
Analizaremos dos aproximaciones polinómicas: La serie de Taylor y la aproximación de Padé (esta última se trata realmente de una aproximación racional).
Serie de Taylor
Lo primero que se le suele venir a uno a la cabeza cuando piensa en aproximaciones polinómicas suele ser la serie de Taylor, dicha serie es muy sencilla de calcular y genera una buena aproximación en el entorno de un punto. En este caso se ha optado por aproximar la función exponencial en el entorno de x=0:
$$e^{x} \simeq 1 + {x \over 1!} + {x^2 \over 2!} + {x^3 \over 3!} + ...$$
Esto nos da una muy buena aproximación, aunque para conseguir un error aceptable, es necesario calcular la serie de Taylor para un orden relativamente alto. El error con respecto a la función exp de la librería matemática de C comienza a ser asumible a partir del orden 6 trabajando en coma flotante.
Aproximación de Padé
La aproximación de Padé de orden (m, n) es la función racional:
$$R(x) = {p_0 + p_{1}x + p_{2}x^2 + ... + p_{m}x^m \over 1 + q_{1}x+ q_{2}x^2 + ... + q_{n}x^n}$$
Que cumple que:
$$f(0) = R(0)$$
$$f'(0) = R'(0)$$
$$f''(0) = R''(0)$$
$$...$$
$$f^{(m+n)}(0) = R^{(m+n)}(0)$$
El cálculo de los coeficientes de Padé no es trivial y existen varias técnicas para obtenerlos, como el algoritmo Epsilon de Wynn o el algoritmo euclídeo extendido para el cálculo del máximo común divisor. Por suerte, para la función exponencial, podemos consultar las tablas de Padé que ya se encuentran en internet calculadas para diferentes órdenes (valores de m y de n):
Aquí una tabla publicada en wikipedia.
Se ha optado en este caso por utilizar la aproximación de Padé de orden [3 / 3] (m = n = 3).
A continuación puede verse una implementación en C de ambas aproximaciones.
double taylor_exp(double x) { double ret = 0; int i; double num = 1; double den = 1; for (i = 0; i <= 6; i++) { ret += num / den; num *= x; den *= (i + 1); } return ret; } double pade_exp(double x) { double x2 = x * x; double x3 = x2 * x; double num = 1 + (x / 2) + (x2 / 10) + (x3 / 120); double den = 1 - (x / 2) + (x2 / 10) - (x3 / 120); return num / den; }
Como puede apreciarse, la serie de Taylor es de orden 6, mientras que la aproximación de Padé que se ha implementado es la de orden [3 / 3]. A continuación se reproduce la salida de una prueba de ambas funciones comparándolas con la función exp de la librería matemática:
# ./taylor_vs_pade_float
exp(0.250000):
exp() function : 1.2840254167
6th order taylor : 1.2840254042
3rd order pade : 1.2840254175
Como puede verse, la aproximación de Padé consigue un error comparable al de la serie de Taylor con muchas menos operaciones.
Utilizar aritmética de punto fijo
Ahora que están ambos algoritmos implementados en coma flotante, pasaremos el cálculo a aritmética de punto fijo en formato Q16.16 (más info sobre la notación Q). En el formato Q16.16 tenemos 16 bits para la parte entera y 16 bits para la parte fraccionaria, en total 32 bits.
typedef int32_t fixedpoint_t; #define FP_NEG(x) (-(x)) #define FP_ADD(x, y) ((x) + (y)) #define FP_SUB(x, y) ((x) - (y)) #define FP_MUL(x, y) ((int32_t) (((int64_t) (x)) * ((int64_t) (y)) >> 16)) #define FP_DIV(x, y) ((int32_t) ((((int64_t) (x)) << 16) / ((int64_t) (y)))) #define TO_FP(x) ((int32_t) ((x) << 16)) #define FROM_FP(x) ((x) >> 16) #define FP_FRACTIONAL_BITS 16
Las funciones anteriores puede ser ahora reescritas para utilizar el formato Q16.16:
fixedpoint_t taylor_exp(fixedpoint_t x) { fixedpoint_t ret = 0; int i; fixedpoint_t num = TO_FP(1); fixedpoint_t den = TO_FP(1); for (i = 0; i <= 6; i++) { ret = FP_ADD(ret, FP_DIV(num, den)); num = FP_MUL(num, x); den = FP_MUL(den, FP_ADD(TO_FP(i), TO_FP(1))); } return ret; } fixedpoint_t pade_exp(fixedpoint_t x) { fixedpoint_t x2 = FP_MUL(x, x); fixedpoint_t x3 = FP_MUL(x2, x); fixedpoint_t num = FP_ADD(TO_FP(1), FP_ADD(FP_DIV(x, TO_FP(2)), FP_ADD(FP_DIV(x2, TO_FP(10)), FP_DIV(x3, TO_FP(120))))); fixedpoint_t den = FP_ADD(FP_SUB(FP_DIV(x2, TO_FP(10)), FP_DIV(x3, TO_FP(120))), FP_SUB(TO_FP(1), FP_DIV(x, TO_FP(2)))); return FP_DIV(num, den); }
En este caso, realizando la misma prueba obtenemos resultados algo peores (debido a la pérdida de precisión inherente al uso del punto fijo) y, aunque para las dos aproximaciones obtenemos el mismo valor, la aproximación de Padé requiere menor cantidad de operaciones que la serie de Taylor.
# ./taylor_vs_pade_fixed
exp(0.250000):
exp() function : 1.2840254167
6th order taylor : 1.2839965820
3rd order pade : 1.2839965820
La aproximación de Padé, como ha podido verse, da mejores resultados que las series de Taylor como aproximación a la función exponencial, tanto desde el punto de vista de la eficiencia como de la precisión.
[ añadir comentario ] ( 4603 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |


 ( 3 / 4534 )
( 3 / 4534 )La multitarea es la capacidad que tienen los sistemas de realizar varias tareas o procesos de forma simultánea en el tiempo. En el ámbito de los sistemas grandes o de sistemas embebidos avanzados esta capacidad viene dada normalmente por un pequeño sistema operativo encargado de gestionar dicha multitarea y de crear una capa de abstracción entre los procesos y el hardware (Linux embebido, eCos, Windows CE, etc.). En sistemas embebidos pequeños con procesadores más modestos (ya sea por anchura de bus, por RAM o por ambas razones) la cosa cambia: No tenemos sistema operativo y la multitarea debe ser gestionada por el propio software.
Vamos a asumir que todas las tareas que queremos planificar son igual de prioritarias y, por lo tanto, utilizaremos una planificación estilo round-robin (la más simple).
Multitarea apropiativa.
En la multitarea apropiativa, el proceso principal (voy a resistirme a utilizar el concepto de sistema operativo) se encarga de distribuir el tiempo de CPU entre las diferentes tareas. Si una tarea se cuelga o comienza a consumir muchos recursos, el resto de tareas no tiene por qué verse afectado ya que el software principal le quita el control de la CPU a las tareas sin importarle lo que estén haciendo en ese momento.
Es el tipo de multitarea ideal para evitar cuelgues completos del sistema y al mismo tiempo es el que más restricciones técnicas tiene.
- El sistema debe permitir proteger ciertas funciones o instrucciones para que no puedan ser ejecutadas por las tareas.
- Normalmente es necesario realizar manipulaciones de la pila del sistema.
- Se suelen utilizar timers para controlar el tiempo de CPU que tiene cada tarea.
Un esqueleto muy básico de lo que sería implementar multitarea apropiativa en un sistema embebido pequeño sería el siguiente:
class Tarea { public: bool enEjecucion; Estado estado; Tarea *siguiente; Tarea() { this->enEjecucion = false; }; virtual void run() = 0; }; Tarea *tareaInicial; Tarea *tareaActual = NULL; void leerEstadoActual(Tarea *t) { // se lee de la pila del sistema el estado de los registros en el momento de la interrupción y se guarda en t->estado } void escribirEstadoActual(Tarea *t) { if (!t->enEjecucion) { // hay que inicializar t->estado para que cada tarea tenga su propia pila y para que el contador de programa apunte a la primera instrucción de t->run t->enEjecucion = true; } // se sobreescribe en la pila del sistema el estado de los registros guardado en t->estado } void isr() { if (tareaActual != NULL) { leerEstadoActual(tareaActual); tareaActual = tareaActual->siguiente; } else tareaActual = tareaInicial; // este "if" sobra si las tareas se meten en una lista circular if (tareaActual == NULL) tareaActual = tareaInicial; escribirEstadoActual(tareaActual); } int main() { configurarISRTimer(isr); configurarYLanzarTimer(); while (true) ; return 0; }
En los comentarios de leerEstadoActual y escribirEstadoActual puede apreciarse el nivel de complejidad que requiere este tipo de multitarea: Es necesario conocer bien cómo funciona el mecanismo de interrupciones en el procesador en el que estamos así como controlar bien el layout de la memoria para cada tarea (pila, código, datos, etc.). En un sistema embebido normalmente no tenemos instrucciones protegidas con lo que nada impedirá que una de las tareas se apropie del ISR del timer que estamos utilizando para planificar y se nos fastidie el invento. Algo parecido ocurriría si alguna de las tareas decide deshabilitar la interrupción del timer: Se hará con el control completo de la CPU.
Multitarea cooperativa.
La multitarea cooperativa consiste en que cada tarea cede voluntariamente el procesador a otras tareas. Es el tipo de multitarea más sencillo de implementar, también puede ser más problemático ya que, si una tarea ocupa demasiado tiempo de procesador (ya sea por un error, por una condición mal evaluada o por una mala praxis de programación) el resto de tareas se ejecutarán, en el mejor de los casos, de forma menos eficiente y en el peor de los casos dejarán de ejecutarse. Sin embargo en los sistema embebidos pequeños normalmente podemos controlar bien todas las tareas que están en ejecución, y, si realizamos un buen diseño, podemos conseguir muy buenos resultados.
Una multitarea cooperativa con planificación simple estilo round-robin quedaría como sigue:
class Tarea { public: virtual void init() = 0; virtual void run() = 0; }; class Tarea1 : public Tarea { ... }; class Tarea2 : public Tarea { ... }; Tarea1 t1; Tarea2 t2; int main() { t1.init(); t2.init(); while (true) { t1.run(); t2.run(); } }
O, de forma más genérica, utilizando una lista simplemente enlazada de tareas:
class Tarea { public: Tarea *siguiente; virtual void init() = 0; virtual void run() = 0; }; ... int main() { Tarea *t = TAREA_INICIAL; while (t != NULL) { t->init(); t = t->siguiente; } while (true) { t = TAREA_INICIAL; while (t != NULL) { t->run(); t = t->siguiente; } } }
Como se puede ver no accedemos ni a la pila del sistema ni a características que requieran un conocimiento profundo de la arquitectura o del procesador que estamos utilizando. Esto hace que el código resultante sea más fácilmente portable a otros sistemas. Como contrapartida tenemos que asegurarnos de que ningún método run estrangule mucho al procesador.
Donde más podemos estrangular al resto de tareas es:
- En tiempos de espera para entrada/salida.
- En algoritmos pesados.
Desbloquear tareas de entrada y salida.
Las tareas que realizan entrada/salida suelen requerir de tiempos de espera para completarse. Pensemos en una comunicación serie a 9600 bps. Si tenemos que crear una clase UART con el método write una primera aproximación sería la siguiente:
void UART::write(uint8_t *data, uint16_t size) { for (uint16_t j = 0; j < size; j++) { while (!BUFFER_UART_TX_VACIO) ; BUFFER_UART = data[j]; } while (!BUFFER_UART_TX_VACIO) ; }
Llamar al método UART::write() desde el método run de alguna de las tareas estrangulará, claramente al resto de tareas ya que la tarea desde la que se llame no regresará del run hasta que, como mínimo, se envíe el buffer completo de bytes. Hay que tener en cuenta lo siguiente: Si queremos transmitir 64 bytes y nuestra UART manda un bit de start y otro de stop, realmente está enviando 10 bits por cada byte, lo que hacen un total 640 bits. A 9600 bps, 640 bits tardan 0.067 segundos. Es poco en términos humanos, pero si pensamos que un procesador RISC a 16 MHz (un PIC o un AVR de gama media) ejecuta 16 millones de instrucciones por segundo (una instrucción cada 0.0000000625 segundos), esperar 0.067 segundos supone un estrangulamiento del resto de tareas.
¿Qué hacemos en estos casos? Muy sencillo, utilizar un modelo de estados. Podemos crear una tarea adicional encargada de gestionar la transmisión UART y definirla así:
class UART : public Tarea { protected: uint8_t estado; uint8_t *bufferEnvio; uint16_t indiceBufferEnvio; uint16_t tamBufferEnvio; public: UART(); void init(); void run(); bool escribir(uint8_t *buffer, uint16_t tam); }; #define ESTADO_UART_OCIOSO 0 #define ESTADO_UART_ESPERAR_BUFFER_TX_VACIO 1 #define ESTADO_UART_ESCRIBIR_BYTE 2 UART::UART() { this->estado = ESTADO_UART_OCIOSO; this->bufferEnvio = NULL; } void UART::init() { this->bufferEnvio = NULL; this->estado = ESTADO_UART_OCIOSO; } void UART::run() { if (this->estado == ESTADO_UART_OCIOSO) { if (this->bufferEnvio != NULL) this->estado = ESTADO_UART_ESPERAR_BUFFER_TX_VACIO; } else if (this->estado == ESTADO_UART_ESPERAR_BUFFER_TX_VACIO) { if (BUFFER_UART_TX_VACIO) this->estado = ESTADO_UART_ESCRIBIR_BYTE; } else if (this->estado == ESTADO_UART_ESCRIBIR_BYTE) { if (this->indiceBufferEnvio == this->tamBufferEnvio) { this->estado = ESTADO_UART_OCIOSO; this->bufferEnvio = NULL; } else { BUFFER_UART = this->bufferEnvio[this->indiceBufferEnvio]; this->indiceBufferEnvio++; this->estado = ESTADO_UART_ESPERAR_BUFFER_TX_VACIO; } } } bool UART::escribir(uint8_t *buffer, uint16_t tam) { if (this->estado == ESTADO_UART_OCIOSO) { this->tamBufferEnvio = tam; this->indiceBufferEnvio = 0; this->bufferEnvio = buffer; return true; } else return false; }
Ahora incluimos nuestra tarea UART (que hemos heredado de la clase Tarea) como una tarea más a ser planificada: Invocamos su método init antes de comenzar y luego, en el bucle infinito invocamos su método run junto con el resto de métodos run del resto de tareas:
UART uart; int main() { t1.init(); t2.init(); uart.init(); while (true) { t1.run(); t2.run(); uart.run(); } }
A priori puede resultar un poco lioso desbloquear las tareas bloqueantes de esta forma, mediante máquinas de estados que generan más código, pero a la larga mejora el rendimiento general de la aplicación y es más sencillo adaptar el código para que funcione mediante interrupciones: con muy poco esfuerzo se puede adaptar el método run para convertirlo en una rutina de interrupción (ISR) que atienda la tranmisión UART.
Espero que este post haya servido de ayuda. Los últimos códigos fuente en C++ que he publicado para Arduino (el último de las luces del belén y el del tres en raya) utilizan multitarea cooperativa.
[ añadir comentario ] ( 2663 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4122 )El año pasado por estas mismas fechas planteé y desarrollé unas luces para el belén controladas por una placa Arduino y que generaban una cadencia de destellos en función de la luz ambiente: a menor luz ambiente, más destellos y a mayor luz ambiente, menos destellos. Este año he planteado y desarrollado una segunda revisión un poco más avanzada del concepto de luces del belén.
Aspectos funcionales
La idea es que las luces del belén varíen sus destellos, no en función de la luz ambiente, sino en función de la hora que sea en cada momento. Es preciso definir lo que se entiende por día y por noche (en intervalo horario) y se debe especificar un patrón de comportamiento de las luces para cada uno de esos intervalos horarios.
Lo que he hecho en este caso es definir, para cada tramo horario, la probabilidad de que una luz cualquiera de las 5 brille. Dicha probabilidad será de 0.1 cuando estemos en el intervalo horario que hemos definido como día y de 0.8 cuando estemos en el intervalo horario que hemos definido como noche.
Aspectos técnicos
El problema es principalmente saber cuándo estamos en el intervalo horario día y cuándo estamos en el intervalo horario noche. Para ello, he recurrido al circuito desarrollado en el anterior post, en el que conecté un chip RTC (el clásico DS1307) a la placa Arduino mediante el bus I2C.
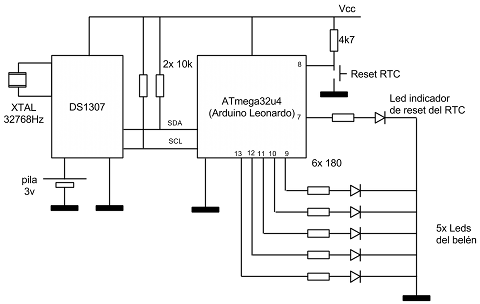
El circuito consta de varias partes:
- Por un lado tenemos la parte del reloj RTC con los dos hilos del bus I2C interconectando el Arduino y el DS1307 (SDA y SCL). El chip RTC tiene conectada una pila para mantener la hora cuando el resto del circuito esté apagado y un cristal de cuarzo de 32768Hz necesario para que el reloj sea preciso.
- Por otro lado tenemos las luces en sí: 5 leds blancos de alta luminosidad.
- Y finalmente tenemos un pulsador y un led adicional etiquetados como Reset RTC y Led indicador de reset del RTC respectivamente. El pulsador sirve para reiniciar la hora del RTC a las 00:00 (para ponerlo en hora, vamos) y el led indica que se ha puesto en hora de forma satisfactoria. Este último led se deja en la misma placa, no forma parte de las luces parpadeantes del belén. Para evitar que pulsaciones accidentales cambien la hora del chip RTC, es necesario mantener pulsado el botón al menos 2 segundos para que tenga efecto.
Las clases I2C y RTC desarrolladas en el post anterior han tenido que ser readaptadas para hacerlas no bloqueantes (básicamente usando autómatas). Las principales clases son las siguientes:
ADCManager: Es una utility class que permite leer las entradas analógicas. Se utiliza para inicializar el generador de números pseudoaleatorios.
I2C: Otra utility class para gestionar la comunicación a través del bus I2C del microcontrolador (SDA y SCL). Incluye un autómata para controlar los estados de espera del bus.
RTC: Es otra utility class que llama internamente a los métodos de I2C utilizando comandos específicos del RTC DS1307.
RTCListener: Es una clase abstracta que debe ser implementada por aquel objeto que desee ser avisado cada vez que cambia la hora.
RTCObserver: Una utility class encargada de consultar el RTC cada 250 milisegundos y de avisar al objeto que implemente RTCListener cada vez que cambie la hora. Lo he hecho así para no estresar el RTC.
StarsManager: Es la clase encargada de generar los destellos. Hereda de RTCListener y, cada vez que cambia la hora, comprueba en qué intervalo se encuentra (día o noche) y modifica, si procede, la probabilidad de destello de los leds del belén.
Todo el código fuente, en C++, puede ser descargado de la sección soft. Para compilar el proyecto sólo es necesario tener instalada la toolchain de GNU para AVR, dicha toolchain se instala junto con el resto de software que viene con el Arduino. Sólo hay que revisar el fichero Makefile y cambiar las rutas para adecuarlas a la ruta de instalación que tengamos en nuestro ordenador.

[ añadir comentario ] ( 2874 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4061 )Los microcontroladores AVR poseen una interface de bus I2C que permite conectarlos a EEPROMs, RTCs, DACs y muchos otros periféricos. El bus I2C es un estándar ampliamente utilizado para la interconexión de dispositivos a bajo nivel y en este post analizaré cómo conectar un microcontrolador AVR (presentes en la familia Arduino) con un chip RTC (Real Time Clock) utilizando este bus I2C.
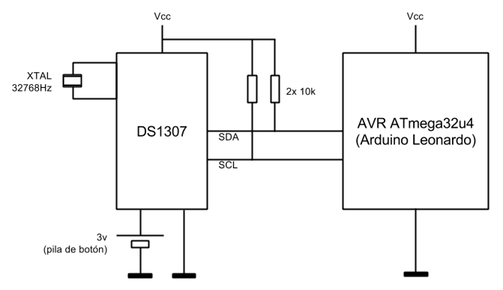
La inicialización del bus I2C la podemos encapsular dentro de una clase estática:
#include "I2C.h" #include <stdint.h> #include <avr/io.h> using namespace avelino; using namespace std; void I2C::init() { TWSR = 0x00; // TWBR = 12; // 400KHz TWBR = 72; // 100KHz TWCR = (1 << TWEN); } void I2C::start() { TWCR = (1 << TWINT) | (1 << TWSTA) | (1 << TWEN); while ((TWCR & (1 << TWINT)) == 0) ; } void I2C::stop() { TWCR = (1 << TWINT) | (1 << TWSTO) | (1 << TWEN); } void I2C::write(uint8_t v) { TWDR = v; TWCR = (1 << TWINT) | (1 << TWEN); while ((TWCR & (1<<TWINT)) == 0) ; } uint8_t I2C::readACK() { TWCR = (1 << TWINT) | (1 << TWEN) | (1 << TWEA); while ((TWCR & (1 << TWINT)) == 0) ; return TWDR; } uint8_t I2C::readNACK() { TWCR = (1 << TWINT) | (1 << TWEN); while ((TWCR & (1 << TWINT)) == 0) ; return TWDR; } uint8_t I2C::getStatus() { return (TWSR & 0xF8); }
En este caso configuramos la velocidad I2C a 100KHz ya que es la velocidad a la que trabaja el chip RTC DS1307.
A continuación podemos definir otra clase estática para acceder al RTC:
#include "RTC.h" #include "I2C.h" using namespace avelino; using namespace std; void RTC::init() { I2C::init(); // read halt bit I2C::start(); I2C::write(0xD0); I2C::write(0x00); I2C::start(); I2C::write(0xD1); uint8_t v = I2C::readNACK(); I2C::stop(); if ((v & 0x80) != 0) { // clock is disabled, enabling I2C::start(); I2C::write(0xD0); I2C::write(0x00); I2C::write(v & 0x7F); I2C::stop(); } } void RTC::read(uint8_t &hour, uint8_t &minute, uint8_t &second) { I2C::start(); I2C::write(0xD0); I2C::write(0x00); I2C::start(); I2C::write(0xD1); second = I2C::readACK(); minute = I2C::readACK(); hour = I2C::readNACK(); I2C::stop(); }
El método init, tras inicializar el bus I2C, consulta la dirección de memoria 0 del RTC que, además del secundero del reloj, también almacena el halt bit (bit 7). Este bit se encuentra a 1 de fábrica y debe ser puesto a 0 para que el RTC arranque. En el if se comprueba si este bit está a 1, si es así, se pone a 0.
Por ahora no nos estamos preocupando de la hora real. Cuando el DS1307 se activa comienza a contar como si fuesen las 0:00 horas de 1 de enero de 2000.
A continuación, para ver que el RTC funciona bien, podemos hacer un sencillo programa que cambie el estado del led de la placa Arduino por cada segundo que pasa:
#include <stdint.h> #include "Led.h" #include "RTC.h" using namespace avelino; using namespace std; uint8_t hour, minute, second, prevSecond; int main() { RTC::init(); Led::init(); while (1) { RTC::read(hour, minute, second); if (second != prevSecond) { Led::change(); prevSecond = second; } } }
Voilà, ya tenemos nuestro microcontrolador conectado al reloj de tiempo real.
[ añadir comentario ] ( 2645 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4103 )Partiendo del diseño hardware de los leds y los interruptores multiplexados realizado en anteriores posts de este blog he realizado una implementación tonta del juego de tres en raya.
Aspectos funcionales
La idea es realizar un juego de tres en raya utilizando la matriz de 3x3 leds en combinación con la matriz de 3x3 pulsadores descritas ambas en post anteriores. Esta implementación inicial tiene las siguientes características y limitaciones:
- El microcontrolador utiliza un algoritmo tonto para realizar movimientos: elige aleatoriamente sobre qué celda jugar en cada turno.
- Siempre comienza jugando el microcontrolador.
- En lugar de círculos y aspas utilizamos la marca luz fija y luz parpadeante. El microcontrolador juega siempre con luz parpadeante.
- En cuanto el juego termina (ya sea porque gana el microcontrolador, porque gana el jugador o porque quedan en tablas), el juego se para.
El funcionamiento es el siguiente:
- Tras el reset, el microcontrolador mueve y marca una casilla del tablero (el microcontrolador siempre juega con la marca luz parpadeante).
- El microcontrolador espera a que el jugador humano mueva activando el pulsador correspondiente a la casilla que quiere marcar.
- Al activar el pulsador, se marca el led correspondiente como luz fija e inmediatamente después, el microcontrolador vuelve a mover.
Así sucesivamente hasta que gane uno de los dos jugadores o el juego quede en tablas. Como se puede adivinar, al ser el jugador de la máquina un jugador tonto que elige sus movimientos de forma aleatoria, es muy fácil ganar :-). En sucesivas versiones intentaré ir mejorando la inteligencia del microcontrolador.
Diagrama de clases
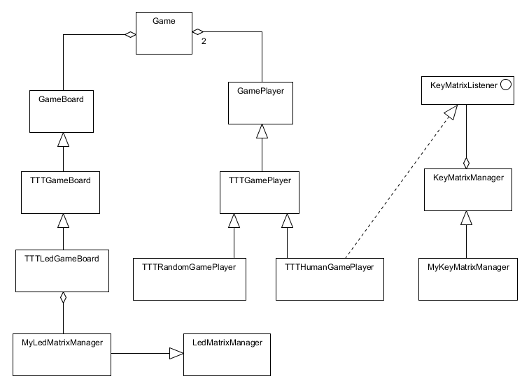
Las principales clases serían las siguientes:
Game: Se encarga de la mecánica abstracta de cualquier juego de dos jugadores, los turnos, quién gana, etc.
GameBoard: Tablero de cualquier juego (abstracto).
TTTGameBoard: Tablero del juego del tres en raya.
TTTLedGameBoard: Tablero del juego del tres en raya especializado en visualizar su estado en la matriz de leds.
GamePlayer: Jugador de cualquier juego (abstracto).
TTTGamePlayer: Jugador del juego del tres en raya.
TTTRandomGamePlayer: Jugador tonto del tres en raya. Elige los movimientos aleatoriamente.
TTTHumanGamePlayer: Jugador humano del tres en raya. Elige los movimientos leyéndolos de la matriz de pulsadores.
A continuación, se puede ver la rutina principal. Se utilizan dos estados de juego ("jugando" y "terminado"):
#include "util.H" #include "Timer.H" #include "MyLedMatrixManager.H" #include "MyKeyMatrixManager.H" #include "TTTRandomGamePlayer.H" #include "Game.H" #include "TTTHumanGamePlayer.H" #include "TTTLedGameBoard.H" using namespace std; using namespace avelino; #define GAME_STATUS_PLAYING 1 #define GAME_STATUS_FINISHED 2 MyLedMatrixManager ledMatrixManager; MyKeyMatrixManager keyMatrixManager; TTTRandomGamePlayer p1; TTTHumanGamePlayer p2; Game g; TTTLedGameBoard board; uint8_t gameStatus; int main() { Timer::init(); ledMatrixManager.init(); board.init(ledMatrixManager); p1.init(1, board); p2.init(2, board); keyMatrixManager.init(p2); g.init(p1, p2, board); gameStatus = GAME_STATUS_PLAYING; while (true) { ledMatrixManager.run(); if (gameStatus == GAME_STATUS_PLAYING) { if (!g.isFinished()) { keyMatrixManager.run(); g.run(); board.show(); } else gameStatus = GAME_STATUS_FINISHED; } else if (gameStatus == GAME_STATUS_FINISHED) { // } } return 0; }
Consideraciones adicionales a tener en cuenta
La generación de números aleatorios
Para la implementación de la clase TTTRandomGamePlayer (el jugador tonto) se necesitan las funciones srand y rand de la librería estándar de C (u otras similares). En lugar de la clásica solución
srand(time(NULL));
que no puede ser utilizada en este caso ya que el sistema carece de reloj de tiempo real, opté por utilizar como semilla aleatoria la lectura de una de las entradas analógicas del microcontrolador que se encuentra sin cablear (al aire):
ADCManager::init();
srand(ADCManager::get(0));
Siendo ADCManager una clase con dos métodos estáticos: init inicializa el subsistema de conversión analógico-digital del microcontrolador y get lee la entrada analógica que se le pasa por parámetros.
Evaluación del tablero
La evaluación del tablero del tres en raya para determinar quién ha ganado tras cada movimiento la he implementado basándome en el algoritmo descrito en el documento A general algorithm for tic-tac-toe board evaluation del profesor Aaron Gordon (departamento de ciencias de la computación y sistemas de información de la universidad de Fort Lewis, Estados Unidos). Dicho algoritmo organiza la cuadrícula de 3x3 en forma de cuadrado mágico: un cuadrado en el que la suma de las columnas, las filas y las diagonales siempre da el mismo resultado. El algoritmo es muy ingenioso y eficiente y para entenderlo bien vale la pena leerse el artículo (aunque está en inglés, es muy sencillo de leer y se entiende perfectamente). De todas formas, en un futuro post abordaré el estudio de este interesante algoritmo.
En la sección soft puede descargarse el código fuente del proyecto.
[ 2 comentarios ] ( 3388 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 4063 ) Calendario
Calendario




