
En un MLP cada neurona tiene una salida y n entradas y se modela de la siguiente manera:
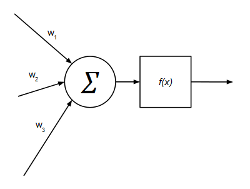
Las entradas de cada neurona suman de forma ponderada (pesos sinápticos) y dicha suma ponderada se hace pasar por una función de activación que, en el caso más general (clasificadores), se trata de la función sigmoide:
$$f(x) = {{1} \over {1+e^{-x}}}$$
Los MLP son estructuras de neuronas organizadas en forma de capas:
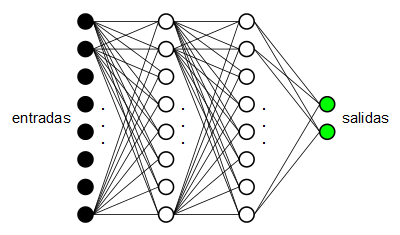
En este caso tenemos un MLP con 8 neuronas de entrada (las neuronas de entrada no son neuronas en sí, se les llama neuronas pero realmente son simplemente las entradas de la red), dos capas (denominadas ocultas) de 8 neuronas cada una y una capa de salida de 2 neuronas.
Los MLP con función de activación sigmoide son más utilizados para reconocimiento y clasificación de patrones. En este caso se abordará este tipo de MLP utilizando el clásico algoritmo de aprendizaje Backpropagation.
Algoritmo Backpropagation
El algoritmo Backpropagation consiste en hacer pasar por la red una serie de patrones predefinidos para los que se indica una salida esperada. La salida real que emite la red para cada uno de los patrones de entrada se compara con la salida esperada y se recalculan los pesos sinápticos hacia atrás (desde la salida hasta la entrada). De ahí el nombre del algoritmo. Los pasos de dicho algoritmo son los siguientes:
Evaluar la red
Se evalúa la red, esto es, para cada neurona desde la capa de entrada hasta la capa de salida se realiza el cálculo de los valores de salida de cada neurona utilizando la ecuación:
$$suma^{o}_{pk} = \sum_{j=1}^{L}w_{kj}^{o}y_{pj} + \theta_{k}^{o}$$
$$y_{pk}=f_{k}^{o}(suma^{o}_{pk})$$
Siendo:
$w_{kj}^{o}$ el peso sináptico de la neurona $j$ de la capa anterior sobre la neurona $k$ de la capa actual.
$f$ la función de activación (en este caso la sigmoide).
Calcular los términos del error
Para cada neurona $k$ de la capa de salida se calcula su error:
$$\delta_{pk}^{o}=(d_{pk}-y_{pk})f_{k}^{'o}(suma_{pk}^{o})$$
Siendo:
$d_{pk}$ el valor deseado para la neurona $k$ de la capa salida y para el patrón de entrada $p$.
$y_{pk}$ el valor actual de la neurona $k$ de la capa de salida para el patrón $p$.
$f'$ la derivada de la función de activación (derivada de la función sigmoide).
Mientras que para cada neurona $j$ de cada capa oculta $h$ el error hay que estimarlo a partir de los errores de la capa siguiente:
$$\delta_{pj}^{h}=f_{j}^{'h}(suma_{pj}^{h})\sum_{k}\delta_{pk}^{o}w_{kj}^{o}$$
Siendo:
$p$ el vector de entrenamiento.
$suma_{pj}^{h}$ la entrada neta (suma ponderada) de la neurona $j$ en la capa $h$ para el vector $p$.
$\delta_{pk}^{o}$ el término de error de la neurona $k$ de la capa anterior.
$w_{kj}^{o}$ el peso de la salida de la neurona $j$ de la capa anterior sobre la neurona $k$.
Actualizar los pesos
$$w_{kj}^{o}(t+1)=w_{kj}^{o}(t)+\Delta w_{kj}^{o}(t+1)$$
$$\Delta w_{kj}^{o}(t+1)=\alpha \delta_{pk}^{o}y_{pj}$$
Siendo:
$w_{kj}^{o}$ el peso de la salida de la neurona $j$ de la capa anterior sobre la neurona $k$.
$y_{pj}$ la salida de la neurona $j$ (la del extremo origen del peso $w_{kj}^{o}$).
Se repite hasta que el error sea aceptable
$$E_{p}={1 \over 2}\sum_{k}\delta_{pk}^{2}$$
Siendo:
$\delta_{pk}$ el error de la neurona $k$ de la capa de salida para el patrón de entrada $p$.
Implementación en punto fijo
En el caso de que queramos implementar una red neuronal de tipo MLP en un sistema embebido sin unidad de coma flotante, debemos intentar realizar una implementación en punto fijo de toda la operativa (tanto evaluación como aprendizaje de la red). Como se puede ver en la ecuaciones mostradas, la parte más compleja viene dada por la función de activación.
$$f(x)={1 \over {1+e^{-x}}}$$
Y por su derivada:
$$f'(x)={{e^{-x}} \over {(1+e^{-x})^2}}$$
Utilizando aproximantes de Padé de orden [3 / 3] para el cálculo de la exponencial podemos aproximar ambas funciones de forma razonablemente buena.
$$e^{x} \simeq {{1+{x \over 2}+{{x^2} \over 10}+{{x^3} \over 120}} \over {1-{x \over 2}+{{x^2} \over 10}-{{x^3} \over 120}}}$$
fixedpoint_t FixedPoint::getExp(fixedpoint_t x) { fixedpoint_t x2 = FP_MUL(x, x); fixedpoint_t x3 = FP_MUL(x2, x); fixedpoint_t num = TO_FP(1) + FP_DIV(x, TO_FP(2)) + FP_DIV(x2, TO_FP(10)) + FP_DIV(x3, TO_FP(120)); fixedpoint_t den = TO_FP(1) - FP_DIV(x, TO_FP(2)) + FP_DIV(x2, TO_FP(10)) - FP_DIV(x3, TO_FP(120)); return FP_DIV(num, den); } [...] fixedpoint_t MultilayerPerceptron::getNetValue(uint8_t numNeuronsPrevLayer, uint8_t currentLayer, uint8_t n) { fixedpoint_t acc = 0; for (uint8_t p = 0; p < numNeuronsPrevLayer; p++) { fixedpoint_t x = this->getNeuronValue(currentLayer - 1, p); fixedpoint_t w = this->getInputWeight(currentLayer, p, n); acc = acc + FP_MUL(x, w); } return acc; } fixedpoint_t MultilayerPerceptron::getSigmoid(fixedpoint_t x) { return FP_DIV(TO_FP(1), TO_FP(1) + FixedPoint::getExp(-x)); } void MultilayerPerceptron::evaluate() { uint8_t numLayers = this->getNumHiddenLayers() + 1; for (uint8_t l = 1; l <= numLayers; l++) { uint8_t numNeurons = this->getNumNeurons(l); uint8_t numNeuronsPrevLayer = this->getNumNeurons(l - 1); for (uint8_t n = 0; n < numNeurons; n++) { fixedpoint_t acc = this->getNetValue(numNeuronsPrevLayer, l, n); fixedpoint_t y = MultilayerPerceptron::getSigmoid(acc); this->setNeuronValue(l, n, y); } } }
Para el algoritmo de entrenamiento Backpropagation es necesario utilizar la derivada de la función de activación. Esta derivada puede simplificarse y ponerse en función de la propia función sigmoide:
$$f'(x)={{e^{-x}} \over {(1+e^{-x})^2}}={1 \over {1+e^{-x}}}{{e^{-x}} \over {1+e^{-x}}}=f(x){{e^{-x}} \over {1+e^{-x}}}$$
$$f'(x)=f(x){{1+e^{-x}-1} \over {1+e^{-x}}}=f(x)\left({{1+e^{-x}} \over {1+e^{-x}}}-{1 \over {1+e^{-x}}}\right)$$
$$f'(x)=f(x)\left(1-{1 \over {1+e^{-x}}}\right)=f(x)(1-f(x))$$
Por tanto, para la función sigmoide, se cumple que:
$$f'(x)=f(x)(1-f(x))$$
Como $f(x)$ se corresponde con la salida de cada neurona (siendo $x$ la suma ponderada de sus entradas), la derivada de la salida de cada neurona puede calcularse, por tanto, de esta manera:
$$salida(1-salida)$$
En el algoritmo de entrenamiento Backpropagation esto simplifica enormemente el cálculo de los términos de error ya que se puede calcular la derivada de cada neurona a partir de su valor de salida.
fixedpoint_t MultilayerPerceptron::getEstimatedError(uint8_t layer, uint8_t n) { uint8_t numLayers = this->getNumHiddenLayers() + 1; fixedpoint_t ret = 0; if (layer == numLayers) { fixedpoint_t out = this->getNeuronValue(layer, n); ret = (this->getDesiredOutput(n) - out); } else { uint8_t numNeuronsNextLayer = this->getNumNeurons(layer + 1); for (uint8_t k = 0; k < numNeuronsNextLayer; k++) { fixedpoint_t e = this->getNeuronErrorValue(layer + 1, k); fixedpoint_t w = this->getInputWeight(layer + 1, n, k); ret += FP_MUL(e, w); } } return ret; } void MultilayerPerceptron::backpropagate(uint8_t layer, fixedpoint_t *totalError) { if (totalError != NULL) *totalError = 0; uint8_t numNeurons = this->getNumNeurons(layer); for (uint8_t n = 0; n < numNeurons; n++) { fixedpoint_t out = this->getNeuronValue(layer, n); fixedpoint_t aux = FP_MUL(out, TO_FP(1) - out); // derivada de la función de activación fixedpoint_t error = FP_MUL(aux, this->getEstimatedError(layer, n)); this->setNeuronErrorValue(layer, n, error); if (totalError != NULL) *totalError += FP_MUL(error, error); } uint8_t numNeuronsPrevLayer = this->getNumNeurons(layer - 1); for (uint8_t n = 0; n < numNeurons; n++) { fixedpoint_t e = this->getNeuronErrorValue(layer, n); for (uint8_t k = 0; k < numNeuronsPrevLayer; k++) { fixedpoint_t y = this->getNeuronValue(layer - 1, k); fixedpoint_t w = this->getInputWeight(layer, k, n); w = w + FP_MUL(this->trainRate, FP_MUL(e, y)); this->setInputWeight(layer, k, n, w); } } } void MultilayerPerceptron::train(uint8_t times, fixedpoint_t &totalError) { while (times > 0) { uint8_t outputLayer = this->getNumHiddenLayers() + 1; for (uint8_t l = outputLayer; l >= 1; l--) { fixedpoint_t *e = (l == outputLayer) ? &totalError : NULL; this->backpropagate(l, e); } this->commitInputWeights(); times--; } }
Se ha utilizado como tipo funto fijo el formato Q16.16 mapeado sobre un entero de 32 bits (int32_t), esto nos da una precisión de
$$2^{-16} = 0,0000152587890625$$
Un error bastante aceptable teniendo en cuenta lo que vamos a ganar en velocidad.
typedef int32_t fixedpoint_t; #define FP_FRACTIONAL_BITS 16 #define FP_MUL(x, y) ((((int64_t) (x)) * ((int64_t) (y))) >> 16) #define FP_DIV(x, y) ((((int64_t) (x)) << 16) / ((int64_t) (y))) #define TO_FP(x) (((int32_t ) (x)) << 16)
Pruebas realizadas
Las pruebas se han realizado partiendo de dos patrones de entrenamiento sencillos:
$p_{1}=\{0, 0, 0, 0, 0, 1, 1, 1\}$ que debe generar la salida $\{0, 1\}$.
$p_{2}=\{0, 1, 1, 0, 0, 0, 0, 1\}$ que debe generar la salida $\{1, 0\}$.
Con los que se han obtenido muy buenos resultados:
Para el patrón $p_{1}$ se obtiene, tras el entrenamiento, la salida $$\{0.0270996, 0.972183\}$$
Para el patrón $p_{2}$ se obtiene, tras el entrenamiento, la salida $$\{0.971191, 0.0284729\}$$
Todo el código fuente puede descargarse de la sección soft.
[ añadir comentario ] ( 2777 visualizaciones ) | [ 0 trackbacks ] | enlace permanente |

 ( 3 / 5741 )
( 3 / 5741 ) Calendario
Calendario




