
Introducción
La aritmética de punto fijo permite realizar operaciones con números fraccionarios mediante tipos enteros y operaciones enteras. En anteriores posts de este blog se ha hablado de forma extensa acerca de este tema, por lo que se remite a ellos a la persona interesada. A lo largo de este post usaré siempre valores de punto fijo Q16.16 (32 bits con 16 bits para la parte entera y 16 bits para la parte fraccionaria).
Implementación tradicional mediante macros
Tradicionalmente siempre he implementado la aritmética de punto fijo con un fichero de cabecera en el que defino "fixedpoint_t" como un "int32_t" y unas macros especiales para las operaciones de conversión de entero a punto fijo, de multiplicación y de división (las más "complejas"):
typedef int32_t fixedpoint_ct; #define FP_MUL(x, y) ((int32_t) ((((int64_t) (x)) * ((int64_t) (y))) >> 16)) #define FP_DIV(x, y) ((int32_t) ((((int64_t) (x)) << 16) / ((int64_t) (y)))) #define TO_FP(x) (((int32_t ) (x)) << 16)
Como se puede apreciar, se trata de una implementación extremadamente sencilla y si lo que queremos es escribir una función que calcule:
$$\left({a \times b}\right) + \left({a \over b}\right)$$
Introduciríamos el siguiente código:
fixedpoint_ct fWithMacros(fixedpoint_ct a, fixedpoint_ct b) { return FP_MUL(a, b) + FP_DIV(a, b); }
Y para los valores $a = 4$ y $b = 3$ la invocaríamos de la siguiente forma:
fixedpoint_ct v = fWithMacros(TO_FP(4), TO_FP(3));
Se trata de una implementación perfectamente válida aunque adolece de falta de claridad en el código: hay que leer con cuidado las operaciones aritméticas para no confundirse. Por otro lado es una implementación que tiene la ventaja de que en todo momento está claro que no estamos trabajando con un tipo "trivial".
Implementación basada en sobrecarga de operadores
Buscando un código más legible que el anterior, lo lógico es recurrir a la sobrecarga de operadores de C++. Definimos una clase "fixedpoint_t" en la que metemos un entero de 32 bits y definimos las cuatro operaciones básicas como "operator" dentro de la propia clase:
class fixedpoint_t { public: int32_t v; fixedpoint_t(int32_t x = 0) : v(x << 16) { }; inline fixedpoint_t &operator = (const int32_t &x) { this->v = x << 16; return *this; }; inline fixedpoint_t operator + (const fixedpoint_t &x) { fixedpoint_t ret; ret.v = this->v + x.v; return ret; }; inline fixedpoint_t operator - (const fixedpoint_t &x) { fixedpoint_t ret; ret.v = this->v - x.v; return ret; }; inline fixedpoint_t operator * (const fixedpoint_t &x) { fixedpoint_t ret; ret.v = (((int64_t) this->v) * ((int64_t) x.v)) >> 16; return ret; }; inline fixedpoint_t operator / (const fixedpoint_t &x) { fixedpoint_t ret; ret.v = (((int64_t) this->v) << 16) / ((int64_t) x.v); return ret; }; };
Esta implementación nos permite ahora escribir la misma función de antes de una forma más legible:
fixedpoint_t fWithOperators(fixedpoint_t a, fixedpoint_t b) { return (a * b) + (a / b); }
Y, de la misma manera, también nos permite invocarla de forma más legible:
fixedpoint_t v = fWithOperators(4, 3);
Sin embargo se podría pensar que una implementación así generaría mucho más código que la implementación basada en macros. Hagamos unas pruebas.
Comparativa
Si compilamos con gcc el código de ambas funciones sin opciones de optimización:
g++ -std=c++11 -o fp fp.cc
la diferencia es abismal:
_Z11fWithMacrosii:
push %rbp
mov %rsp,%rbp
push %rbx
mov %edi,-0xc(%rbp)
mov %esi,-0x10(%rbp)
mov -0xc(%rbp),%eax
movslq %eax,%rdx
mov -0x10(%rbp),%eax
cltq
imul %rdx,%rax
sar $0x10,%rax
mov %eax,%ecx
mov -0xc(%rbp),%eax
cltq
shl $0x10,%rax
mov -0x10(%rbp),%edx
movslq %edx,%rbx
cqto
idiv %rbx
add %ecx,%eax
pop %rbx
pop %rbp
retq
_Z14fWithOperators12fixedpoint_tS_:
push %rbp
mov %rsp,%rbp
sub $0x40,%rsp
mov %edi,-0x30(%rbp)
mov %esi,-0x40(%rbp)
lea -0x40(%rbp),%rdx
lea -0x30(%rbp),%rax
mov %rdx,%rsi
mov %rax,%rdi
callq 4009cc <_ZN12fixedpoint_tdvERKS_>
mov %eax,-0x20(%rbp)
lea -0x40(%rbp),%rdx
lea -0x30(%rbp),%rax
mov %rdx,%rsi
mov %rax,%rdi
callq 40098a <_ZN12fixedpoint_tmlERKS_>
mov %eax,-0x10(%rbp)
lea -0x20(%rbp),%rdx
lea -0x10(%rbp),%rax
mov %rdx,%rsi
mov %rax,%rdi
callq 400952 <_ZN12fixedpoint_tplERKS_>
leaveq
retq
El compilador ha hecho caso omiso del "inline" de las funciones miembro de la clase "fixedpoint_t" y las ha implementado como funciones aparte en ensamblador. En este caso la implementación usando macros es más eficiente. Activemos ahora el primer nivel de optimización "-O1":
g++ -std=c++11 -O1 -o fp fp.cc
Voilà, ahora apenas notamos la diferencia en el código generado:
_Z11fWithMacrosii:
movslq %edi,%rax
movslq %esi,%rsi
mov %rax,%rcx
imul %rsi,%rcx
sar $0x10,%rcx
shl $0x10,%rax
cqto
idiv %rsi
add %ecx,%eax
retq
_Z14fWithOperators12fixedpoint_tS_:
movslq %edi,%rdi
movslq %esi,%rsi
mov %rdi,%rax
shl $0x10,%rax
cqto
idiv %rsi
imul %rdi,%rsi
sar $0x10,%rsi
add %esi,%eax
retq
La implementación utilizando la clase "fixedpoint_t" con los operadores sobrecargados genera un código igual de eficiente que la implementación basada en macros.
Como conclusión podemos sacar que no es necesario sacrificar legibilidad en aras de la velocidad de ejecución, siempre y cuando usemos correctamente los elementos del lenguaje y compilemos usando las opciones de optimización adecuadas.
El código fuente puede descargarse de la sección soft.
[ añadir comentario ] ( 4524 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |

 ( 3 / 13163 )
( 3 / 13163 )A la hora de controlador un display LCD mediante el conocido adaptador I2C la gran mayoría de ejemplos disponibles por ahí implementan los estados de espera necesarios mediante retardos explícitos ("delays"). Dichas implementaciones están bien como prueba de concepto, pero no son deseables en entornos multitarea donde no podemos desperdiciar ciclos sólo esperando. En entornos reales se precisa de implementaciones no bloqueantes que hagan uso de timers e interrupciones.
El circuito
La interfaz de un display LCD estándar de caracteres es una interfaz paralelo de 8 bits, con 3 líneas de control adicionales (RS, EN y RW). Del bus paralelo de 8 bits pueden usarse sólo los 4 bits más significativos enviando de forma adecuada los comandos. Los circuitos de conversión a I2C que se venden habitualmente por AliExpress, Ebay y demás están basados en el conversor I2C/paralelo de 8 bits PCF8574 de Texas Instruments: del bus paralelo de dicho conversor se sacan los 4 bits más significativos para el bus paralelo del LCD y las tres señales de control para RS, EN y RW.
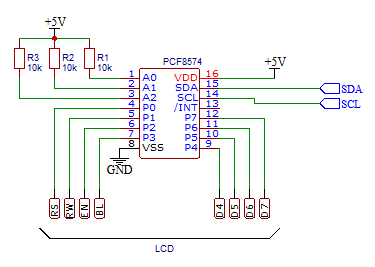
La configuración habitual en este tipo de módulos es esta:
| PCF8574 | bit 7 | bit 6 | bit 5 | bit 4 | bit 3 | bit 2 | bit 1 | bit 0 |
| LCD | D7 | D6 | D5 | D4 | BL | EN | RW | RS |
En la tabla se puede apreciar una cuarta señal de control etiquetada como BL (backlight) que controla el encendido del led de la luz trasera. Dicho led no forma parte de la circuitería estándar del display y ha sido introducido en versiones más recientes.
El problema
Los displays baratos de caracteres LCD que se encuentran en el mercado están basados en en un chip de Hitachi que no se caracteriza precisamente por su velocidad (probablemente debe ser uno de los chips más rentabilizados de toda la historia de Hitachi) y normalmente cada acceso debe estar seguido por una espera de uno a varios microsegundos, dependiendo del acceso realizado. A continuación puede verse la tabla de comandos de referencia del display, nótese la columna de la derecha ("Execution Time"):
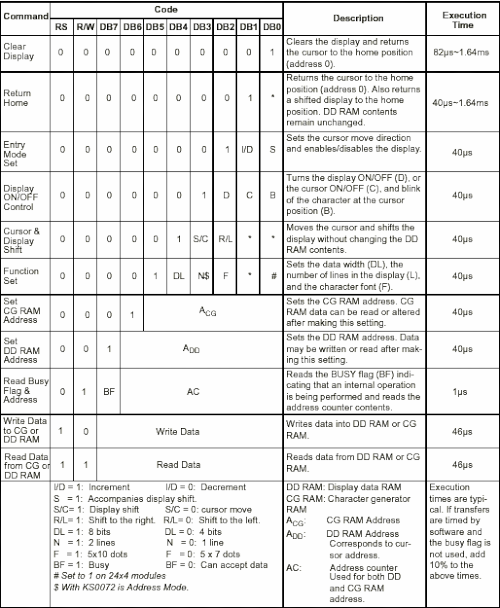
(imagen extraida de https://learningmsp430.wordpress.com/2013/11/13/16x2-lcd-interfacing-in-8bit-mode/)
Cuando uno realiza una búsqueda en internet sobre códigos de ejemplo para control de displays LCD, la gran mayoría de los mismos (no digo todos porque considero que no los he visto todos, pero al menos todos los que yo he visto), implementan las esperas mediante retardos utilizando funciones "delay" o similares. Esta forma de implementación, aunque resulta simple, supone un desperdicio de ciclos e impide que el microcontrolador realice otras tareas de forma concurrente.
La solución no bloqueante
La solución ideal pasaría por una implementación basada en colas y en interrupciones. En este caso se ha implementado una máquina de estados que controla el flujo de datos I2C, el troceado de los bytes en dos nibbles y las esperas que hay que realizar entre un envío y el siguiente. Grosso modo, la solución sería la siguiente:
- Cada vez que se quiere escribir en el display, lo que se hace es escribir lo que se quiere mandar al display en una cola de datos, por lo que la función encargada de escribir regresa inmediatamente (no es bloqueante).
- El systick del microcontrolador cuando detecta que hay algún dato en la cola de datos inicia una máquina de estados que se encarga de trocear en byte en dos nibbles y enviarlos en tiempos diferentes, así hasta que la cola de datos quede vacía, en cuyo momento la máquina de estados pasa a modo "IDLE" y queda a la espera que de haya más datos en la cola.
- La capa I2C también está implementada como una cola de bytes de tal manera que si la capa LCD quiere escribir N bytes seguidos por I2C, los escribe de forma no bloqueante en la cola I2C (la función de escritura I2C también regresa inmediatamente) y se va vaciando a medida que la interrupción de callback de transmisión es llamada por el microcontrolador.
A continuación puede verse cómo ha quedado la máquina de estados del controlador LCD:
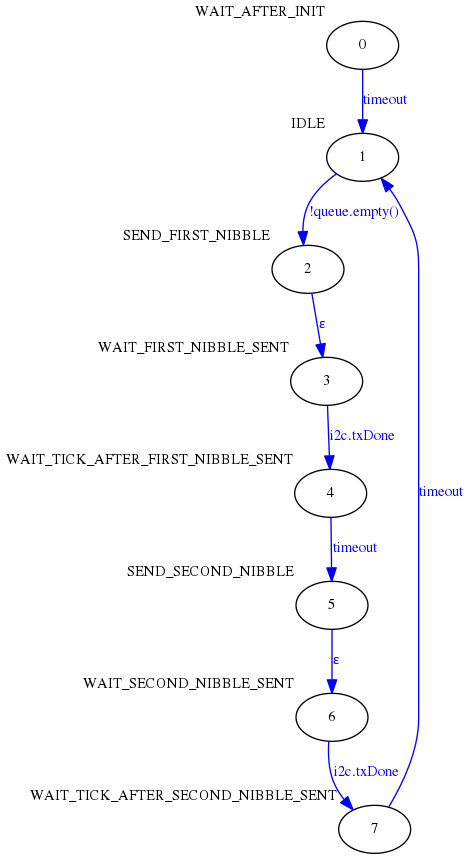
El código no queda tan sencillo a simple vista pero se trata, sin duda, de una implementación más eficiente.
#include "LCD.H" using namespace avelino; using namespace std; void LCD::init(uint8_t address) { this->address = address; this->timerCounter = 5; this->status = LCD::Status::WAIT_AFTER_INIT; this->queue.push(LCD::QueueItem(0x33, LCD::IsCommand::YES)); this->queue.push(LCD::QueueItem(0x32, LCD::IsCommand::YES)); this->queue.push(LCD::QueueItem(0x28, LCD::IsCommand::YES)); this->queue.push(LCD::QueueItem(0x08, LCD::IsCommand::YES)); this->queue.push(LCD::QueueItem(0x01, LCD::IsCommand::YES)); this->queue.push(LCD::QueueItem(0x06, LCD::IsCommand::YES)); this->queue.push(LCD::QueueItem(0x0C, LCD::IsCommand::YES)); } void LCD::tick() { Status localStatus = this->status; do { this->status = localStatus; if (localStatus == LCD::Status::WAIT_AFTER_INIT) { if (this->timerCounter > 0) this->timerCounter--; else localStatus = LCD::Status::IDLE; } else if (localStatus == LCD::Status::IDLE) { if (!this->queue.empty()) { I2CManager::deviceAddress = this->address << 1; localStatus = LCD::Status::SEND_FIRST_NIBBLE; } } else if (localStatus == LCD::Status::SEND_FIRST_NIBBLE) { uint8_t byte = this->queue.head().byte; LCD::IsCommand isCommand = this->queue.head().isCommand; I2CManager::txQueue.push((byte & 0xF0) | ((isCommand == LCD::IsCommand::YES) ? LCD::RS_0 : LCD::RS_1) | LCD::RW_0 | LCD::EN_1 | LCD::BL_1); I2CManager::txQueue.push((byte & 0xF0) | ((isCommand == LCD::IsCommand::YES) ? LCD::RS_0 : LCD::RS_1) | LCD::RW_0 | LCD::EN_0 | LCD::BL_1); I2CManager::send(); localStatus = LCD::Status::WAIT_FIRST_NIBBLE_SENT; } else if (localStatus == LCD::Status::WAIT_FIRST_NIBBLE_SENT) { if (I2CManager::txDone) { this->timerCounter = 1; localStatus = LCD::Status::WAIT_TICK_AFTER_FIRST_NIBBLE_SENT; } } else if (localStatus == LCD::Status::WAIT_TICK_AFTER_FIRST_NIBBLE_SENT) { if (this->timerCounter > 0) this->timerCounter--; else localStatus = LCD::Status::SEND_SECOND_NIBBLE; } else if (localStatus == LCD::Status::SEND_SECOND_NIBBLE) { uint8_t byte = this->queue.head().byte << 4; LCD::IsCommand isCommand = this->queue.head().isCommand; this->queue.pop(); I2CManager::txQueue.push((byte & 0xF0) | ((isCommand == LCD::IsCommand::YES) ? LCD::RS_0 : LCD::RS_1) | LCD::RW_0 | LCD::EN_1 | LCD::BL_1); I2CManager::txQueue.push((byte & 0xF0) | ((isCommand == LCD::IsCommand::YES) ? LCD::RS_0 : LCD::RS_1) | LCD::RW_0 | LCD::EN_0 | LCD::BL_1); I2CManager::send(); localStatus = LCD::Status::WAIT_SECOND_NIBBLE_SENT; } else if (localStatus == LCD::Status::WAIT_SECOND_NIBBLE_SENT) { if (I2CManager::txDone) { this->timerCounter = 1; localStatus = LCD::Status::WAIT_TICK_AFTER_SECOND_NIBBLE_SENT; } } else if (localStatus == LCD::Status::WAIT_TICK_AFTER_SECOND_NIBBLE_SENT) { if (this->timerCounter > 0) this->timerCounter--; else localStatus = LCD::Status::IDLE; } } while (localStatus != this->status); } void LCD::write(const char *s, int16_t size, LCD::IsCommand isCommand) { while ((*s != 0) && ((size < 0) || (size > 0))) { this->queue.push(QueueItem(*s, isCommand)); s++; if (size > 0) size--; } }
La función miembro "tick" es invocada desde la interrupción systick del microcontrolador en "main.cc":
LCD lcd; void systick() __attribute__ ((section(".systick"))); void systick() { lcd.tick(); }
Nótese que las colas (tanto la cola I2C como la cola LCD) están implementadas usando colas circulares estáticas a través de una plantilla ("StaticQueue.H").
#ifndef __STATICQUEUE_H__ #define __STATICQUEUE_H__ #include <stdint.h> extern "C++" { namespace avelino { using namespace std; template <typename T, int32_t N> class StaticQueue { public: T data[N]; int32_t headIndex; int32_t tailIndex; void push(const T &v); const T &head() { return this->data[this->headIndex]; }; void pop(); bool empty() { return (this->headIndex == this->tailIndex); }; StaticQueue() : headIndex(0), tailIndex(0) { }; }; template <typename T, int32_t N> void StaticQueue<T, N>::push(const T &v) { this->data[this->tailIndex] = v; this->tailIndex++; if (this->tailIndex == N) this->tailIndex = 0; } template <typename T, int32_t N> void StaticQueue<T, N>::pop() { this->headIndex++; if (this->headIndex == N) this->headIndex = 0; } } } #endif // __STATICQUEUE_H__
Se ha utilizado en varios sitios el "enum class", que permite trabajar con enumerados fuertemente tipados (introducido en el estándar C++11).
En la sección soft puede descargarse todo el código fuente.
[ añadir comentario ] ( 2981 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
 ( 3 / 13416 )
( 3 / 13416 )En esta primera entrega del podcast he entrevistado a Bartolomé Almeida, un ingeniero de telecomunicaciones que se ha especializado en el estándar LoRa. Nos ha hablado de las diferentes aplicaciones, módulos y librerías disponibles para empezar en el mundo de las comunicaciones a larga distancia usando este estándar.
El episodio 1 está disponible aquí.
La música utilizada es de The Underscore Orkestra. Licencia Creative Commons con atribución.
[ añadir comentario ] ( 2466 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 13874 )Me he estrenado en esto de los podcasts y he decidido empezar a hacer un podcast en español sobre microcontroladores, sistemas embebidos y desarrollo de sistemas digitales.
El episodio 0 está disponible aquí.
La música utilizada es de The Underscore Orkestra. Licencia Creative Commons con atribución.
[ 1 comentario ] ( 2504 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 14207 )Un año más, decorando el belén con nuevos inventos. En esta ocasión he vuelto a los orígenes y he implementado una luz, pero esta vez una luz especial que simule un fuego encendido utilizando un CPLD.
Introducción
A la hora de simular el crepitar de una llamas se ha optado por hacer que un led varíe de luminosidad de forma aleatoria varias veces por segundo.
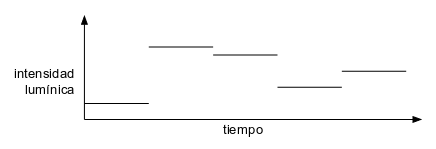
Con una luz que varíe su intensidad lumínica varias veces por segundo (entre 5 y 6 veces por segundo, por ejemplo) más una buena escenografía (color de la luz, decorados, etc.) se consigue un razonable efecto de fuego encendido.
Diseño técnico
Como vamos a hacer el diseño utilizando un circuito totalmente digital, la intensidad lumínica se modulará utilizando una señal cuadrada modulada en anchura (PWM). Cuanto mayor sea el semiciclo a 1 y menor el semiciclo a 0 más brillará el led y a la inversa: cuanto mayor sea el semiciclo a 0 y menor el semiciclo a 1 menos brillará.
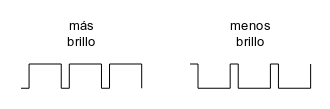
Si hacemos que la frecuencia sea lo suficientemente alta no se apreciará ningún tipo de parpadeo y la luz se percibirá como que brilla de forma continuada pero con diferente intensidad. El CPLD utilizado tiene conectado un reloj a 50 MHz, por tanto usando un contador de 10 bits estándar conseguiremos un desbordamiento a una frecuencia de
$${50000000 \over {2^{10}}} = 48828.125 Hz$$
Si el valor de este contador lo comparamos con un valor determinado, el resultado de esta comparación será la salida PWM que necesitamos para el led de nuestra fogata:
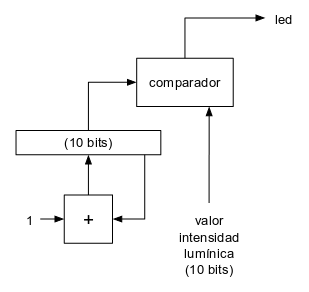
El valor de intensidad lo generaremos mediante un LFSR maximal de 10 bits. Dicho LFSR ha sido utilizado en otros montajes anteriores:
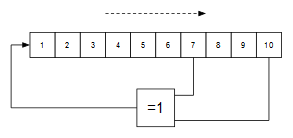
Genera una secuencia maximal de 1023 valores pseudoaleatorios (el valor 0 no aparece en la secuencia) que se puede usar como valor de intensidad lumínica:
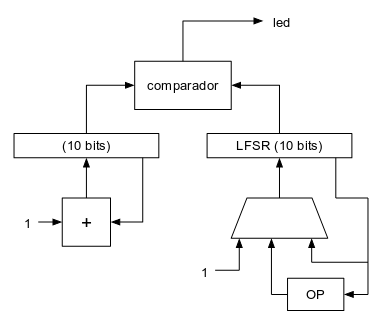
En este circuito el bloque combinacional "OP" es el que implementa el polinomio maximal de 10 bits. A continuación sólo falta implementar la temporización. Como queremos el que valor de intensidad lumínica cambie unas 5 ó 6 veces por segundo, bastará con poner un contador estándar de:
$$\lceil log_2\left({50000000 \over 6}\right) \rceil = 23 bits$$
Con un contador de 23 bits a 50 MHz tendremos una frecuencia de desbordamiento de casi 6 veces por segundo:
$${50000000 \over {2^{23}}} = 5.96 Hz$$
A continuación puede verse cómo quedaría el diagrama completo:
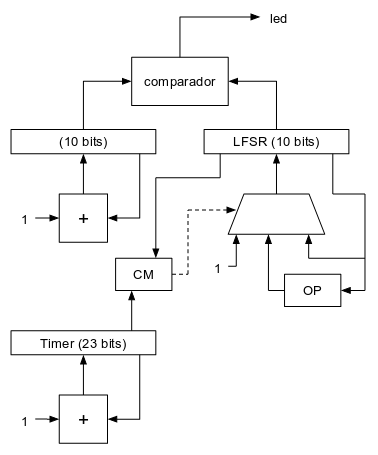
El bloque combinacional "CM" (Control del Multiplexor) se encarga de controlar la selección del multiplexor del LFSR en función del timer contador de 23 bits y del valor del propio LFSR. La tabla de verdad de este bloque sería la siguiente:
| Entradas | Salidas | |
|---|---|---|
| Timer == 0 | LFSR == 0 | MUX |
| X | 1 | "1" |
| 1 | 0 | Salida de OP |
| 0 | 0 | Salida del LFSR |
Cuando el valor del LFSR es 0, lo que hace es seleccionarla entrada "1" del multiplexor para que el LFSR se cargue con un valor distinto de cero (el 1) y poder así arrancar la generación de números aleatorios. Cuando el timer (contador de 23 bits) se desborda (pasa por cero) el LFSR se carga con el siguiente valor de la secuencia de números pseudoaleatorios y el resto del tiempo (valor del contador de 23 bits diferente de 0) el registro LFSR permanece inalterado.
Como se puede apreciar, se ha prescindido de circuitería de reset. Teniendo en cuenta que el objetivo es minimizar la circuitería y que los fabricantes siempre te garantizan que en el arranque, todos los biestables están a 0, se puede "abusar" de esta característica y ahorrar así parte de la circuitería de reset.
Posibles mejoras
Como se puede apreciar, del contador que hace de timer (el de 23 bits) sólo nos interesa cuando pasa por un valor concreto (el 0), no es como el contador que se utiliza para comparar con el LFSR y generar la señal PWM. Teniendo esto presente, dicho contador de 23 bits podría implementarse utilizando también un LFSR maximal de 23 bits: en lugar de un sumador, se puede implementar un bloque combinacionar consistente tan solo en una única puerta xor (ver polinomio a aplicar aquí), lo que supone un ahorro considerable en circuitería.
Hay que tener presente que los LFSRs no pasan nunca por cero, por lo que habría que elegir cualquier otro valor (cualquiera) como valor de "desbordamiento" (el valor 1, por ejemplo).
Implementación
A continuación puede verse la implementación de este diseño en VHDL.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity ChristmasFire is port ( Clk : in std_logic; Led : out std_logic ); end entity; architecture RTL of ChristmasFire is signal CounterDBus : std_logic_vector(9 downto 0); signal CounterQBus : std_logic_vector(9 downto 0); signal LFSRDBus : std_logic_vector(9 downto 0); signal LFSRQBus : std_logic_vector(9 downto 0); signal TimerDBus : std_logic_vector(22 downto 0); signal TimerQBus : std_logic_vector(22 downto 0); signal TimerOverflow : std_logic; begin -- pwm counter process (Clk) begin if (Clk'event and (Clk = '1')) then CounterQBus <= CounterDBus; end if; end process; CounterDBus <= std_logic_vector(signed(CounterQBus) + to_signed(1, 10)); -- lfsr process (Clk) begin if (Clk'event and (Clk = '1')) then LFSRQBus <= LFSRDBus; end if; end process; LFSRDBus <= std_logic_vector(to_signed(1, 10)) when (signed(LFSRQBus) = to_signed(0, 10)) else ((LFSRQBus(3) xor LFSRQBus(0)) & LFSRQBus(9 downto 1)) when (TimerOverflow = '1') else LFSRQBus; -- timer process (Clk) begin if (Clk'event and (Clk = '1')) then TimerQBus <= TimerDBus; end if; end process; TimerDBus <= std_logic_vector(signed(TimerQBus) + to_signed(1, 23)); TimerOverflow <= '1' when (signed(TimerQBus) = to_signed(0, 23)) else '0'; -- output Led <= '1' when (signed(CounterQBus) > signed(LFSRQBus)) else '0'; end architecture;
Se trata de un único fichero que puede descargarse desde la sección soft.
¡Feliz Navidad a todos!
[ añadir comentario ] ( 2407 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 11620 ) Calendario
Calendario




