
Orange Pi Zero Plus
El corazón de la placa Orange Pi Zero Plus (la que se ha utilizado para esta prueba de concepto) es un SoC H5 de la marca AllWinner. Se trata de un ARM Cortex-A53 de cuadruple núcleo que implementa la arquitectura ARMv8-A (64 bits). En el arranque, todos los ARM de 64 bits arrancan en modo 32 bits, así que por simplicidad se ha decidido que la prueba de concepto se haga en el modo de arranque compatible ARMv7-A (32 bits, sin pasar a modo 64 bits) y utilizando sólo el primer núcleo (en el arranque sólo está operativo el núcleo 0, los núcleos 1, 2 y 3 están desactivados).
La secuencia de arranque del H5
El H5 implementa varias formas y modos de arranque, sin embargo, en la placa Orange Pi Zero Plus el modo de arranque que se usa es el que busca en la tarjeta de memoria (MicroSD) el bootloader. En el caso habitual, para cargar un sistema operativo, dicho bootloader sera el U-Boot u otro similar. Aunque en el manual de usuario del H5 se especifica de forma más detallada, se puede simplificar diciendo que al arrancar el H5 ejecuta una "boot ROM" (BROM) que no es modificable y que se encuentra cableada dentro del chip. Esta ROM se encarga de inicializar la tarjeta de memoria, de cargar el SPL (Second Program Loader) desde la tarjeta de memoria en la RAM y de ejecutar dicho código una vez está cargado en RAM. En terminología H5 este SPL hace las veces de boot loader.
En http://linux-sunxi.org/Bootable_SD_card#SD_Card_Layout se especifica la distribución de los datos en la tarjeta de memoria, dónde debe estar alojado el SPL (offset 8192) y lo que puede ocupar como máximo (32 KBytes). Según la documentación oficial (http://linux-sunxi.org/BROM#U-Boot_SPL_limitations), este SPL no puede ser código tal cual, sino que debe tener un formato y una especie de firma digital especial. Dicho formato se encuentra documentado y un programador desarrolló hace tiempo una pequeña utilidad llamada "mksunxiboot", open source, programada en C, que, a partir de un binario estándar, genera un binario firmado y reconocible por parte del SoC como un SPL válido (la firma no deja de ser una estructura de datos en la cabecera más un checksum). El código fuente de dicha utilidad (es un único fichero en C) se puede encontrar en https://github.com/amery/mksunxiboot/.
Haciendo nuestro propio SPL
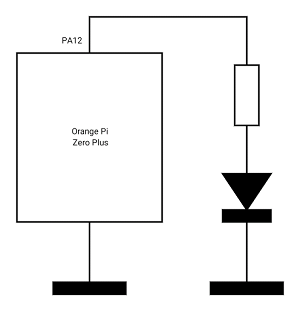
Para hacer la prueba de concepto bare metal bastará con hacer un pequeño programa que haga de SPL. En este caso se ha optado por hacer el típico blinker que actúe sobre una de las salidas GPIO de la placa a la que conectaremos un led para comprobar que el invento funciona. Usaremos la salida GPIO12 (se podría usar cualquier otra) que se corresponde con el pin 3 del puerto de expansión de la Orange Pi Zero Plus (http://linux-sunxi.org/Orange_Pi_Zero_Plus#Expansion_Port).
A continuación necesitaremos cualquier toolchain "arm-none-eabi" que tengamos a mano, puede ser tanto descargada de algún repositorio como compilada por nosotros mismos (ver post en este mismo blog). Se trata de una toolchain diseñada para hacer programas bare metal para arquitecturas ARM de 32 bits. En principio hay dos formas de hacerlo: la elegante y lenta y la "sucia" y rápida. La forma elegante y lenta obliga a escribir un linker script que nos permita pasar casi cualquier programa que queramos a un SPL, sin embargo la forma sucia y rápida, aunque no da tanta libertad, sí que nos permite hacer la prueba de concepto de forma rápida.
#include <stdint.h> void spl() __attribute__ ((section(".spl"))); void spl() { volatile uint64_t n; const uint64_t WAIT = 20000ULL; const uint32_t CCU_BASE = 0x01C20000; *((volatile uint32_t *) (CCU_BASE + 0x0068)) |= 0x00000020; // PIO clock enable const uint32_t PIO_BASE = 0x01C20800; *((volatile uint32_t *) (PIO_BASE + 0x0004)) = 0x77717777; // PA12 como pin de salida while (true) { *((volatile uint32_t *) (PIO_BASE + 0x0010)) = 0x00001000; // PA12 := 1 for (n = 0; n < WAIT; n++) ; *((volatile uint32_t *) (PIO_BASE + 0x0010)) = 0x00000000; // PA12 := 0 for (n = 0; n < WAIT; n++) ; } }
Como se puede apreciar, escribimos el código en una función a la que podemos ponerle el nombre que queramos y, mediante atributos del compilador, le decimos que debe estar en la sección ".spl" (esta etiqueta es arbitraria, la sección podría llamarse ".pepejuan"). Nótese que no estamos usando variables globales y no estamos referenciando nada que esté fuera de la propia función en sí (todo el código está autocontenido). Esta limitación es importante, pues, como se verá más adelante, sólo usaremos como código SPL lo que esté dentro de la sección ".spl" que se ha definido en tiempo de compilación.
A la hora de escribir el código se recurrió al manual de usuario oficial del H5 (https://linux-sunxi.org/File:Allwinner_H5_Manual_v1.0.pdf): en la sección "CCU" (sub sección "Gating and reset") se explica cómo habilitar el reloj para el módulo PIO (el encargado de controlar los pines GPIO), mientras que en la sección "Port Controller (CPUx-PORT)" se explica como habilitar y usar los pines GPIO. Para compilar y generar el fichero binario que transferiremos a la tarjeta MicroSD haremos lo siguiente:
arm-none-eabi-g++ -mtune=cortex-a7 -fno-exceptions -fno-rtti -nostartfiles -c -o spl.o spl.cc
arm-none-eabi-objcopy -O binary -j .spl spl.o spl.bin
mksunxiboot spl.bin spl_with_signature.bin
Primero se genera el fichero "spl.o", a continuación usando la utilidad objcopy extraemos en forma binaria el código que se encuentra en la sección ".spl" desde dentro de "spl.o" hacia "spl.bin" y, como tercer paso, invocamos la utilidad "mksunxiboot" para generar, a partir de "spl.bin", un "spl_with_signature.bin" que sí puede ser transferido tal cual a la tarjeta MicroSD. Como se puede apreciar, se le dice al compilador que genere código compatible Cortex-A7 (para que genere código siguiendo la arquitectura ARMv7-A). Para los que tengan curiosidad por el código que ha generado el compilador, se puede desensamblar dicho código mediante el siguiente comando:
arm-none-eabi-objdump -D spl.o
A continuación cogemos el fichero "spl_with_signature.bin" que acabamos de generar, lo copiamos tal cual a partir del offset 8192 de la tarjeta de memoria y arrancamos la Orange Pi Zero Plus con dicha tarjeta de memoria insertada:
dd if=spl_with_signature.img of=/dev/sdb bs=1024 seek=8
Et voilà :
Todo el código fuente está disponible en la sección soft.
[ añadir comentario ] ( 2731 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |


 ( 3 / 5292 )
( 3 / 5292 )Existen dos tipos básicos de multitarea: la multitarea colaborativa y la multitarea apropiativa. En un post anterior se abordó la implementación de la multitarea cooperativa de forma extensa por lo que ahora le toca el turno a la multitarea apropiativa: en este modelo el sistema "no se fia" de las tareas y de forma periódica arrebata ("se apropia") el control del procesador a la tarea actualmente en ejecución para ceder el control del mismo a otra tarea. Es el mecanismo utilizado por los RTOS en sistemas embebidos y por los sistemas operativos mas grandes (Linux, Windows, OSX, etc.).
Principios
Un sistema con multitarea apropiativa debe por tanto poseer mecanismos que permitan interrumpir la ejecución de la tarea actualmente en curso y que permitan también reanudar la ejecución de otra tarea que haya sido interrumpida previamente. Este mecanismo debería ser lo más transparente al usuario (a las tareas) posible por lo que normalmente se utilizan las interrupciones. Las interrupciones en la totalidad de los procesadores que las implementan (no conozco ningún procesador que no las tenga) permiten ejecutar código de forma no solicitada por la tarea actualmente en ejecución y a raiz de un evento externo al flujo actual de la tarea.
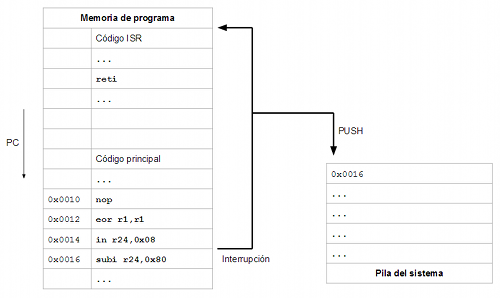
En el momento que se produce la interrupción (la causa puede ser externa al procesador: entradas de datos, pines de entrada que cambian de estado o interna: división entre cero, instrucción no reconocida, etc.) el procesador almacena en la pila del sistema la dirección de la siguiente instrucción que se va a ejecutar y hace que el contador de programa apunte a la primera instrucción del código de interrupción. Este código de interrupción que se ejecuta a raiz del evento suele denominarse ISR (Interrupt Service Routine).
Normalmente existirán diferentes orígenes de interrupción y diferentes vectores de interrupción. Por ejemplo un procesador podría tener dos orígenes de interrupción (el cambio de estado de un pin de entrada y el desbordamiento de un contador interno) y un solo vector de interrupción por lo que se ejecutará la misma ISR para cualquiera de los dos eventos que se produzca. En estos casos, obviamente, el procesador siempre provee mecanismos para que la ISR sea capaz de discernir cuál ha sido la causa de que ella se esté ejecutando (algún registro de estado, por ejemplo).
Lo normal es tener aproximadamente la misma cantidad de orígenes de interrupción que de vectores de interrupción, de tal forma que podemos definir una ISR para cada origen de interrupción. Nótese que una ISR no es más que un trozo de código. En algunos sistemas las ISR no se diferencian en nada de una función normal (por ejemplo, ARM Cortex-M) que debe terminar como todas las funciones con algún tipo de instrucción "ret", mientras que en otros sistemas se debe utilizar algun tipo de instrucción especial normalmente a la hora de regresar: por ejemplo los microcontroladores AVR deben terminar sus funciones ISR con la instrucción "reti" (RETurn from Interrupt). Sin embargo, salvo estas excepciones, dentro de una ISR se puede poner el código que se quiera: no deja de ser un trozo de código como cualquier otro.
Una ISR sencillita
Consideremos inicialmente una ISR sencillita que vamos a compilar para Arduino Leonardo (microcontrolador ATmega32U4):
#include <avr/interrupt.h> #include <avr/io.h> #include <stdint.h> using namespace std; ISR(TIMER0_OVF_vect) { PORTC ^= 0x80; } int main() { PRR1 |= 0x80; DDRC |= 0x80; TCCR0B |= 0x05; TIMSK0 |= 0x01; sei(); while (true) ; return 0; }
$ /ruta/avr/bin/avr-g++ -std=c++11 -DF_CPU=16000000UL -mmcu=atmega32u4 -Os -g -c -o test.o test.cc
$ /ruta/avr/bin/avr-g++ -std=c++11 -DF_CPU=16000000UL -mmcu=atmega32u4 -Os -c -o test.elf test.o
Como se puede ver, usando el compilador avr-g++ se puede hacer de forma muy sencilla un código con soporte para interrupciones en C++. En este caso tenemos un sencillo blinker de toda la vida: cada vez que el Timer 0 se desborda se cambia el estado del bit de salida y hace cambiar de estado a su vez un led conectado a él. Para comprobar de forma detallada cómo funciona el invento podemos desensamblar el fichero ELF generado por el compilador:
$ /ruta/avr/bin/avr-objdump -D test.elf
En la dirección 0 de la memoria tenemos los diferentes vectores de interrupción. Como se puede apreciar está definido el vector 0 (denominado vector de reset ya que en muchos procesadores, como el AVR, el reset se trata como una interrupción más por lo que el vector de reset indica qué código debe ejecutarse nada más encenderse el procesador) y el vector 23 (que se corresponde en el ATmega32U4 con la interrupción de desbordamiento del Timer 0):
Disassembly of section .text:
00000000 <__vectors>:
0: 0c 94 56 00 jmp 0xac ; 0xac <__ctors_end>
4: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
8: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
10: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
14: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
18: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
1c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
20: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
24: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
28: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
2c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
30: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
34: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
38: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
3c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
40: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
44: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
48: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
4c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
50: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
54: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
58: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
5c: 0c 94 62 00 jmp 0xc4 ; 0xc4 <__vector_23>
60: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
64: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
68: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
6c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
70: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
74: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
Si nos vamos al código que ha generado el compilador para la ISR correspondiente al vector 23:
000000c4 <__vector_23>:
c4: 1f 92 push r1
c6: 0f 92 push r0
c8: 0f b6 in r0, 0x3f ; 63
ca: 0f 92 push r0
cc: 11 24 eor r1, r1
ce: 8f 93 push r24
d0: 88 b1 in r24, 0x08 ; 8
d2: 80 58 subi r24, 0x80 ; 128
d4: 88 b9 out 0x08, r24 ; 8
d6: 8f 91 pop r24
d8: 0f 90 pop r0
da: 0f be out 0x3f, r0 ; 63
dc: 0f 90 pop r0
de: 1f 90 pop r1
e0: 18 95 reti
Vemos que lo primero que hace la ISR es guardar en la pila (PUSH) los registros R1, R0, SREG y R24 que son registros que utiliza ("ensucia") para hacer la operación:
PORTC ^= 0x80;
Y, tras realizar dicha operación, restaura de nuevo dichos registros en orden inverso desde la pila (POP) antes de regresar (RETI). Esta forma de operar hace que la tarea principal (el bucle infinito que hay en la función "main") no se da cuenta de que es interrumpido de forma periódica ya que la ISR se encarga de salvaguardar y restaurar los registros que utiliza de forma transparente. La función "main" como mucho puede notar que cada cierto tiempo, entre instrucción e instrucción, pasan más ciclos de lo normal :-).
Conmutación entre tareas
Como se comentó más arriba, cuando se produce una interrupción, los procesadores guardan siempre en la pila la dirección a donde el contador de programa (PC) debe regresar una vez que la interrupción ha terminado de servirse (cuando la ISR termine de ejecutarse). En el caso del ATmega32U4 el procesador empuja en la pila 3 bytes en dos de los cuales almacena la dirección de memoria de la siguiente instrucción que iba a ejecutar (aunque el ATmega32U4 tiene un espacio de direccionamiento de 16 bits, el núcleo AVR que utiliza es el mismo que tienen otros procesadores AVR que tienen un espacio de direcciones de más de 16 bits, de ahí los 3 bytes que se reservan en la pila para la dirección de retorno de la interrupción).
Si lo que queremos es conmutar entre tareas lo que hay que hacer nada más empezar la ejecución de la función ISR es guardar absolutamente todo el estado del procesador y esto se consigue en el caso de AVR apilando los 32 registros generales (desde R0 hasta R31) más el registro de estado SREG en la pila del sistema (PUSH).
ISR(TIMER0_OVF_vect) __attribute__ ((naked)); ISR(TIMER0_OVF_vect) { asm volatile ( "push r0\n" "push r1\n" "push r2\n" "push r3\n" "push r4\n" "push r5\n" "push r6\n" "push r7\n" "push r8\n" "push r9\n" "push r10\n" "push r11\n" "push r12\n" "push r13\n" "push r14\n" "push r15\n" "push r16\n" "push r17\n" "push r18\n" "push r19\n" "push r20\n" "push r21\n" "push r22\n" "push r23\n" "push r24\n" "push r25\n" "push r26\n" "push r27\n" "push r28\n" "push r29\n" "push r30\n" "push r31\n" "in r0, 0x3f\n" "push r0\n"
A continuación, y como el top de la pila es algo cambiante a medida que se va ejecutando código, guardamos en una variable global la dirección de memoria del actual top de la pila: esto nos permitirá acceder cómodamente a los registros que acabamos de guardar independientemente de que empujemos más cosas en ella:
// update stackPointerReference "push r0\n" "in r0, 0x3e\n" "sts stackPointerReference + 1, r0\n" // sph "in r0, 0x3d\n" "sts stackPointerReference, r0\n" // spl "pop r0\n" ); stackPointerReference = (volatile uint8_t *) ((((uint32_t) stackPointerReference) + 1) | 0x800000); // 23-th bit to 1 for SRAM address space
Poner a 1 el bit 23 del puntero stackPointerReference es un artificio necesario en avr-gcc ya que en ese entorno de compilación esa es la forma en la que se diferencian los punteros a memoria de datos de los punteros a memoria de programa (hay que recordar que los AVR tienen arquitectura Harvard).
Tras tener adecuadamente inicializado el puntero "stackPointerReference" podemos proceder a realizar la conmutación de tareas en sí. En nuestro caso se asume una política de tipo Round-robin en la que todas las tareas tienen exactamente el mismo tiempo de proceso. Lo que haremos será, partiendo de una lista de N tareas, cada vez que se ejecute la interrupción de desbordamiento del Timer 0, cambiaremos de la tarea i-ésima a la tarea ((i + 1) MOD N)-ésima, con lo que nos aseguramos que cuando llegamos a la última tarea de la lista volvemos a empezar por la primera y así sucesivamente.
Para cada tarea definimos un objeto de clase Task:
class StackFrame { public: uint8_t sreg; uint8_t r[32]; uint8_t pc[3]; void setPC(void *f) { this->pc[0] = 0; this->pc[1] = ((uint32_t) f) & 0x000000FF; this->pc[2] = ((((uint32_t) f) >> 8) & 0x000000FF); }; } __attribute__ ((packed)); class Task { public: StackFrame stackFrame; bool started; void (*run)(); Task() : started(false) { }; };
Cada tarea tiene una copia del marco de pila ("stack frame") de la última vez que fue interrumpida, un booleano para indicar si la tarea ha sido iniciada o no y un puntero a una función que apunta a la primera instrucción de dicha tarea. En nuestro caso vamos a asumir, sin pérdida de generalidad, que nuestras tareas nunca terminan (no vamos a controlar lo que ocurre cuando la tarea termine).
Definimos además de forma global un array de punteros a objetos de tipo Task, una variable "currentTaskIndex" que indica la actual tarea que está en ejecución y el puntero "stackPointerReference" del que hablamos antes.
const uint16_t MAX_TASKS = 4; volatile uint16_t numTasks; volatile Task tasks[MAX_TASKS]; volatile uint16_t currentTaskIndex; volatile uint8_t *stackPointerReference;
Los primero que hacemos tras calcular el valor de "stackPointerReference" es trabajar con la tarea actual:
Task *currentTask = (Task *) &tasks[currentTaskIndex]; if (currentTask->started) { // copy stack data to currentTask->stackFrame memcpy((void *) ¤tTask->stackFrame, (const void *) (stackPointerReference + 1), sizeof(StackFrame)); } else { // replace return address on currentTask->data with currentTask->run memset((void *) ¤tTask->stackFrame, 0, sizeof(StackFrame)); currentTask->stackFrame.setPC((void *) currentTask->run); }
Si ya está iniciada copiamos los registros que acabamos de apilar (en los PUSH masivos que hicimos al principio de la ISR) al campo "stackFrame" del objeto Task correspondiente a la tarea actual: esto es, ponemos a salvo los registros de la tarea actual pues nos disponemos a hacer una conmutación a la siguiente tarea.
En caso de que la tarea actual no esté iniciada lo que hacemos es borrar el campo "stackFrame" del objeto Task correspondiente a la tarea actual e inicializamos, dentro de esta estructura "stackFrame", los bytes correspondientes al contador de programa para que apunten a la primera instrucción de la tarea actual. Esto hará que cuando se restaure el marco de pila ("stack frame") de esta tarea se inicie dicha tarea (puesto que el contador de programa irá a la primera instrucción de dicha tarea).
A continuación trabajamos con el objeto de tipo Task correspondiente a la tarea siguiente:
uint16_t nextTaskIndex = currentTaskIndex + 1; if (nextTaskIndex == numTasks) nextTaskIndex = 0; Task *nextTask = (Task *) &tasks[nextTaskIndex]; if (nextTask->started) { // replace stack data with nextTask->stackFrame memcpy((void *) (stackPointerReference + 1), (const void *) &nextTask->stackFrame, sizeof(StackFrame)); } else { // replace return address on stack with nextTask->run ((StackFrame *) (stackPointerReference + 1))->setPC((void *) nextTask->run); nextTask->started = true; }
En caso de que la siguiente tarea a iniciar ya esté iniciada ("started") simplemente sobreescribimos todo el marco de pila (los datos que metimos en la pila con los PUSH masivos del principio de la ISR) con los bytes de campo "stackFrame" de la siguiente tarea, lo que provocará una conmutación a la tarea siguiente en el momento que retornemos de la interrupción. En caso de que la siguiente tarea no esté iniciada aún hacemos lo mismo que en caso de la tarea actual: inicializamos, dentro de la estructura "stackFrame" los bytes correspondientes al contador de programa para que apunten a la primera instrucción de la tarea siguiente y, a continuación, marcamos la tarea como iniciada ("started = true").
Antes de terminar actualizamos la variable global "currentTaskIndex" para que apunte a la tarea a la que se le va a entregar el control de la CPU y hacemos una restauración normal de la pila (POP masivos) antes de terminar definitivamente con la instrucción "RETI".
currentTaskIndex = nextTaskIndex; asm volatile ( "pop r0\n" "out 0x3f, r0\n" "pop r31\n" "pop r30\n" "pop r29\n" "pop r28\n" "pop r27\n" "pop r26\n" "pop r25\n" "pop r24\n" "pop r23\n" "pop r22\n" "pop r21\n" "pop r20\n" "pop r19\n" "pop r18\n" "pop r17\n" "pop r16\n" "pop r15\n" "pop r14\n" "pop r13\n" "pop r12\n" "pop r11\n" "pop r10\n" "pop r9\n" "pop r8\n" "pop r7\n" "pop r6\n" "pop r5\n" "pop r4\n" "pop r3\n" "pop r2\n" "pop r1\n" "pop r0\n" "reti\n" ); }
Para la prueba de concepto se implementaros dos tareas muy sencillas: cada una hace parpadear un led a una velocidad diferente:
void task1() __attribute__ ((naked)); void task1() { DDRD |= 0x04; // PD2 (D0 on Arduino Leonardo) as output while (true) { PORTD ^= 0x04; for (volatile uint32_t i = 0; i < 66000; i++) ; } } void task2() __attribute__ ((naked)); void task2() { DDRC |= 0x80; // PC7 (D13 on Arduino Leonardo) as output while (true) { PORTC ^= 0x80; for (volatile uint32_t i = 0; i < 200000; i++) ; } }
Consideraciones adicionales
Nótese que tanto la ISR como las funciones "tarea" ("task1" y "task2") son declaradas con el atributo "naked". Este atributo indica al compilador que no genere código preámbulo ni postámbulo (el código ensamblador relacionado normalmente con el manejo de parámetros y valores de retorno).
En el caso de las funciones "task1" y "task2" se ha usado este atributo por una cuestión de coherencia ya que no se trata de funciones que son invocadas de forma normal desde otra parte del programa y además se trata de funciones que no terminan nunca de ejecutarse.
El caso de la función ISR es más delicado porque en ese caso sí que es necesario usar el atributo "naked". Como se vió en la primera prueba con la interrupción del Timer 0, para el siguiente código:
ISR(TIMER0_OVF_vect) {
PORTC ^= 0x80;
}
El compilador generaba instrucciones PUSH y POP de los registros que utilizaría, antes y después de la operación "PORTC ^= 0x80" respectivamente. En nuestro caso necesitamos que el apilado (PUSH) y desapilado (POP) de registros sea siempre igual y masivo y que esté perfectamente controlado por nosotros por lo que definimos la función con el atributo "naked" y nos encargamos nosotros de escribir de forma explícita el código ensamblador de preámbulo y postámbulo de la ISR.
Todo el código puede descargarse de la sección soft.
[ añadir comentario ] ( 8073 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 7033 )Como todos los años cuando se acercan las fechas navideñas siempre trato de revisitar el concepto de luces del Belén aprovechando los conocimientos adquiridos en el último año. En este caso, entendiendo que el concepto de luces a secas ya hay que superarlo :-), se ha introducido una componente móvil en el Belén de este año: un cielo artificial con ciclo día-noche.
La rueda del cielo
Para simular un cielo que cambia entre día y noche se ha optado por una solución muy sencilla basada en un disco de cartón de medio metro de diámetro, aproximadamente, a cuyo eje se conecta directamente un motor paso a paso con una reductora. El motor girará lentamente a razón de una vuelta cada día.
Colocando el motor encima del mueble sobre el que se va a colocar el belén, con el eje apuntando a la pared, se puede colocar el disco de cartón de tal manera que sólo sea visible la mitad superior del mismo. De esta manera se puede pintar medio disco de cartón como si fuese de día (azul celeste, por ejemplo) y la otra mitad del disco de negro con el firmamento y la estrella de Belén, por ejemplo.

Electrónica de control de la rueda del cielo
El motor elegido para acoplar la rueda del cielo es el conocido y asequible 28BYJ-48 (que venden en AliExpress junto con la placa controladora a unos 2 ¤ en el momento de escribir estas líneas). Se trata de un motor paso a paso de 4 bobinas (4 pasos enteros u 8 medios pasos) y con una reductora interna que nos da una resolución teórica de 4096 medios pasos por vuelta (por cuestiones mecánicas, en realidad son medios 4076 pasos por vuelta, según comenta Luis Llamas en su blog).
La placa controladora tiene cuatro entradas digitales correspondientes cada una a una de las 4 bobinas del motor. Activando alternativamente las entradas 1, 2, 3, 4, 1, 2, 3, 4... hacemos girar el motor en un sentido, mientras que activando alternativamente las entradas 4, 3, 2, 1, 4, 3, 2, 1... hacemos girar el motor en el sentido opuesto. A aquellas personas que no estén familiarizadas con los motores paso a paso o con este motor paso a paso en particular les recomiendo esta entrada del blog de Luis Llamas, donde está magníficamente explicado.
La idea es hacer un circuito que haga que el motor paso a paso se mueva lentamente de manera que de una vuelta entera cada 24 horas (para simular el ciclo día-noche en el disco de cartón). Al diseño hay que añadirle botones de avance y retroceso rápido para que el disco pueda "calibrarse" o "sincronizarse" manualmente de forma sencilla (hay que recordar que no es necesaria una precisión milimétrica, es para un Belén). A continuación un diagrama del circuito a implementar en el CPLD:
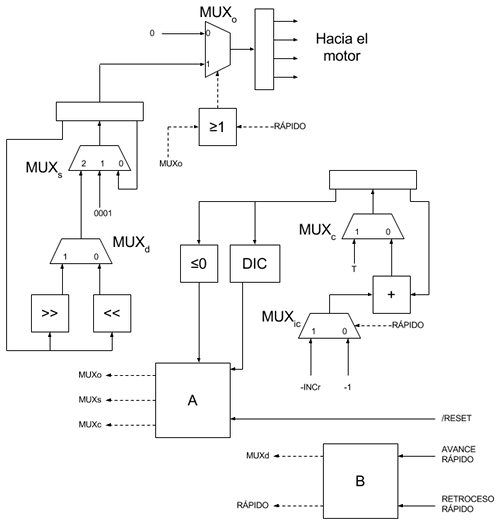
El circuito consta de tres registros:
- Uno que actúa como latch de salida.
- Otro que actúa de registro de rotación.
- Otro que actúa como contador.
El multiplexor que controla el valor del latch de salida (MUXo) permite elegir entre la salida del registro de rotación o todo ceros, el multiplexor que controla el valor del registro de rotación (MUXs)permite elegir entre mantener el valor (realimentación directa), cargar un valor "0001" (para cuando se inicializa el circuito) o cargar una versión rotada de la salida actual del registro de rotación (en un sentido u otro dependiento de otro multiplexor, MUXd). El multiplexor que controla el registro contador (MUXc) permite elegir entre cargar el valor de reset del contador (T) o cargar el valor decrementado. La constante con la que se decrementa el registro contador debe variar en función de la velocidad a la que queramos que se mueva el disco y está controlada por otro multiplexor (MUXic).
El resto de bloques que aparecen en el esquema son circuitos combinacionales:
- El bloque "<=0" genera un 1 si el valor del contador (con signo) es menor o igual a cero.
- El bloque "DIC" (Dentro Intervalo Cuenta) genera un 1 a su salida si el valor del registro contador está dentro de un intervalo de valores. Esto se utiliza para evitar que las bobinas del motor paso a paso consuman mucho ya que para girar el rotor un paso basta con generar un pulso lo suficientemente ancho en la bobina correspondiente y luego dejar el motor en reposo (la reductora hace que el motor rotor esté prácticamente frenado en ausencia de pulsos).
- El bloque ">=1" es una puerta OR. Cuando se está haciendo avance o retroceso rápido, el multiplexor de salida hace de buffer del registro de rotación, pero cuando no estamos girando rápido, hay que activar las bobinas el motor sólo el tiempo necesario para evitar que el circuito consuma mucha corriente. De esta forma aunque el registro de rotación tenga el valor "0100" el registro de salida sólo tendrá el valor "0100" el tiempo necesario para excitar la bobina correspondiente y, a continuación, emitirá un "0000" aunque en el registro de rotación siga estando el valor "0100".
- El bloque "+" es un bloque sumador estándar. El encargado de ir decrementando el registro contador.
Funcionamiento
Los otros dos bloques combinacionales (abajo a izquierda y derecha) son los encargados de controlar todo el conjunto. Veamos primero el bloque combinacional de abajo a la izquierda:
| Entradas | Salidas | ||||
|---|---|---|---|---|---|
| DIC | /RESET | <=0 | MUXs | MUXc | MUXo |
| X | 0 | X | 1 | 1 | 0 |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 |
| X | 1 | 1 | 2 | 1 | 0 |
Cuando la entrada /RESET se pone a 0, MUXs selecciona la entrada "0001", MUXc selecciona la entrada del valor de reset del contador (T) y MUXo selecciona la entrada "0000", por lo que en el siguiente ciclo de reloj el registro de salida se pondrá a cero, el registro contador se cargará con el valor T y el registro de rotación se cargará con el valor "0001".
Una vez que /RESET se pone a 1, como el registro contador vale T (se trata de un contador decremental), tanto las entradas C como DIC están a cero por lo que MUXs selecciona la entrada de realimentación (para mantener el valor actual del registro de rotación), MUXc selecciona la entrada procedente del sumador y MUXo sigue seleccionando la entrada con el valor "0000" (la salida del latch que va al motor sigue siendo "0000") por ahora.
Hay que tener en cuenta que, como el MUXc está selecionando la entrada procedente del sumador, cada ciclo de reloj que pasa, el valor del contador se decrementa. En algún momento el valor del contador entrará dentro del intervalo configurado para el bloque combinacional DIC y este bloque empezará a emitir un 1. Esto provoca que el MUXo seleccione la entrada procedente del registro de rotación por lo que se emitirá el valor almacenado en dicho registro hacia el motor durante el tiempo que el valor del contador genere un 1 a la salida del bloque DIC. Cuando el contador baje por debajo del umbral inferior del bloque comparador DIC, la salida de este bloque será de nuevo 0 y la salida del registro de salida volverá a ser "0000" de nuevo. El tiempo que el bloque comparador DIC emite un 1 debe ser suficiente como para que se exciten adecuadamente las bobina del motor (en mi caso lo he puesto para que las active durante un segundo, más que suficiente).
Una vez que el registro de salida ha vuelto a "0000" el registro contador continúa su camino hacia el cero. Cuando llega a cero (o lo sobrepasa hacia el negativo), el bloque "<=0" emite un 1. Esta condición hace que el MUXs seleccione la entrada de rotación (para que se active la siguiente bobina del motor y el rotor gire un poquito), que el MUXc seleccione la entrada del valor iniciar T (para que se cargue el contador con el valor inicial) y que el MUXo seleccione la entrada "0000" (para seguir emitiendo ceros).
Esto provoca que todo el ciclo empiece de nuevo por lo que tendremos que, calculando bien el valor de T y los valores umbral del bloque comparador DIC conseguiremos un disco dia-noche que de una vuelta entera una vez cada 24 horas.
Si el motor paso a paso da una vuelta completa cada 4076 medios pasos y nosotros vamos a utilizarlo con pasos enteros, cará una vuelta cada ${4076 \over 2} = 2038$ pasos enteros. Por tanto si queremos que de una vuelta entera cada día tendrán que pasar:
$${{24 \times 60 \times 60} \over 2038} = 42.3945 \ \ segundos/paso$$
Como el reloj va a 50 MHz el valor de T será de:
$${{24 \times 60 \times 60} \over 2038} \times 50000000 \approx 2119725221 \ \ ciclos/paso$$
Con este valor de T podemos hacer que el bloque DIC emita un 1 cuando:
$$2119725000 > contador > 2069725220$$
50000000 de ciclos de diferencia (1 segundo). Y un 0 en el resto de los casos.
El bloque combinacional de abajo a la derecha es el encargado de controlar el avance y retroceso rápidos.
| Entradas | Salidas | ||
|---|---|---|---|
| Avance rápido | Retroceso rápido | MUXd | Rápido |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | X | 0 | 1 |
En función de los valores de las entradas de avance rápido y retroceso rápido, el multiplexor MUXd seleccionará un sentido de rotación u otro. Además, en caso de que se pulse cualquiera de los dos botones, el registro latch de salida selecciona siempre la entrada proveniente del registro de rotación: cuando estamos haciendo avance y retroceso rápido los pulsos de activación serán tan cortos que no será necesario usar el mecanismo del bloque DIC para controlar la anchura de los pulsos de activación de las bobinas.

Luces para el cielo nocturno
Para rizar el rizo y aprovechando que tenía por aquí un CPLD chico de 64 macroceldas (el EPM3064A de Altera, unos 6 ¤ por aliexpress) me aventuré a colocar unas luces en la parte "nocturna" del disco giratorio. Una pila de botón de tipo CR2032 es más que suficiente para alimentar el CPLD y los 5 leds que se usan para simular las estrellas.

En este caso se ha realizado una implementación simplificada del diseño publicado en este post. En lugar de incluir un comparador y un latch se ha optado por emitir directamente hacia los leds, cinco de los bits del registro LFSR de 10 bits.
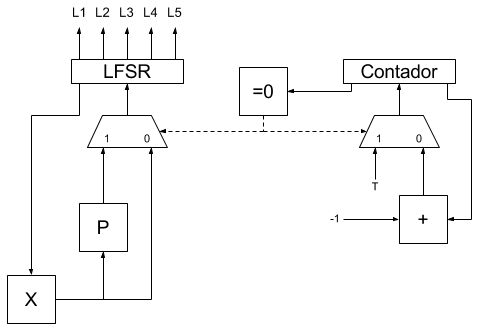
Si el reloj del CPLD va a 50 MHz (como en nuestro caso) y queremos que las luces cambien cada segundo, T debe valer 50000000. La descripción del resto de bloques combinacionales es la siguiente:
- El bloque "P" es el bloque que aplica el polinomio de realimentación maximal para 10 bits al valor actual del registro LFSR (una puerta XOR más un desplazamiento). Al ser un polinomio maximal de 10 bits el registro LFSR generará una secuencia de números pseudoaleatoria comprendida entre los valores 1 y 1023 (el valor 0 está fuera de la secuencia y en caso de que se alcance dicho valor, el LFSR se "para").
- El bloque "X" es un bloque que, en caso de que la entrada valga "0000000000" en la salida emite "0000000001", en caso contrario emite la entrada sin cambiar. Este bloque se coloca para garantizar que si el LFSR se pone totalmente a 0 (por ruido, reinicio, encendido, etc.) vaya a un valor que sí esté dentro de la secuencia pseudoaleatoria de números y pueda así seguir generando números dentro de dicha secuencia.
- El bloque "=0" es un bloque que emite un 1 si el valor del registro contador es 0 y un 0 en caso contrario.
Como se puede observar el comportamiento del generador de destellos para el firmamento nocturno es muy sencillo:
Si asumimos que el momento del arranque los registros están todos a cero, la salida del bloque "=0" será 1 por lo que se seleccionará la entrada T del multiplexor del contador y la entrada P del multiplexor del LFSR. Aunque el registro LFSR está a 0, la salida del bloque X será "0000000001" por lo que la salida de P será el siguiente valor de la secuencia maximal de P después del valor "0000000001". En el momento que llega el siguiente flanco de subida del reloj se carga el registro LFSR con el nuevo valor de la secuencia pseudoaleatoria y se carga el registro contador con el valor T (50000000).
A partir de ahora, como el registro contador contiene un valor diferente de 0, la salida del bloque "=0" será un 0 por lo que el multiplexor del registro LFSR mantendrá el valor actual del registro LFSR y el multiplexor del contador seleccionará la entrada que proviene del sumador. Esta condición se mantendrá durante el tiempo que el contador sea mayor que cero (para T = 50000000 a 50 MHz, tenemos un segundo de tiempo) y en el momento que el contador llegue a cero, el bloque combinacional "=0" emitirá de nuevo un uno y el proceso se reanudará de nuevo (carga del LFSR con el siguiente valor de la secuencia pseudoaleatoria y carga del contador con el valor T).
Si sacamos hacia fuera 5 de los 10 bits del registro LFSR (no tienen por qué ser consecutivos) obtendremos un razonable efecto de "cielo estrellado aleatorio" que cambia cada segundo. Ahora podemos colocar todo el montaje en la parte trasera del disco de cartón dejando que se asomen hacia adelante sólo los leds y poniendo en la cara no visible la plaquita con el CLPD y la pila de botón.
Todo el código VHDL está disponible en la sección soft.
A continuación puede verse una foto de todo el conjunto pintado y montado simulando el cielo nocturno:

Y simulando el clieno diurno ("amaneciendo"):

¡Feliz Navidad a todos! :-)
[ añadir comentario ] ( 5646 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 6484 )Hace tiempo publiqué las instrucciones para compilar la toolchain de GNU para ARM "bare metal" (sin sistema operativo, arm-none-eabi) basada en GCC 5.1 y newlib. Dichas instrucciones no son aplicables para las versiones actuales de GCC (7.2 a día de hoy) por lo que a continuación indico las instrucciones actualizadas a las nuevas versiones de binutils, gcc y newlib.
Se trata de una toolchain para sistemas "bare metal", sin sistema operativo, por lo que no tiene soporte para multihilos ni para librerías dinámicas.
binutils 2.29
mkdir -p /opt/baremetalarm/src
mkdir -p /opt/baremetalarm/build
cd /opt/baremetalarm/src
wget https://ftp.gnu.org/gnu/binutils/binutils-2.29.tar.bz2
tar xf binutils-2.29.tar.bz2
chown -R root:root binutils-2.29
cd ../build
mkdir binutils-2.29
cd binutils-2.29/
../../src/binutils-2.29/configure --prefix=/opt/baremetalarm --target=arm-none-eabi --disable-nls --disable-multilib
make
make install
gcc 7.2.0 (stage 1)
cd /opt/baremetalarm/src
wget https://ftp.gnu.org/gnu/gcc/gcc-7.2.0/gcc-7.2.0.tar.gz
wget https://ftp.gnu.org/gnu/gmp/gmp-6.1.2.tar.bz2
wget https://ftp.gnu.org/gnu/mpc/mpc-1.0.3.tar.gz
wget https://ftp.gnu.org/gnu/mpfr/mpfr-3.1.6.tar.gz
tar xf gcc-7.2.0.tar.gz
tar xf gmp-6.1.2.tar.bz2
tar xf mpc-1.0.3.tar.gz
tar xf mpfr-3.1.6.tar.gz
mv gmp-6.1.2 gcc-7.2.0/gmp
mv mpc-1.0.3 gcc-7.2.0/mpc
mv mpfr-3.1.6 gcc-7.2.0/mpfr
chown -R root:root gcc-7.2.0
cd ../build/
mkdir gcc-7.2.0-stage-1
cd gcc-7.2.0-stage-1/
export PATH=/opt/baremetalarm/bin:${PATH}
../../src/gcc-7.2.0/configure --prefix=/opt/baremetalarm --target=arm-none-eabi --enable-languages=c --without-headers --disable-nls --disable-multilib --disable-threads --disable-shared --disable-libssp --with-newlib
make all-gcc all-target-libgcc
make install-gcc install-target-libgcc
newlib
cd /opt/baremetalarm/src
git clone git://sourceware.org/git/newlib-cygwin.git
cd ../build
mkdir newlib
cd newlib
../../src/newlib-cygwin/configure --prefix=/opt/baremetalarm --target=arm-none-eabi --disable-multilib
make
make install
gcc 7.2.0 (stage 2)
cd /opt/baremetalarm/build
mkdir gcc-7.2.0-stage-2
cd gcc-7.2.0-stage-2/
../../src/gcc-7.2.0/configure --prefix=/opt/baremetalarm --target=arm-none-eabi --enable-languages="c,c++" --disable-nls --disable-multilib --disable-threads --disable-shared --disable-libssp --with-newlib
make
make install
El compilador de C++ de GCC 7.2 compila por defecto en modo C++14 y soporta prácticamente todo el estándar C++17.
[ añadir comentario ] ( 3352 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 6331 )A lo largo de este post se abordará el diseño y la implementación en VHDL de una interfaz de salida VGA para FPGA. La interfaz lee una imagen de 64x48 pixels de una memoria (por ahora una ROM) interna y la renderiza usando el modo VGA estándar de 640x480 a 60Hz.
Señal VGA
Las señales más importantes que viajan por un cable VGA son:
- R (nivel de rojo, mínimo 0 voltios, máximo 0.7 voltios)
- G (nivel de verde, mínimo 0 voltios, máximo 0.7 voltios)
- B (nivel de azul, mínimo 0 voltios, máximo 0.7 voltios)
- Sincronismo horizontal (HSync, señal digital TTL que puede ser de 3.3 voltios)
- Sincronismo vertical (VSync, señal digital TTL que puede ser de 3.3 voltios)
Un flanco de bajada en HSync determina el fin de una línea horizontal de imagen y un flanco de bajada en VSync determina el fin de un fotograma, o de un cuadro). Hay unos "márgenes de seguridad" antes y después (front y back porch) de cada flanco de bajada de HSync de la misma forma que hay unos "márgenes de seguridad" (en forma de líneas en negro) antes y después (front y back porch) de cada flanco de bajada de VSync.
A continuación puede verse un diagrama de tiempos sobre cómo funcionan las señales de color y de sincronismo en un cable VGA:
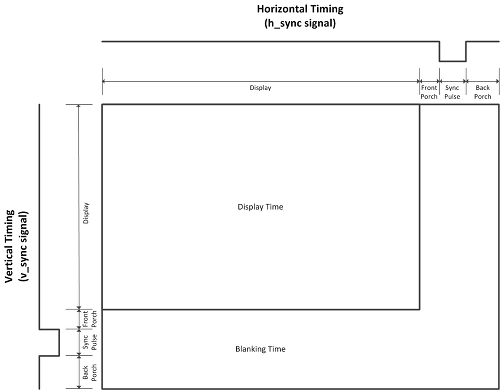
(imagen copyright © 2017 Scott Larson, extraida de este artículo)
Si asumimos una resolución VGA estándar de 640 x 480 pixels a 60 Hz, tendremos los siguientes valores:
| Pixel clock | Anchura (pixels) | Altura (líneas) | ||||||
| Visibles | No visibles | Visibles | No visibles | |||||
| Front porch | HSync | Back porch | Front porch | HSync | Back porch | |||
| 25.175 MHz | 640 | 16 | 96 | 48 | 480 | 10 | 2 | 33 |
Con estos valores vemos que, en efecto tenemos una tasa de refresco de:
$${1 \over {{{640+16+96+48} \over {25175000}} \times {\left(480+10+2+33\right)}}}=59.940\ Hz \approx 60\ Hz$$
Como los valores RGB son analógicos (entre 0 y 0.7 voltios), será necesario implementar un DAC (aunque sea de forma rudimentaria) por cada componente de color. Asumiremos una imagen de 8 colores con un bit por cada componente:
| 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| negro | azul | verde | cyan | rojo | rosa | amarillo | blanco |
De esta forma tendremos un DAC de 1 bit por cada color. Si la impedancia de entrada de las entradas RGB es de 75 Ohm vemos que con una sencilla resistencia de 270 Ohm en serie construimos un divisor de tensión que genera 0 voltios con un valor lógico 0 (0 voltios de salida digital) y 0.7 voltios con un valor lógico 1 (3.3 voltios de salida digital):
$${0 \times {75 \over {270+75}}}=0\ voltios$$
$${3.3 \times {75 \over {270+75}}}=0.71739\ voltios$$
Por cada píxel hay que almacenar 3 bits pero como las anchuras de bus de 3 bits son raras asumimos que cada pixel ocupa un byte del cual (por ahora) sólo se usan los 3 bits menos significativos.
Como el reloj de nuestra FPGA va a 50 MHz y el pixel clock es de 25.175 MHz se ha optado por asumir una imagen de 64 x 48 pixels. Esto es: cada pixel de la imagen en la memoria se corresponde con un cuadrado de 10 x 10 pixels en la pantalla. Usando esta aproximación, una imagen de 64 x 48 pixels necesita 64 x 48 = 3072 bytes de almacenamiento y el pixel clock se reduce de 25.175 MHz a 2.5175 MHz, que es una frecuencia más fácil de manejar por la FPGA.
Tenemos, por tanto, una memoria de 64 x 48 = 3072 bytes en la que cada byte posee los valores RGB en sus tres bits menos significativos. En cada línea de imagen se deben pintar 64 pixels (con un pixel clock de 2.5175 MHz en lugar de 25.175 MHz para que cada pixel de la memoria ocupe 10 pixels VGA de ancho) y cada línea debe ser pintada 10 veces de idéntica manera.
Ruta de datos y máquina de estados
A continuación puede verse una propuesta de ruta de datos a implementar para la interfaz VGA:
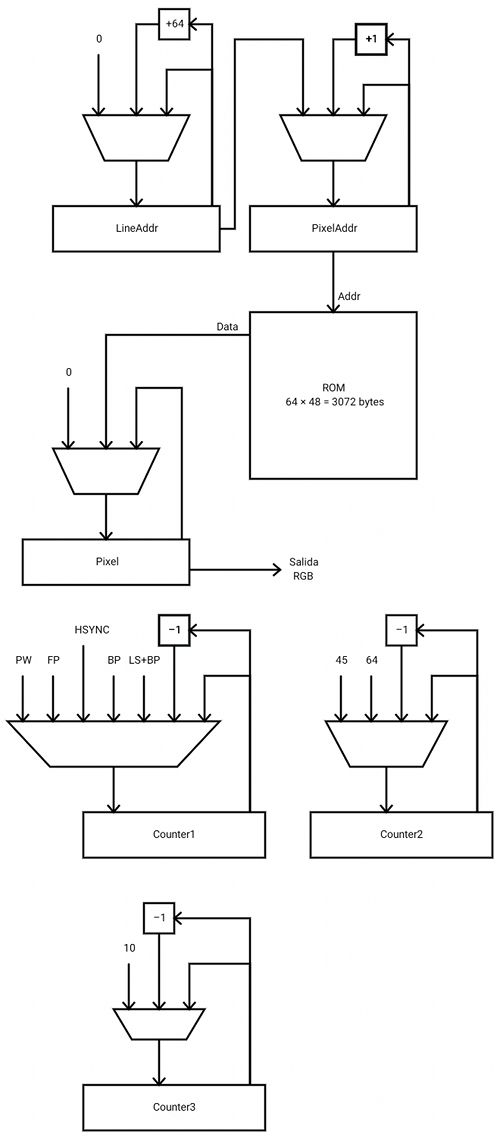
Leyenda:
PW = Pixel width
FP = Front porch (tiempo "en negro" antes del pulso HSync)
BP = Back porch (tiempo "en negro" después del puslto HSync)
LS = Line size, anchura total en pulsos de una línea en blanco de 640 pixels
El registro LineAddr almacena la dirección de comienzo de la línea actual. Es un registro que se incrementa de 64 en 64 y que ayuda a hacer el repetido de líneas (cada una de las 48 líneas de la imagen debe ser repetida 10 veces para renderizar las 480 líneas VGA).
El registro PixelAddr almacena la dirección de memoria del píxel actual que está siendo pintado. Este registro se inicializa siempre con el valor del registro LineAddr y es incrementado de uno en uno, 64 veces por cada línea (64 * 10 pixels = 640 pixels de anchura de la señal VGA).
El registro Pixel almacena el byte de cuyos tres bits más bajos se sacan las señales RGB de forma directa. Está gobernado por un multiplexor que decide si carga datos de la memoria o de la constante 0. Nótese que durante los márgenes de seguridad (front y back porch), durante los intervalos de sincronismo (tanto vertical como horizontal) y durante las lineas de retrazo (las que no se ven, de la 480 a la 524, 45 en total) debe emitirse una señal en negro por los pines RGB.
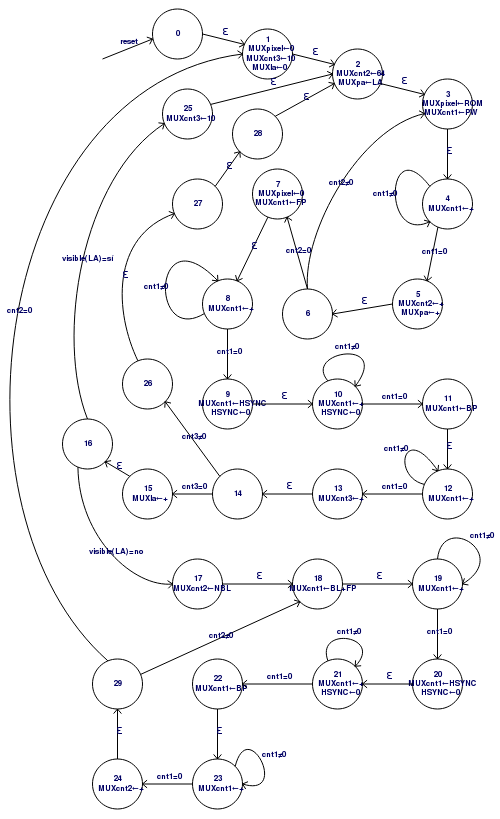
Se han habilitado además 3 contadores de propósito general que son utilizados por la máquina de estados para controlar los tiempos de cada fase de la señal VGA. La máquina de estados puede verse a continuación:
Los diferentes valores que se aplican a los contadores para controlar los tiempos del protocolo VGA se calculan teniendo en cuenta la frecuencia de reloj usada (50 MHz) y la frecuencia de pixel VGA (25.175 MHz). Por ejemplo el valor de PW (PIXEL_WIDTH) se usa para esperar un tiempo equivalente a 10 pixels:
$$PW={{1 \over 25175000} \times 50000000 \times 10}=20\ pulsos$$
De la misma forma se calcula el resto de valores:
$$FP={{1 \over 25175000} \times 50000000 \times 16}=32\ pulsos$$
$$HSYNC={{1 \over 25175000} \times 50000000 \times 96}=191\ pulsos$$
$$BP={{1 \over 25175000} \times 50000000 \times 48}=95\ pulsos$$
$$LS+BP={{1 \over 25175000} \times 50000000 \times \left(640+16\right)}=1303\ pulsos$$
Estos valores teóricos son luego ajustados ya que en esas ecuaciones sólo se tienen en cuenta los estados de espera y no se contabiliza el resto de estados, que también consumen ciclos de reloj.
Una técnica muy usada para compensar los tiempos de espera en las máquinas de estado es incluir estados que no hacen nada con transiciones vacías (épsilon). Como se puede ver en la imagen anterior, el estado 14 se alcanza siempre al final del renderizado de una línea horizontal VGA. Si Contador3 = 0 entonces se ha terminado una repetición de 10 líneas consecutivas y toca avanzar de línea, pero si Contador3 <> 0 entonces hay que volver a pintar la línea actual (la que está apuntada por el registro LA, LineAddress). En este último caso, la máquina de estados pasa por tres estados que no hacen nada (26, 27 y 28) pero que se han colocado ahí para que no haya diferencia entre la cantidad de ciclos que tarda una línea repetida y la cantidad de ciclos que tarda una línea nueva.
Buffers de salida para los sincronismos
Aunque la máquina de estados ya genera directamente las señales HSync y VSync, es necesario hacerlas pasar por un latch (biestable D) para garantizar que quedan libres de gitches.
-- acondicionador de señales HSync y VSync process (Clk) begin if (Clk'event and (Clk = '1')) then HSyncQBus <= HSyncDBus; end if; end process; HSyncDBus <= HSyncIn; HSyncOut <= HSyncQBus; process (Clk) begin if (Clk'event and (Clk = '1')) then VSyncQBus <= VSyncDBus; end if; end process; VSyncDBus <= VSyncIn; VSyncOut <= VSyncQBus;
Si no se colocasen estos latches y se cableasen directamente las salidas HSync y VSync a los pines de la PFGA podría ocurrir que transiciones intermedias espúreas entre estados generasen pulsos "fantasma" en dichas salidas. Haciendo pasar a estas señales por un latch se garantiza una carga atrasada y limpia que disminuye la probabilidad de que se produzcan estos glitches.
Por claridad, estos latches no se muestran en el diagrama con la ruta de datos mostrado anteriormente.
Código fuente e implementación
La máquina de estados se ha implementado, como otras veces, siguiendo el modelo estándar de máquina de Moore:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity FSM is port ( Clk : in std_logic; Reset : in std_logic; Counter1IsZero : in std_logic; Counter2IsZero : in std_logic; Counter3IsZero : in std_logic; LineAddrIsVisible : in std_logic; Counter2IsVSync : in std_logic; Counter1Mux : out std_logic_vector(2 downto 0); Counter2Mux : out std_logic_vector(1 downto 0); Counter3Mux : out std_logic_vector(1 downto 0); LineAddrMux : out std_logic_vector(1 downto 0); PixelAddrMux : out std_logic_vector(1 downto 0); PixelMux : out std_logic_vector(1 downto 0); HSync : out std_logic; VSync : out std_logic ); end entity; architecture A of FSM is signal DBus : std_logic_vector(4 downto 0); signal QBus : std_logic_vector(4 downto 0); begin -- lógica de estado siguiente DBus <= "00000" when (Reset = '1') else "00001" when ((QBus = "00000") or ((QBus = "11101") and (Counter2IsZero = '1'))) else "00010" when ((QBus = "00001") or (QBus = "11100") or (QBus = "11001")) else "00011" when ((QBus = "00010") or ((QBus = "00110") and (Counter2IsZero = '0'))) else "00100" when ((QBus = "00011") or ((QBus = "00100") and (Counter1IsZero = '0'))) else "00101" when ((QBus = "00100") and (Counter1IsZero = '1')) else "00110" when (QBus = "00101") else "00111" when ((QBus = "00110") and (Counter2IsZero = '1')) else "01000" when ((QBus = "00111") or ((QBus = "01000") and (Counter1IsZero = '0'))) else "01001" when ((QBus = "01000") and (Counter1IsZero = '1')) else "01010" when ((QBus = "01001") or ((QBus = "01010") and (Counter1IsZero = '0'))) else "01011" when ((QBus = "01010") and (Counter1IsZero = '1')) else "01100" when ((QBus = "01011") or ((QBus = "01100") and (Counter1IsZero = '0'))) else "01101" when ((QBus = "01100") and (Counter1IsZero = '1')) else "01110" when (QBus = "01101") else "01111" when ((QBus = "01110") and (Counter3IsZero = '1')) else "10000" when (QBus = "01111") else "10001" when ((QBus = "10000") and (LineAddrIsVisible = '0')) else "10010" when ((QBus = "10001") or ((QBus = "11101") and (Counter2IsZero = '0'))) else "10011" when ((QBus = "10010") or ((QBus = "10011") and (Counter1IsZero = '0'))) else "10100" when ((QBus = "10011") and (Counter1IsZero = '1')) else "10101" when ((QBus = "10100") or ((QBus = "10101") and (Counter1IsZero = '0'))) else "10110" when ((QBus = "10101") and (Counter1IsZero = '1')) else "10111" when ((QBus = "10110") or ((QBus = "10111") and (Counter1IsZero = '0'))) else "11000" when ((QBus = "10111") and (Counter1IsZero = '1')) else "11001" when ((QBus = "10000") and (LineAddrIsVisible = '1')) else "11010" when ((QBus = "01110") and (Counter3IsZero = '0')) else "11011" when (QBus = "11010") else "11100" when (QBus = "11011") else "11101" when (QBus = "11000") else "00000"; -- lógica de salida Counter1Mux <= "001" when (QBus = "00011") else -- cargar anchura de pixel "010" when (QBus = "00111") else -- cargar front porch "011" when ((QBus = "01001") or (QBus = "10100")) else -- cargar HSYNC "100" when ((QBus = "01011") or (QBus = "10110")) else -- cargar back porch "101" when (QBus = "10010") else -- cargar anchura línea + front porch "110" when ((QBus = "00100") or (QBus = "01000") or (QBus = "01010") or (QBus = "01100") or (QBus = "10011") or (QBus = "10101") or (QBus = "10111")) else -- decrementar "000"; Counter2Mux <= "01" when (QBus = "00010") else -- cargar 64 (la anchura de línea) "10" when ((QBus = "00101") or (QBus = "11000")) else -- decrementar "11" when (QBus = "10001") else -- cargar 45 (cantidad de líneas de blanqueo) "00"; Counter3Mux <= "01" when ((QBus = "00001") or (QBus = "11001")) else -- cargar 10 (líneas a repetir) "10" when (QBus = "01101") else -- decrementar "00"; LineAddrMux <= "01" when (QBus = "00001") else -- cargar 0 "10" when (QBus = "01111") else -- incrementar en 64 "00"; PixelAddrMux <= "01" when (QBus = "00010") else "10" when (QBus = "00101") else "00"; PixelMux <= "01" when ((QBus = "00001") or (QBus = "00111")) else -- cargar 0 "10" when (QBus = "00011") else -- cargar dato de la ROM "00"; HSync <= '0' when ((QBus = "01001") or (QBus = "01010") or (QBus = "10100") or (QBus = "10101")) else '1'; VSync <= '0' when (((QBus = "10010") or (QBus = "10011") or (QBus = "10100") or (QBus = "10101") or (QBus = "10110") or (QBus = "10111") or (QBus = "11000") or (QBus = "11101")) and (Counter2IsVSync = '1')) else '1'; -- biestables process (Clk) begin if (Clk'event and (Clk = '1')) then QBus <= DBus; end if; end process; end architecture;
El resto de la implementación consiste en codificar lo registros y los multiplexores:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity AllButFSM is port ( Clk : in std_logic; LineAddrMux : in std_logic_vector(1 downto 0); PixelAddrMux : in std_logic_vector(1 downto 0); PixelMux : in std_logic_vector(1 downto 0); PixelValue : out std_logic_vector(7 downto 0); HSyncIn : in std_logic; HSyncOut : out std_logic; VSyncIn : in std_logic; VSyncOut : out std_logic; Counter1Mux : in std_logic_vector(2 downto 0); Counter1IsZero : out std_logic; Counter2Mux : in std_logic_vector(1 downto 0); Counter2IsZero : out std_logic; Counter2IsVSync : out std_logic; Counter3Mux : in std_logic_vector(1 downto 0); Counter3IsZero : out std_logic; LineAddrIsVisible : out std_logic ); end entity; architecture A of AllButFSM is component Rom is generic ( Log2NumRows : integer := 12 -- 4096 bytes ); port ( AddressIn : in std_logic_vector((Log2NumRows - 1) downto 0); DataOut : out std_logic_vector(7 downto 0) ); end component; component Counter1 is port ( Clk : in std_logic; Mux : in std_logic_vector(2 downto 0); IsZero : out std_logic ); end component; component Counter2 is port ( Clk : in std_logic; Mux : in std_logic_vector(1 downto 0); IsZero : out std_logic; IsVSync : out std_logic ); end component; component Counter3 is port ( Clk : in std_logic; Mux : in std_logic_vector(1 downto 0); IsZero : out std_logic ); end component; signal LineAddrDBus : std_logic_vector(11 downto 0); -- 12 bits = 4096 bytes (sólo se usan los 64 * 48 = 3072 primeros bytes) signal LineAddrQBus : std_logic_vector(11 downto 0); signal PixelAddrDBus : std_logic_vector(11 downto 0); signal PixelAddrQBus : std_logic_vector(11 downto 0); signal RomOut : std_logic_vector(7 downto 0); signal PixelDBus : std_logic_vector(7 downto 0); signal PixelQBus : std_logic_vector(7 downto 0); signal HSyncDBus : std_logic; signal HSyncQBus : std_logic; signal VSyncDBus : std_logic; signal VSyncQBus : std_logic; constant FIRST_NO_VISIBLE_LINE_ADDRESS : integer := 3072; -- Dirección de memoria de la primera línea no visible begin -- dirección de inicio de la línea actual de pantalla process (Clk) begin if (Clk'event and (Clk = '1')) then LineAddrQBus <= LineAddrDBus; end if; end process; LineAddrDBus <= std_logic_vector(to_signed(0, 12)) when (LineAddrMux = "01") else std_logic_vector(to_signed(to_integer(signed(LineAddrQBus)) + 64, 12)) when (LineAddrMux = "10") else -- 64 bytes (pixels) por línea LineAddrQBus; LineAddrIsVisible <= '0' when (to_integer(unsigned(LineAddrQBus)) = FIRST_NO_VISIBLE_LINE_ADDRESS) else '1'; -- dirección del actual pixel process (Clk) begin if (Clk'event and (Clk = '1')) then PixelAddrQBus <= PixelAddrDBus; end if; end process; PixelAddrDBus <= LineAddrQBus when (PixelAddrMux = "01") else std_logic_vector(to_signed(to_integer(signed(PixelAddrQBus)) + 1, 12)) when (PixelAddrMux = "10") else -- 1 byte = 1 pixel PixelAddrQBus; -- ROM con la imagen de 64 x 48 pixels (1 byte por pixel, 64 * 48 = 3072 bytes) R : Rom generic map ( Log2NumRows => 12 ) port map ( AddressIn => PixelAddrQBus, DataOut => RomOut ); -- buffer de salida de la ROM (pixel actual) process (Clk) begin if (Clk'event and (Clk = '1')) then PixelQBus <= PixelDBus; end if; end process; PixelDBus <= RomOut when (PixelMux = "10") else std_logic_vector(to_signed(0, 8)) when (PixelMux = "01") else PixelQBus; PixelValue <= PixelQBus; -- contadores C1 : Counter1 port map ( Clk => Clk, Mux => Counter1Mux, IsZero => Counter1IsZero ); C2 : Counter2 port map ( Clk => Clk, Mux => Counter2Mux, IsZero => Counter2IsZero, IsVSync => Counter2IsVSync ); C3 : Counter3 port map ( Clk => Clk, Mux => Counter3Mux, IsZero => Counter3IsZero ); -- acondicionador de señales HSync y VSync process (Clk) begin if (Clk'event and (Clk = '1')) then HSyncQBus <= HSyncDBus; end if; end process; HSyncDBus <= HSyncIn; HSyncOut <= HSyncQBus; process (Clk) begin if (Clk'event and (Clk = '1')) then VSyncQBus <= VSyncDBus; end if; end process; VSyncDBus <= VSyncIn; VSyncOut <= VSyncQBus; end architecture;
La imagen se aloja en una ROM cuyos datos se especifican directamente en el código fuente de Rom.vhd. Para generar la imagen en formato VHDL usando el GIMP se hicieron los siguientes pasos:
- Se creó una nueva imagen de 64 x 48 pixels.
- Menú Ventanas -- Diálogos empotrables -- Paletas -- Botón derecho dentro del listado de paletas -- Importar paleta -- En "Seleccionar origen" se marcó "Archivo de la paleta" y se seleccionó el fichero "vga_fpga.gpl" que se ha incluido dentro del proyecto. Esto creó dentro del GIMP una nueva paleta de 8 colores que se correspondía con los 8 colores que genera nuestra FPGA.
- Se trabajó la imagen de 64x48 con esa paleta.
- Cuando se terminó de trabajar con la imagen, menú Imagen -- Modo -- Indexado -- En "Mapa de colores" se marcó la opción "Usar paleta personal", se seleccionó la paleta acabante de crear a partir del fichero "vga_fpga.gpl", se desmarcó la opción "Eliminar los colores sin usar de la paleta final" y "Aceptar".
- Menú Archivo -- Exportar como -- Se seleccionó como tipo de archivo "Cabecera de código fuente en C (.h)" -- Exportar
Esto creó un fichero .h con un array con el mapa de color (la paleta) y otro array de 3072 bytes con la imagen completa. Afortunadamente el formato de datos de array de C y VHDL es relativamente similar por lo que simplemente hubo que trabajar un poco con el comando "sed" para adaptar los datos. Por ejemplo, un bloque de texto de esta forma:
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,7,
7,0,0,0,0,0,0,0,0,0,0,0,0,0,3,3,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,7,
7,0,0,0,0,0,0,0,0,0,0,0,0,3,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,3,3,3,
3,0,0,3,3,3,0,0,0,0,3,3,3,0,0,0,
Puede convertirse a formato de datos VHDL de esta forma:
$ cat datos.txt | sed -e 's/0/x"00"/g' | sed -e 's/1/x"01"/g' | sed -e 's/2/x"02"/g' | sed -e 's/3/x"03"/g' | sed -e 's/4/x"04"/g' | sed -e 's/5/x"05"/g' | sed -e 's/6/x"06"/g' | sed -e 's/7/x"07"/g'
Generando la salida:
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"07",
x"07",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"03",x"03",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"07",
x"07",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"03",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"03",x"03",x"03",
x"03",x"00",x"00",x"03",x"03",x"03",x"00",x"00",x"00",x"00",x"03",x"03",x"03",x"00",x"00",x"00",
Que es fácilmente incluible en un fichero VHDL como un array (ver Rom.vhd).
Circuito
El circuito externo a la FPGA sólo requiere las líneas de reset, de reloj y de sincronismo conectadas directamente y cada una de las tres líneas de componentes de color (RGB) conectada con una resistencia en serie de 270 Ohm.
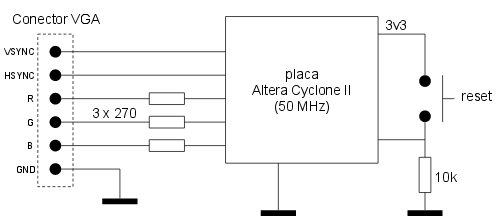
El resultado:


Como siempre, todo el código fuente está disponible en la sección soft.
[ añadir comentario ] ( 3171 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |
( 3 / 6192 ) Calendario
Calendario




