendSize = (USB::toSendSize > USB::setupPacketReceived->wLength) ? USB::setupPacketReceived->wLength : USB::toSendSize;
}
else if (descriptorType == 2) {
// get the configuration descriptor
USB::toSend = (uint8_t *) &MyUSBSerialDescriptorContainer.configurationDescriptor;
USB::toSendSize = sizeof(USBSerialDescriptorContainer) - sizeof(USBDeviceDescriptor);
USB::toSendSize = (USB::toSendSize > USB::setupPacketReceived->wLength) ? USB::setupPacketReceived->wLength : USB::toSendSize;
}
USB::sendDataToEndpoint0();
}
else if (USB::setupPacketReceived->bRequest == USBSetupPacket::REQUEST_SET_ADDRESS) {
UEINTX = ~(1 << TXINI);
USB::address = USB::setupPacketReceived->wValue;
UDADDR = USB::address;
while (!(UEINTX & (1 << TXINI)))
;
UDADDR |= (1 << ADDEN);
UEINTX = ~(1 << TXINI);
}
else if (USB::setupPacketReceived->bRequest == USBSetupPacket::REQUEST_GET_STATUS) {
USB::buffer[0] = 0;
USB::buffer[1] = 0;
USB::toSend = (uint8_t *) USB::buffer;
USB::toSendSize = 2;
USB::sendDataToEndpoint0();
}
else if (USB::setupPacketReceived->bRequest == USBSetupPacket::REQUEST_GET_CONFIGURATION) {
USB::buffer[0] = 1;
USB::toSend = (uint8_t *) USB::buffer;
USB::toSendSize = 1;
USB::sendDataToEndpoint0();
}
else if (USB::setupPacketReceived->bRequest == USBSetupPacket::REQUEST_SET_CONFIGURATION) {
UEINTX = ~(1 << TXINI);
}
}
// check for bulk out transfer
UENUM = 2;
if (UEINTX & (1 << RXOUTI)) {
UEINTX &= ~(1 << RXOUTI);
uint16_t numBytesReceived = (((uint16_t) UEBCHX) << 8) | ((uint16_t) UEBCLX);
numBytesReceived = (numBytesReceived > 64) ? 64 : numBytesReceived;
USB::readOnBuffer(numBytesReceived, USB::rxBuffer);
USB::rxBufferFull = true;
UEINTX &= ~(1 << FIFOCON);
}
// check for bulk in transfer
UENUM = 1;
if (UEINTX & (1 << TXINI)) {
UEINTX &= ~(1 << TXINI);
// TODO: write data to buffer
UEINTX &= ~(1 << FIFOCON);
}
}
else if (USB::status == USB::STATUS_HALT) {
UENUM = 0;
UEINTX = ~((1 << RXSTPI) | (1 << RXOUTI) | (1 << TXINI));
UECONX = (1 << STALLRQ) | (1 << EPEN); // stall
}
}
Una vez conectado el Arduino Leonardo y enumerado el dispositivo podemos, desde un ordenador con Linux, reconocer el nuevo dispositivo como interface serie:
1. Instalamos el driver usbserial:
modprobe usbserial vendor=0xa4f6 product=0x5678Esto instala el driver genérico usbserial y lo asocia a nuestro dispositivo creando el dispositivo /dev/ttyUSB0 en el sistema de archivos.
2. Emitimos una cadena de caracteres de ejemplo para hacer la prueba:
echo -en "Prueba desde Linux\n\0" > /dev/ttyUSB03. Voilà:

El código es compatible también con el microcontrolador ATmega16u4 y es muy fácil de adaptar al resto de microcontroladores USB de AVR. Puede descargarse de la sección soft.
[ 2 comentarios ] ( 8002 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |

 ( 3 / 5659 )
( 3 / 5659 )Teensy3 es una pequeña placa de desarrollo que se integra perfectamente en el entorno de desarrollo de Arduino y que incluye un potente procesador ARM Cortex-M4 a 96 MHz con 256Kb de Flash, 64Kb de RAM, DAC, ADC, CAN y otros periféricos. A lo largo de este artículo se explicará paso a paso cómo construir y configurar desde cero la toolchain de GNU para programar el Teensy3 en C++.

Compilar la toolchain de GNU
En mi caso he utilizado una placa Teensy 3.1. El corazón de esta placa es el microcontrolador de 32 bits MK20DX256VLH7, un ARM Cortex-M4 a 96MHz. Lo primero que hay que hacer es compilar la toolchain en sí para el target arm-none-eabi. Uno de los mejores tutoriales de compilación dde la toolchain de GNU para ARM es el publicado aquí. En mi caso he utilizado las binutils 2.24, el gcc 4.9.0 y la última versión de newlib disponible por CVS.
El tutorial anterior utiliza una versión de gcc antigua y no echa en falta ninguna librería, sin embargo, si queremos compilar el gcc 4.9.0 hemos de incluir las librerías GMP, MPFR y MPC. En este enlace se indica cómo incluir las librerías en el código fuente del gcc 4.9.0 para que se compilen junto con el gcc.
Una vez compilada la toolchain tendremos el compilador de C++ y el resto de herramientas (ensamblador, enlazador, etc.) disponibles en la carpeta de prefijo de instalación que hayamos utilizado. En mi caso he usado /opt/teensy.
El microcontrolador MK20DX256
Este microcontrolador está basado en un núcleo ARM Cortex-M4. La secuencia de arranque de estos procesadores se describe aquí. De forma resumida, en la direción de memoria 0x00000000 se encuentra el valor que se le asigna al puntero de pila en el arranque, mientras que en la dirección 0x00000004 se encuentra la dirección de memoria donde se ejecuta la primera instrucción, hay más vectores, aunque estos dos son los más importantes. Como se puede ver, no se trata de instrucciones, sino de una tabla de punteros.
Los 256Kb de Flash comienzan a partir de la dirección 0x00000000 mientras que los 64Kb de RAM van desde 0x1FFF8000 hasta 0x20008000. La pila del Cortex-M4 puede configurarse de cualquier forma (ascendente, descendente, etc.). Sin embargo las instrucciones push y pop por defecto trabajan con una pila descendente (mas información aquí). De esta forma nuestro mapa de memoria queda como sigue:
offset tamaño uso
0x00000000 4 bytes puntero de pila en el arranque
0x00000004 4 bytes puntero a la primera instrucción tras el reset
0x00000400 16 bytes palabras de configuración del microcontrolador
0x00000410 261104 bytes código
0x1FFF8000 32768 bytes variables globales
0x20000000 32768 bytes pila y variables locales
Al ser una pila descendente, el puntero de pila se inicializa con 0x20007FFC, que es la última palabra de 32 bits direccionable en la RAM. Con este mapa de memoria elaboramos el siguiente linker script:
SECTIONS {
. = 0x00000000 ;
.cortex_m4_vectors : {
LONG(0x20007FFC);
LONG(0x00000411);
}
. = 0x00000400 ;
.flash_configuration : {
LONG(0xFFFFFFFF);
LONG(0xFFFFFFFF);
LONG(0xFFFFFFFF);
LONG(0xFFFFFFFE);
}
.text : {
_linker_code = . ;
init.o (.text)
*(.text)
*(.text.*)
*(.rodata*)
*(.gnu.linkonce.t*)
*(.gnu.linkonce.r*)
}
.preinit_array : {
__preinit_array_start = . ;
*(.preinit_array)
__preinit_array_end = . ;
}
.init_array : {
__init_array_start = . ;
*(.init_array)
__init_array_end = . ;
}
.fini_array : {
__fini_array_start = . ;
*(.fini_array)
__fini_array_end = . ;
}
.ctors : {
__CTOR_LIST__ = . ;
LONG((__CTOR_END__ - __CTOR_LIST__) / 4 - 2)
*(.ctors)
LONG(0)
__CTOR_END__ = . ;
}
.dtors : {
__DTOR_LIST__ = . ;
LONG((__DTOR_END__ - __DTOR_LIST__) / 4 - 2)
*(.dtors)
LONG(0)
__DTOR_END__ = . ;
}
flash_sdata = . ;
. = 0x1FFF8000 ;
ram_sdata = . ;
.data : AT (flash_sdata) {
_linker_data = . ;
*(.data)
*(.data.*)
*(.gnu.linkonce.d*)
}
ram_edata = . ;
data_size = ram_edata - ram_sdata;
ram_sbssdata = . ;
.bss : AT (LOADADDR(.data) + SIZEOF(.data)) {
_linker_bss = . ;
*(.bss)
*(.bss.*)
*(.gnu.linkonce.b.*)
*(.COMMON)
}
ram_ebssdata = . ;
bssdata_size = ram_ebssdata - ram_sbssdata;
_linker_end = . ;
}
El linker script tiene las secciones habituales: .text, .init_array, .fini_array, .ctors, .dtors, .data, .bss, etc. más dos secciones adicionales: .cortex_m4_vectors y .flash_configuration.
Dirección de carga y dirección virtual en el linker script
Cuando se escribe un linker script para un microcontrolador o para un sistema basado en memoria Flash hay que tener en cuenta que las secciones .data y .bss (datos inicializados y sin inicializar, respectivamente) se cargan inicialmente en Flash y que, en el momento de la ejecución, dichas secciones deben copiarse a RAM. El linker script permite definir direcciones de carga y direcciones virtuales para cada sección de forma independiente con lo que es posible hacer de forma sencilla esta funcionalidad:
flash_sdata = . ;
. = 0x1FFF8000 ;
ram_sdata = . ;
.data : AT (flash_sdata) {
*(.data)
}
ram_edata = . ;
data_size = ram_edata - ram_sdata ;
Antes de definir la sección .data guardamos en la variable flash_sdata la dirección virtual actual, definimos la dirección virtual actual como 0x1FFF8000 (inicio de la parte de la RAM que hemos decidido que aloje las variables globales) y guardamos en ram_sdata esta dirección virtual. A continuación definimos la sección .data con el atributo AT (flash_sdata) para indicarle al linker que queremos que se cargue en la dirección flash_sdata, que es una dirección dentro de la memoria Flash, aunque la dirección virtual será 0x1FFF8000. Tras la definición de la sección .data generamos símbolos para calcular el tamaño de la sección. Con la sección .bss (datos globales sin inicializar) hacemos lo mismo.
Código de inicialización
El linker script nos ha permitido definir las secciones .data y .bss con direcciones virtuales y de carga diferentes, sin embargo la copia de los datos habrá que hacerla a mano antes de la ejecución de la función main.
Este fichero contiene el código de inicialización en ensamblador que vamos a utilizar.
.syntax unified .thumb .thumb_func .global _startup .section .text _init: mov r0,#0 mov r1,#0 mov r2,#0 mov r3,#0 mov r4,#0 mov r5,#0 mov r6,#0 mov r7,#0 mov r8,#0 mov r9,#0 mov r10,#0 mov r11,#0 mov r12,#0 /* disable interrupts */ CPSID i /* unlock_watchdog */ ldr r6, = 0x4005200e /* WDOG_UNLOCK doc: K20P64M50SF0RM.pdf ( Page: 423 ) */ ldr r0, = 0xc520 strh r0, [r6] ldr r0, = 0xd928 strh r0, [r6] /* disable_watchdog */ ldr r6, = 0x40052000 /* WDOG_STCTRLH doc: K20P64M50SF0RM.pdf ( Page: 418 ) */ ldr r0, = 0x01d2 strh r0, [r6] /* enable interrupts */ CPSIE i /* copy data section from flash to ram */ ldr r0, = flash_sdata ldr r1, = ram_sdata ldr r2, = data_size cmp r2, #0 beq skip_copy copy: ldrb r4, [r0], #1 strb r4, [r1], #1 subs r2, r2, #1 bne copy skip_copy: /* fill bssdata section with zeros */ ldr r1, = ram_sbssdata ldr r2, = bssdata_size cmp r2, #0 beq skip_fill mov r4, #0 fill: strb r4, [r1], #1 subs r2, r2, #1 bne fill skip_fill: b _startup .end
Como se puede ver: Inicializamos los registros del procesador, deshabilitamos las interrupciones, desactivamos el watchdog del MK20 (hay que hacerlo dentro de los primeros 256 ciclos del procesador tras el reset), copiamos los datos de la sección .data desde la Flash a la RAM y rellenamos con ceros la sección .bss. Cuando terminamos de rellenar con ceros la sección .bss saltamos a la función _startup.
La función "_startup" la definimos en un fichero de C++:
#include <stdint.h> using namespace std; extern "C" { extern void (*__CTOR_LIST__)(); extern void (*__DTOR_LIST__)(); extern void (*__init_array_start)(); extern void (*__init_array_end)(); extern void (*__fini_array_start)(); extern void (*__fini_array_end)(); } void callInitArray() { void (**f)() = &__init_array_start; while (f != &__init_array_end) { (*f)(); f++; } } void callConstructors() { void (**constructor)() = &__CTOR_LIST__; uint32_t total = *(uint32_t *) constructor; constructor++; while (total) { (*constructor)(); total--; constructor++; } } void callDestructors() { void (**destructor)() = &__DTOR_LIST__; uint32_t total = *(uint32_t *) destructor; destructor++; while (total) { (*destructor)(); total--; destructor++; } } void callFiniArray() { void (**f)() = &__fini_array_start; while (f != &__fini_array_end) { (*f)(); f++; } } extern int main(); void _startup() asm("_startup"); void _startup() { callConstructors(); callInitArray(); main(); callFiniArray(); callDestructors(); while (true) ; } extern "C" void __cxa_pure_virtual() {} void *__dso_handle = 0; extern "C" void __cxa_atexit() {}
La función _startup se encarga de invocar a los constructores globales y a la función main. El fichero Makefile que se utiliza es el siguiente:
BIN_PREFIX=/opt/teensy/bin/ CXX=${BIN_PREFIX}arm-none-eabi-g++ OBJCOPY=${BIN_PREFIX}arm-none-eabi-objcopy CXX_FLAGS=-mtune=cortex-m4 -mthumb -fno-exceptions -fno-rtti -nostdlib -nodefaultlibs -nostartfiles main.hex: main.elf $(OBJCOPY) -O ihex -R .eeprom main.elf main.hex main.elf: main.o init.o startup.o $(CXX) $(CXX_FLAGS) -Wl,-Tteensy31.ld -o main.elf main.o init.o startup.o main.o: main.cc $(CXX) $(CXX_FLAGS) -c -o $@ $< startup.o: startup.cc $(CXX) $(CXX_FLAGS) -c -o $@ $< init.o: init.s $(CXX) $(CXX_FLAGS) -c -o $@ $< clean: rm -f *.elf *.o *.hex *.bin
Prueba de concepto
En este caso simplemente he implementado la típica funcionalidad de led parpadeante (para variar xD)
#include <stdint.h> using namespace std; #define GPIO_ENABLE (1 << 8) #define PULL_UP_ENABLE (1 << 1) #define PULL_UP_SELECT (1 << 0) #define DRIVE_STR (1 << 6) #define PORT_CTRL_FLAGS (DRIVE_STR | GPIO_ENABLE | PULL_UP_ENABLE | PULL_UP_SELECT) #define PORTC_PCR5 *((uint32_t *) 0x4004B014) #define GPIOC_PDDR *((uint32_t *) 0x400FF094) #define GPIOC_PDOR *((uint32_t *) 0x400FF080) #define SIM_SCGC5 *((uint32_t *) 0x40048038) #define WDOG_UNLOCK *((uint32_t *) 0x4005200E) #define WDOG_STCTRLH *((uint32_t *) 0x40052000) #define CLOCKS_ACTIVE_TO_ALL_GPIO 0x00043F82 #define WATCHDOG_UNLOCK_VALUE_1 0xC520 #define WATCHDOG_UNLOCK_VALUE_2 0xD928 #define WATCHDOG_DISABLE_VALUE 0x01D2 class Clase { public: uint32_t n; uint32_t v1, v2; Clase(uint32_t x1, uint32_t x2, uint32_t aux); }; Clase::Clase(uint32_t x1, uint32_t x2, uint32_t aux) { this->v1 = x1; this->v2 = x2; this->n = aux; } Clase objeto(1, 2, 100000); uint32_t a = 50000; //uint32_t a = 100000; int main() { // configure PTC5 SIM_SCGC5 = CLOCKS_ACTIVE_TO_ALL_GPIO; PORTC_PCR5 = PORT_CTRL_FLAGS; // PORTC is output GPIOC_PDDR = (uint32_t) 0xFFFFFFFF; while (1) { volatile uint32_t i; // PORTC to 1 GPIOC_PDOR = (uint32_t) 0xFFFFFFFF; for (i = 0; i < objeto.n; i++) ; // PORTC to 0 GPIOC_PDOR = (uint32_t) 0x00000000; for (i = 0; i < objeto.n; i++) ; } }
El código fuente puede descargarse de la sección soft.
ACTUALIZACIÓN: En la sección "Compilar la toolchain de GNU" se incluye un enlace a una web que ya no se encuentra disponible (http://kunen.org/uC/gnu_tool.html). En dicha web se indicaban los pasos pormenorizados para compilar toda la toolchain de GNU. Afortunadamente he podido rescatar gracias al histórico de mi ordenador los pasos que seguí yo guiándome por esa web y los he recompilado es este post.
ACTUALIZACIÓN: La versión anterior no rellenaba con ceros la sección .bss de la RAM de datos globales. Se ha incluido la corrección en la descripción del texto, en el código mostrado en el post y en el fichero tar.gz de la sección soft.
[ añadir comentario ] ( 3620 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4615 )La posibilidad de redefinir una parte del juego de caracteres en los displays LCD alfanuméricos, en combinación con el uso de una de las entradas analógicas del AVR y un pequeño circuito analógico, nos va a permitir la implementación de un sencillo vúmetro en el Arduino.
Un vúmetro no es más que un medidor gráfico de intensidad de señal de audio. En este caso vamos a abordar una implementación muy sencilla y lineal (no logarítmica).

Entrada analógica
La entrada analógica del microcontrolador AVR en el Arduino permite medir entre 0 y 5 voltios con una precisión de 10 bits, de 0 a 1023. 0 se corresponde con 0 voltios y 1023 se corresponde con 5 voltios. Para obtener la intensidad de señal en una de las entradas analógicas, realizamos los siguientes pasos:
1. Amplificación
2. Detección de envolvente
La amplificación se ha implementado construyendo una sencilla etapa estándar de amplificación basada en un transistor NPN con configuración de emisor común:
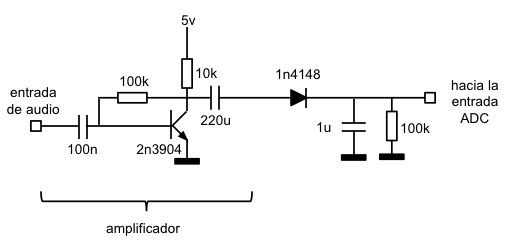
La señal de entrada es una señal de audio en alterna (en este caso la he conectado a la salida de auriculares de mi móvil). Dicha señal, al pasar por el circuito de amplificación se invierte en fase (no nos importa) y, lo más importante, se amplifica. La señal de salida es también en alterna (el condensador de salida elimina la componente de continua) y pasa la siguiente parte del circuito: el detector de envolvente.
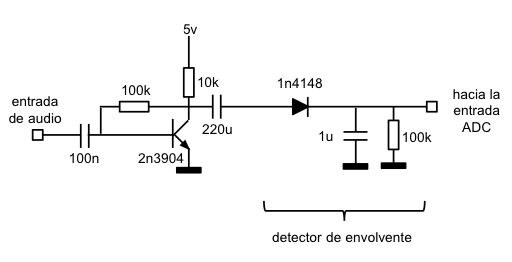
Un detector de envolvente es un circuito que, a partir de una señal de entrada, determina su envolvente:
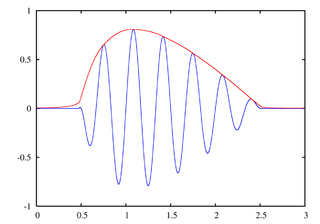
(imagen extraida de Wikimedia Commons)
El circuito detector de envolvente es muy sencillo: La señal alterna, al hacerla pasar por un diodo, se rectifica y sólo deja pasar los semiciclos positivos. En cada uno de los semiciclos positivos de la señal se carga el condensador y, durante las pausas entre semiciclos, en ausencia de corriente que pase por el diodo, el condensador se descarga lentamente a través de la resistencia, así hasta el siguiente ciclo, que se repite el proceso. El resultado en la salida es una señal que sigue de forma aproximada a los picos de la señal de audio que hay en la entrada.
Hay que elegir correctamente los valores del condensador y la resistencia: Un valor de condensador muy bajo hará que se descargue rápidamente mientras que un valor de condensador muy alto hará que tarde excesivamente en cargarse. En el caso de la resistencia de descarga del condensador un valor muy alto hará que el condensador apenas se descargue en las pausas entre ciclos (lo que puede provocar que los ciclos se sumen a medida que llegan) y un valor muy bajo hará que el condensador se descargue muy rápido, perdiendo el efecto de seguimiento de envolvente.
Display LCD
En post anteriores de este blog publiqué varias clases C++ para la gestión de displays LCD. En este caso he reutilizado la clase Lcd20x4 de proyectos anteriores, redefiniendo de forma estática 5 de los caracteres definibles por el usuario.
Para implementar una barra horizontal hay que tener en cuenta que tenemos 20 columnas y que cada carácter tiene 5 columnas de puntos: En total tenemos 100 pixels en horizontal para un display LCD de 20x4. Si definimos los caracteres de la siguiente forma:
* . . . .
* . . . .
* . . . .
* . . . . --> 1
* . . . .
* . . . .
* . . . .
* * . . .
* * . . .
* * . . .
* * . . . --> 2
* * . . .
* * . . .
* * . . .
...
* * * * *
* * * * *
* * * * *
* * * * * --> 5
* * * * *
* * * * *
* * * * *
Utilizando este método de visualización, la barra LCD podrá adoptar valores entre 0 y 100. El pseudocódigo para visualizar un valor v será:
procedimiento mostrar_valor(v) // 0 <= v <= 100
numCaracteresTotalmenteLlenos := parte entera de (v / 5)
valorCaracterParcial := (v mod 5)
ir_coordenada(0, 0)
para x := 1 hasta numCaracteresTotalmenteLlenos hacer
escribir_carácter(5)
fin para
escribir_carácter(valorCaracterParcial)
para x := (numCaracteresTotalmenteLlenos + 2) hasta 20 hacer
escribir_carácter(0)
fin para
fin procedimiento
Como se puede ver, para cada valor v que se quiera visualizar en la barra, se escribe toda una fila horizontal del display LCD. La visualización puede optimizarse si partimos de la base de que la diferencia entre un valor v enviado en un instante t y el valor v enviado al display en un instante t + d no va a variar mucho si d es lo suficientemente pequeño. En nuestro caso vamos a hacer un muestreo de la entrada analógica cada 50ms por lo que la v no va a variar excesivamente entre un instante de muestreo y el siguiente.
Si asumimos que la v no va a variar mucho podemos enviar al LCD sólo los cambios:
barraLogica[20]
barraFisica[20]
procedimiento mostrar_valor(v)
numCaracteresTotalmenteLlenos := parte entera de (v / 5)
valorCaracterParcial := (v mod 5)
j := 0
para x := 1 hasta numCaracteresTotalmenteLlenos hacer
barraLogica[j] := 5
j := j + 1
fin para
barraLogica[j] := valorCaracterParcial
j := j + 1
para x := (numCaracteresTotalmenteLlenos + 2) hasta 20 hacer
barraLogica[j] := 0
j := j + 1
fin para
fin procedimiento
procedimiento actualiza
dentroCambio := NO
inicioCambio := -1
para j := 0 hasta 19 hacer
si (dentroCambio) entonces
si (barraFisica[j] = barraLogica[j]) entonces
escribir_barra_fisica(inicioCambio, j)
dentroCambio := NO
fin si
en otro caso
si (barraFisica[j] <> barraLogica[j]) entonces
inicioCambio := j
dentroCambio := SI
fin si
fin si
barraFisica[j] := barraLogica[j]
fin para
si (dentroCambio) entonces
escribir_barra_fisica(inicioCambio, 19)
fin si
fin procedimiento
El procedimiento actualiza se ejecutará de forma periódica y, como se puede ver, sólo envía al display LCD los caracteres que cambien. Esta forma de refresco del display LCD es más eficiente y nos permite tasas de muestreo mayores.
En el siguiente vídeo puede verse el circuito en acción:
El código en C++ puede descargarse de la sección soft.
[ añadir comentario ] ( 3324 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 17727 )El control de displays LCD alfanuméricos desde microcontroladores es un tópico ampliamente abordado en muchas webs y tutoriales. El juego de caracteres utilizado por este tipo de displays es de tipo ASCII con algunos símbolos adicionales, sobre todo asiáticos, y se echan en falta varios de los símbolos propios del español (tildes, diéresis, etc.). A lo largo de este post se plantea un sencillo algoritmo de gestión del display LCD que permite la utilización de texto en español de forma transparente al usuario.
Características del display
Los displays LCD alfanuméricos estándar almacenan los mapas de bits (los dibujos) de su juego de caracteres en una ROM interna, con la excepción de los 8 primeros caracteres (del 0 al 7). Los mapas de bits de estos 8 primeros caracteres se almacenan en una parte de la RAM del LCD denominada CGRAM (Character Generator RAM). Es esta parte de la RAM la que hay que utilizar para representar los caracteres extendidos no ASCII del español en nuestro display.
El mapa de bits de cada carácter está formado por una matriz de 5x7 puntos que se almacena en la CGRAM como 8 bytes consecutivos: 1 byte por cada línea horizontal (de la cual sólo son significativos los 5 bits más bajos) y un 1 byte adicional para la línea de cursor que siempre se pone a 0 para displays de 5x7. Como son configurables sólo los 8 primeros caracteres del juego de caracteres, esto nos da 8 * 8 = 64 bytes para la CGRAM.
. . . x . 0 0 0 1 0
. . x . . 0 0 1 0 0
. x x x . 0 1 1 1 0
á --> . . . . x --> 0 0 0 0 1
. x x x x 0 1 1 1 1
x . . . x 1 0 0 0 1
. x x x x 0 1 1 1 1
. . . . . 0 0 0 0 0
Gestión de los caracteres
En español tenemos 16 caracteres que se salen de la simbología ASCII:
á é í ó ú ü ñ Á É Í Ó Ú Ü Ñ ¿ ¡
Como no es posible cargar en la CGRAM los mapas de bits de estos 16 caracteres de forma simultánea, es necesario implementar algún tipo de gestión a nivel software que cargue en CGRAM sólo los caracteres que necesitamos en cada momento.
Para la gestión de los caracteres se han utilizado las siguientes estructuras de datos (en pseudocódigo):
EntradaTabla {
caracterLatin1
mapaDeBits
caracterLcd
caracterLcdDefecto
vecesUsado
marcaCarga
}
EntradaTabla tabla[16]
Cola caracteresLcdDisponiblesCada entrada de la tabla de caracteres especiales incluye el carácter ISO-8859-1 o latin1 correspondiente y el mapa de bits que lo dibuja en el display. caracterLcd es el carácter del LCD (1 al 7, no vamos a usar la entrada 0 por si acaso) que está mapeando a este carácter especial. caracterLcdDefecto es el carácter de la ROM que mapeará a este carácter latin1 en caso de que no esté disponible ningún hueco en la CGRAM (por ejemplo á tiene como carácter por defecto a).
vecesUsado indica cuántas veces está siendo usado esa entrada de la tabla de caracteres extendidos: cada vez que se utiliza un carácter especial, se incrementa este contador de la entrada correspondiente y cada vez que se deja de utilizar en alguna parte de la pantalla (se borra o se sustituye por otro), se decrementa este contador de la entrada correspondiente. Cuando un contador llega a 0, el hueco que ocupaba esa entrada en la CGRAM es marcado como vacío (metido en la cola de caracteres LCD disponibles.
marcaCarga indica cuando una entrada de la tabla debe ser cargada en la CGRAM. La carga de los bitmaps de las entradas marcadas se realiza a posteiori para no influir en la escritura de los caracteres. Primero se escribe en la DDRAM (la memoria de pantalla) y al final, si es necesario enviar bitmaps de caracteres no ASCII, se escribe en la CGRAM.
inicializar(EntradaTabla e)
e.caracterLcd = 0
e.vecesUsado = 0
e.marcaCarga = NO
fin
inicializarCola
meter(caracteresLcdDisponibles, 1)
meter(caracteresLcdDisponibles, 2)
meter(caracteresLcdDisponibles, 3)
meter(caracteresLcdDisponibles, 4)
meter(caracteresLcdDisponibles, 5)
meter(caracteresLcdDisponibles, 6)
meter(caracteresLcdDisponibles, 7)
fin
buscarEntrada(c) {
Devuelve la entrada en tabla que cumpla caracterLatin1 == c, o NULL en caso de no haber ninguna entrada.
fin
reemplazarCaracter(nuevo, viejo)
EntradaTabla e = buscarEntrada(viejo)
si (e != NULL) {
e.vecesUsado = e.vecesUsado - 1
si (e.vecesUsado == 0) {
meter(caracteresLcdDisponibles, e.caracterLcd)
e.caracterLcd = 0
fin si
fin si
e = buscarEntrada(nuevo);
si (e == NULL)
devolver nuevo
en otro caso
si (e.caracterLcd > 0)
e.vecesUsado = e.vecesUsado + 1
en otro caso
si (caracteresLcdDisponibles está vacía)
devolver e.caracterLcdDefecto
e.caracterLcd = sacar(caracteresLcdDisponibles)
e.vecesUsado = 1
e.marcaCarga = SI
fin si
devolver e.caracterLcd
fin si
fin
procesar
para todos los segmentos de texto que haya que cambiar en el display
para todos los caracteres del segmento de texto
nuevo = nuevo carácter
viejo = actual carácter
v = reemplazarCaracter(nuevo, viejo)
emitir(v)
fin para
fin para
para todas las entradas e de la tabla con marcaCarga = SI hacer
cargar e.mapaDeBits en la CGRAM correspondiente al carácter e.caracterLcd
e.marcaCarga = NO
fin para
fin
Ejemplo de traza
Imaginemos que tenemos la pantalla en blanco (recién inicializada): Todas las entradas de la tabla las tenemos inicializadas (caracterLcd=0, vecesUsado=0, marcaCarga=NO) y la cola caracteresLcdDisponibles inicializada con los 7 huecos.
Para escribir la palabra Máquina, el proceso irá llamando a reemplazarCaracter por cada nueva letra:
reemplazarCaracter(M, )
No hay entrada en la tabla para el carácter
No hay entrada en la tabla para el carácter M
devuelve M
reemplazarCaracter(á, )
No hay entrada en la tabla para el carácter
Hay una entrada e para el carácter á
como e.caracterLcd = 0, entonces
la cola de caracteres disponibles no está vacía
e.caracterLcd = 1
e.vecesUsado = 1
e.marcarCarga = SI
devuelve e.caracterLcd (1)
reemplazarCaracter(q, )
No hay entrada en la tabla para el carácter
No hay entrada en la tabla para el carácter q
devuelve q
reemplazarCaracter(u, )
No hay entrada en la tabla para el carácter
No hay entrada en la tabla para el carácter u
devuelve u
...
Al final del proceso de escritura de la cadena Máquina tenemos que la cola de caracteres disponibles está así: [2, 3, 4, 5, 6, 7] y que la entrada de la tabla de caracteres correspondiente a la letra á tiene caracterLcd=1, vecesUsado=1, el resto de entradas siguen como al principio.

De esta forma se va alojando espacio en la CGRAM del display LCD en función de los caracteres especiales que necesitamos en todo momento. Nótese que, en caso de que ya no nos queden huecos libres (la cola de huecos esté vacía), devolvemos el carácter por defecto.
Políticas alternativas de sustitución de caracteres
Una política alternativa podría ser establecer una prioridad por cada carácter de la tabla: en caso de vaciado de la cola de huecos, se sacrifica el carácter con menor prioridad de los que estén siendo usados en ese momento. Un criterio de prioridad podría ser en función del valor de vecesUsado. De esta forma se sacrificarían los caracteres menos usados.
Nótese que esta política de sacrificado de caracteres menos prioritarios obligaría a refrescar los caracteres a sacrificar y cambiarlos por los caracteres por defecto correspondientes. En todas las posiciones donde se encuentren.
En esta implementación no se lleva a cabo ninguna política de sacrificado de caracteres. Cuando la cola de caracteres disponibles se acaba, se imprime el carácter por defecto.
Implementación
Este algoritmo de gestión de caracteres extendidos para displays LCD se ha implementado sobre un Arduino Leonardo en C++.
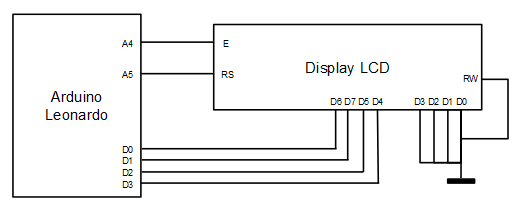
Se ha optado por una anchura de bus de 4 bits para minimizar el número de cables. El código fuente puede descargarse de la sección soft.
[ añadir comentario ] ( 3284 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
 ( 3 / 4568 )
( 3 / 4568 )Ampliando un post anterior en el que desarrollé un juego de tres en raya con el Arduino, he desarrollado una implementación inteligente del mismo. En la anterior versión, si bien el jugador jugaba contra la máquina, las posiciones que jugaba la máquina eran totalmente aleatorias y no seguían ningún criterio. En este caso la máquina utiliza un algoritmo de decisión (el minimax) para calcular el siguiente movimiento y así intentar ganar a su oponente humano.
Antecedentes
En la implementación anterior del tres en raya teníamos una clase abstracta denominada TTTGamePlayer de la cual heredaban las clases TTTHumanGamePlayer y TTTRandomGamePlayer. TTTHumanGamePlayer además de heredar de TTTGamePlayer, también heredaba de KeyMatrixListener, de esta forma los eventos de los pulsadores se transforman en movimientos del jugador humano.
La clase TTTRandomGamePlayer era una clase que inicializaba una semilla aleatoria. Dentro de esta clase el método getSpot(), que es el método virtual puro de TTTGamePlayer que debe devolver el movimiento que desea realizar el jugador, devolvía en este caso una posición aleatoria de entre todas las posiciones libres que quedaban en el tablero.
Algoritmo Minimax
El algoritmo minimax es un algoritmo de decisión muy simple desarrollado a partir del Teorema Minimax de John von Neumann en 1926 (para juegos de suma cero e información perfecta). El algoritmo es muy sencillo:
- Cuando nos toque mover a nosotros, calculamos el árbol de decisión del juego.
- Los nodos hoja del árbol representarán todas las posibles formas de terminar el juego. Asignamos a cada uno de los nodos hoja del árbol un valor numérico directamente proporcional a nuestro beneficio (o inversamente proporcional al beneficio de nuestro oponente).
- Vamos ascendiendo en el árbol escogiendo, alternativamente, el mínimo o el máximo de los hijos (minimax) en función de si cada decisión debe ser tomada por mí o por mi oponente (yo busco maximizar mi beneficio y mi oponente busca minimizarlo o, lo que es lo mismo, maximizar el suyo propio), así hasta la raíz. De esta forma podemos elegir el movimiento que minimize nuestra pérdida esperada.
Con un ejemplo del 3 en raya se ve mejor. Imaginemos que somos X y que nos toca mover a nosotros:
o x x
x . . sig. mov. = x, beneficio = max(-1, -1, 0) = 0
o o .
o x x
x x . sig. mov. = o, beneficio = min(0, -1) = -1
o o .
o x x
x x o sig. mov. = x, beneficio = max(0) = 0
o o .
o x x
x x o tablas, beneficio = 0
o o x
o x x
x x . gana o, beneficio = -1
o o o
o x x
x . x sig. mov. = o, beneficio = min(1, -1) = -1
o o .
o x x
x o x sig. mov. = x, beneficio = max(1) = 1
o o .
o x x
x o x gana x, beneficio = 1
o o x
o x x
x . x gana o, beneficio = -1
o o o
o x x
x . . sig. mov = o, beneficio = min(1, 0) = 0
o o x
o x x
x o . sig. mov. = x, beneficio = max(1) = 1
o o x
o x x
x o x gana x, beneficio = 1
o o x
o x x
x . o sig. mov. = x, beneficio = max(0) = 0
o o x
o x x
x x o tablas, beneficio = 0
o o x
A partir del nodo raíz, el beneficio máximo se corresponde con el movimiento:
o x x o x x
x . . ---> x . .
o o . o o x
En este caso beneficio se refiere a beneficio para X. Como se puede ver, partiendo del estado del tablero indicado por la raíz del árbol, el mejor movimiento será el de marcar la fila 3 y la columna 3.
Hardware
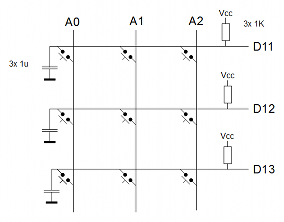
El montaje lo he realizado utilizando un Arduino Leonardo, conectando la matriz de pulsadores a los puertos A0, A1, A2, D11, D12 y D13
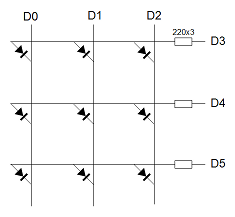
Y la matriz de leds a los puertos D0, D1, D2, D3, D4 y D5
Si vamos a realizar el montaje para otro modelo de Arduino hay que comprobar el mapeo de los puertos en el microcontrolador y modificar la implementación de las clases MyLedMatrixManager y MyKeyMatrixManager (como se trata de una implementación en C++, no tenemos a nuestra disposición la abstracción de puertos que nos proporciona el lenguaje Arduino).
Implementación
La clase TTTMinimaxGamePlayer es la que implementa el algoritmo minimax: Al igual que las clases TTTRandomGamePlayer y TTTHumanGamePlayer, hereda de TTTGamePlayer con la diferencia de que en su método getSpot() calcula el siguiente movimiento a realizar utilizando el algoritmo de decisión minimax.
uint8_t TTTMinimaxGamePlayer::getSpot() { uint8_t ret = 0; this->minimax(*this->board, true, ret); return ret; } int8_t TTTMinimaxGamePlayer::minimax(TTTGameBoard &board, bool me, uint8_t &bestMovement) { uint8_t winner = board.getWinner(); if (board.isFinished() || (winner != 0)) { int8_t ret = 0; if (winner == this->number) ret = 1; else if (winner == this->opponentNumber) ret = -1; return ret; } else { int8_t limit = 0; if (me) limit = -10; else limit = 10; TTTGameBoard auxBoard; uint8_t numMovements = 0; for (uint8_t m = board.getFirstAvailableMovement(); m != 0; m = board.getNextAvailableMovement(), numMovements++) { auxBoard.copyFrom(board); if (me) auxBoard.set(m, this->number); else auxBoard.set(m, this->opponentNumber); uint8_t childBestMovement; int8_t v = minimax(auxBoard, !me, childBestMovement); if (me) { if (v > limit) { limit = v; bestMovement = m; } } else { if (v < limit) { limit = v; bestMovement = m; } } } return limit; } }
Se trata de una implementación recursiva y el parametro me indica cuando se está simulando un movimiento propio (true) o un movimiento del oponente (false). A pesar de usarse una implementación recursiva, nótese que no se realizarán más de 8 llamadas recursivas: Cada nivel es un movimiento adicional y un tablero de 3 en raya sólo tiene 9 posiciones.
A modo de visión global, el diagrama de clases queda ahora así:
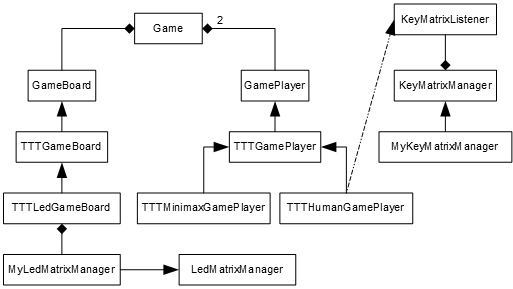
En la sección soft puede descargarse el código fuente del proyecto en C++. Aquí una pequeña guía sobre cómo desarrollar en C++ para el Arduino.
[ añadir comentario ] ( 4024 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4562 ) Calendario
Calendario





{kind=link}