
Principios
Un sistema con multitarea apropiativa debe por tanto poseer mecanismos que permitan interrumpir la ejecución de la tarea actualmente en curso y que permitan también reanudar la ejecución de otra tarea que haya sido interrumpida previamente. Este mecanismo debería ser lo más transparente al usuario (a las tareas) posible por lo que normalmente se utilizan las interrupciones. Las interrupciones en la totalidad de los procesadores que las implementan (no conozco ningún procesador que no las tenga) permiten ejecutar código de forma no solicitada por la tarea actualmente en ejecución y a raiz de un evento externo al flujo actual de la tarea.
En el momento que se produce la interrupción (la causa puede ser externa al procesador: entradas de datos, pines de entrada que cambian de estado o interna: división entre cero, instrucción no reconocida, etc.) el procesador almacena en la pila del sistema la dirección de la siguiente instrucción que se va a ejecutar y hace que el contador de programa apunte a la primera instrucción del código de interrupción. Este código de interrupción que se ejecuta a raiz del evento suele denominarse ISR (Interrupt Service Routine).
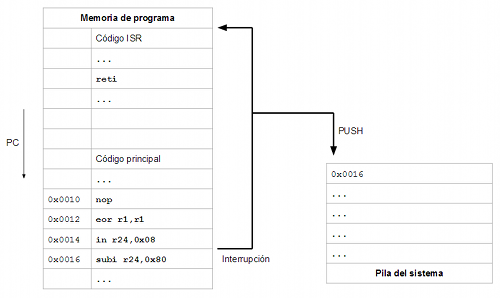
Normalmente existirán diferentes orígenes de interrupción y diferentes vectores de interrupción. Por ejemplo un procesador podría tener dos orígenes de interrupción (el cambio de estado de un pin de entrada y el desbordamiento de un contador interno) y un solo vector de interrupción por lo que se ejecutará la misma ISR para cualquiera de los dos eventos que se produzca. En estos casos, obviamente, el procesador siempre provee mecanismos para que la ISR sea capaz de discernir cuál ha sido la causa de que ella se esté ejecutando (algún registro de estado, por ejemplo).
Lo normal es tener aproximadamente la misma cantidad de orígenes de interrupción que de vectores de interrupción, de tal forma que podemos definir una ISR para cada origen de interrupción. Nótese que una ISR no es más que un trozo de código. En algunos sistemas las ISR no se diferencian en nada de una función normal (por ejemplo, ARM Cortex-M) que debe terminar como todas las funciones con algún tipo de instrucción "ret", mientras que en otros sistemas se debe utilizar algun tipo de instrucción especial normalmente a la hora de regresar: por ejemplo los microcontroladores AVR deben terminar sus funciones ISR con la instrucción "reti" (RETurn from Interrupt). Sin embargo, salvo estas excepciones, dentro de una ISR se puede poner el código que se quiera: no deja de ser un trozo de código como cualquier otro.
Una ISR sencillita
Consideremos inicialmente una ISR sencillita que vamos a compilar para Arduino Leonardo (microcontrolador ATmega32U4):
#include <avr/interrupt.h> #include <avr/io.h> #include <stdint.h> using namespace std; ISR(TIMER0_OVF_vect) { PORTC ^= 0x80; } int main() { PRR1 |= 0x80; DDRC |= 0x80; TCCR0B |= 0x05; TIMSK0 |= 0x01; sei(); while (true) ; return 0; }
$ /ruta/avr/bin/avr-g++ -std=c++11 -DF_CPU=16000000UL -mmcu=atmega32u4 -Os -g -c -o test.o test.cc
$ /ruta/avr/bin/avr-g++ -std=c++11 -DF_CPU=16000000UL -mmcu=atmega32u4 -Os -c -o test.elf test.o
Como se puede ver, usando el compilador avr-g++ se puede hacer de forma muy sencilla un código con soporte para interrupciones en C++. En este caso tenemos un sencillo blinker de toda la vida: cada vez que el Timer 0 se desborda se cambia el estado del bit de salida y hace cambiar de estado a su vez un led conectado a él. Para comprobar de forma detallada cómo funciona el invento podemos desensamblar el fichero ELF generado por el compilador:
$ /ruta/avr/bin/avr-objdump -D test.elf
En la dirección 0 de la memoria tenemos los diferentes vectores de interrupción. Como se puede apreciar está definido el vector 0 (denominado vector de reset ya que en muchos procesadores, como el AVR, el reset se trata como una interrupción más por lo que el vector de reset indica qué código debe ejecutarse nada más encenderse el procesador) y el vector 23 (que se corresponde en el ATmega32U4 con la interrupción de desbordamiento del Timer 0):
Disassembly of section .text:
00000000 <__vectors>:
0: 0c 94 56 00 jmp 0xac ; 0xac <__ctors_end>
4: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
8: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
10: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
14: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
18: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
1c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
20: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
24: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
28: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
2c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
30: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
34: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
38: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
3c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
40: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
44: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
48: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
4c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
50: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
54: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
58: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
5c: 0c 94 62 00 jmp 0xc4 ; 0xc4 <__vector_23>
60: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
64: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
68: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
6c: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
70: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
74: 0c 94 60 00 jmp 0xc0 ; 0xc0 <__bad_interrupt>
Si nos vamos al código que ha generado el compilador para la ISR correspondiente al vector 23:
000000c4 <__vector_23>:
c4: 1f 92 push r1
c6: 0f 92 push r0
c8: 0f b6 in r0, 0x3f ; 63
ca: 0f 92 push r0
cc: 11 24 eor r1, r1
ce: 8f 93 push r24
d0: 88 b1 in r24, 0x08 ; 8
d2: 80 58 subi r24, 0x80 ; 128
d4: 88 b9 out 0x08, r24 ; 8
d6: 8f 91 pop r24
d8: 0f 90 pop r0
da: 0f be out 0x3f, r0 ; 63
dc: 0f 90 pop r0
de: 1f 90 pop r1
e0: 18 95 reti
Vemos que lo primero que hace la ISR es guardar en la pila (PUSH) los registros R1, R0, SREG y R24 que son registros que utiliza ("ensucia") para hacer la operación:
PORTC ^= 0x80;
Y, tras realizar dicha operación, restaura de nuevo dichos registros en orden inverso desde la pila (POP) antes de regresar (RETI). Esta forma de operar hace que la tarea principal (el bucle infinito que hay en la función "main") no se da cuenta de que es interrumpido de forma periódica ya que la ISR se encarga de salvaguardar y restaurar los registros que utiliza de forma transparente. La función "main" como mucho puede notar que cada cierto tiempo, entre instrucción e instrucción, pasan más ciclos de lo normal :-).
Conmutación entre tareas
Como se comentó más arriba, cuando se produce una interrupción, los procesadores guardan siempre en la pila la dirección a donde el contador de programa (PC) debe regresar una vez que la interrupción ha terminado de servirse (cuando la ISR termine de ejecutarse). En el caso del ATmega32U4 el procesador empuja en la pila 3 bytes en dos de los cuales almacena la dirección de memoria de la siguiente instrucción que iba a ejecutar (aunque el ATmega32U4 tiene un espacio de direccionamiento de 16 bits, el núcleo AVR que utiliza es el mismo que tienen otros procesadores AVR que tienen un espacio de direcciones de más de 16 bits, de ahí los 3 bytes que se reservan en la pila para la dirección de retorno de la interrupción).
Si lo que queremos es conmutar entre tareas lo que hay que hacer nada más empezar la ejecución de la función ISR es guardar absolutamente todo el estado del procesador y esto se consigue en el caso de AVR apilando los 32 registros generales (desde R0 hasta R31) más el registro de estado SREG en la pila del sistema (PUSH).
ISR(TIMER0_OVF_vect) __attribute__ ((naked)); ISR(TIMER0_OVF_vect) { asm volatile ( "push r0\n" "push r1\n" "push r2\n" "push r3\n" "push r4\n" "push r5\n" "push r6\n" "push r7\n" "push r8\n" "push r9\n" "push r10\n" "push r11\n" "push r12\n" "push r13\n" "push r14\n" "push r15\n" "push r16\n" "push r17\n" "push r18\n" "push r19\n" "push r20\n" "push r21\n" "push r22\n" "push r23\n" "push r24\n" "push r25\n" "push r26\n" "push r27\n" "push r28\n" "push r29\n" "push r30\n" "push r31\n" "in r0, 0x3f\n" "push r0\n"
A continuación, y como el top de la pila es algo cambiante a medida que se va ejecutando código, guardamos en una variable global la dirección de memoria del actual top de la pila: esto nos permitirá acceder cómodamente a los registros que acabamos de guardar independientemente de que empujemos más cosas en ella:
// update stackPointerReference "push r0\n" "in r0, 0x3e\n" "sts stackPointerReference + 1, r0\n" // sph "in r0, 0x3d\n" "sts stackPointerReference, r0\n" // spl "pop r0\n" ); stackPointerReference = (volatile uint8_t *) ((((uint32_t) stackPointerReference) + 1) | 0x800000); // 23-th bit to 1 for SRAM address space
Poner a 1 el bit 23 del puntero stackPointerReference es un artificio necesario en avr-gcc ya que en ese entorno de compilación esa es la forma en la que se diferencian los punteros a memoria de datos de los punteros a memoria de programa (hay que recordar que los AVR tienen arquitectura Harvard).
Tras tener adecuadamente inicializado el puntero "stackPointerReference" podemos proceder a realizar la conmutación de tareas en sí. En nuestro caso se asume una política de tipo Round-robin en la que todas las tareas tienen exactamente el mismo tiempo de proceso. Lo que haremos será, partiendo de una lista de N tareas, cada vez que se ejecute la interrupción de desbordamiento del Timer 0, cambiaremos de la tarea i-ésima a la tarea ((i + 1) MOD N)-ésima, con lo que nos aseguramos que cuando llegamos a la última tarea de la lista volvemos a empezar por la primera y así sucesivamente.
Para cada tarea definimos un objeto de clase Task:
class StackFrame { public: uint8_t sreg; uint8_t r[32]; uint8_t pc[3]; void setPC(void *f) { this->pc[0] = 0; this->pc[1] = ((uint32_t) f) & 0x000000FF; this->pc[2] = ((((uint32_t) f) >> 8) & 0x000000FF); }; } __attribute__ ((packed)); class Task { public: StackFrame stackFrame; bool started; void (*run)(); Task() : started(false) { }; };
Cada tarea tiene una copia del marco de pila ("stack frame") de la última vez que fue interrumpida, un booleano para indicar si la tarea ha sido iniciada o no y un puntero a una función que apunta a la primera instrucción de dicha tarea. En nuestro caso vamos a asumir, sin pérdida de generalidad, que nuestras tareas nunca terminan (no vamos a controlar lo que ocurre cuando la tarea termine).
Definimos además de forma global un array de punteros a objetos de tipo Task, una variable "currentTaskIndex" que indica la actual tarea que está en ejecución y el puntero "stackPointerReference" del que hablamos antes.
const uint16_t MAX_TASKS = 4; volatile uint16_t numTasks; volatile Task tasks[MAX_TASKS]; volatile uint16_t currentTaskIndex; volatile uint8_t *stackPointerReference;
Los primero que hacemos tras calcular el valor de "stackPointerReference" es trabajar con la tarea actual:
Task *currentTask = (Task *) &tasks[currentTaskIndex]; if (currentTask->started) { // copy stack data to currentTask->stackFrame memcpy((void *) ¤tTask->stackFrame, (const void *) (stackPointerReference + 1), sizeof(StackFrame)); } else { // replace return address on currentTask->data with currentTask->run memset((void *) ¤tTask->stackFrame, 0, sizeof(StackFrame)); currentTask->stackFrame.setPC((void *) currentTask->run); }
Si ya está iniciada copiamos los registros que acabamos de apilar (en los PUSH masivos que hicimos al principio de la ISR) al campo "stackFrame" del objeto Task correspondiente a la tarea actual: esto es, ponemos a salvo los registros de la tarea actual pues nos disponemos a hacer una conmutación a la siguiente tarea.
En caso de que la tarea actual no esté iniciada lo que hacemos es borrar el campo "stackFrame" del objeto Task correspondiente a la tarea actual e inicializamos, dentro de esta estructura "stackFrame", los bytes correspondientes al contador de programa para que apunten a la primera instrucción de la tarea actual. Esto hará que cuando se restaure el marco de pila ("stack frame") de esta tarea se inicie dicha tarea (puesto que el contador de programa irá a la primera instrucción de dicha tarea).
A continuación trabajamos con el objeto de tipo Task correspondiente a la tarea siguiente:
uint16_t nextTaskIndex = currentTaskIndex + 1; if (nextTaskIndex == numTasks) nextTaskIndex = 0; Task *nextTask = (Task *) &tasks[nextTaskIndex]; if (nextTask->started) { // replace stack data with nextTask->stackFrame memcpy((void *) (stackPointerReference + 1), (const void *) &nextTask->stackFrame, sizeof(StackFrame)); } else { // replace return address on stack with nextTask->run ((StackFrame *) (stackPointerReference + 1))->setPC((void *) nextTask->run); nextTask->started = true; }
En caso de que la siguiente tarea a iniciar ya esté iniciada ("started") simplemente sobreescribimos todo el marco de pila (los datos que metimos en la pila con los PUSH masivos del principio de la ISR) con los bytes de campo "stackFrame" de la siguiente tarea, lo que provocará una conmutación a la tarea siguiente en el momento que retornemos de la interrupción. En caso de que la siguiente tarea no esté iniciada aún hacemos lo mismo que en caso de la tarea actual: inicializamos, dentro de la estructura "stackFrame" los bytes correspondientes al contador de programa para que apunten a la primera instrucción de la tarea siguiente y, a continuación, marcamos la tarea como iniciada ("started = true").
Antes de terminar actualizamos la variable global "currentTaskIndex" para que apunte a la tarea a la que se le va a entregar el control de la CPU y hacemos una restauración normal de la pila (POP masivos) antes de terminar definitivamente con la instrucción "RETI".
currentTaskIndex = nextTaskIndex; asm volatile ( "pop r0\n" "out 0x3f, r0\n" "pop r31\n" "pop r30\n" "pop r29\n" "pop r28\n" "pop r27\n" "pop r26\n" "pop r25\n" "pop r24\n" "pop r23\n" "pop r22\n" "pop r21\n" "pop r20\n" "pop r19\n" "pop r18\n" "pop r17\n" "pop r16\n" "pop r15\n" "pop r14\n" "pop r13\n" "pop r12\n" "pop r11\n" "pop r10\n" "pop r9\n" "pop r8\n" "pop r7\n" "pop r6\n" "pop r5\n" "pop r4\n" "pop r3\n" "pop r2\n" "pop r1\n" "pop r0\n" "reti\n" ); }
Para la prueba de concepto se implementaros dos tareas muy sencillas: cada una hace parpadear un led a una velocidad diferente:
void task1() __attribute__ ((naked)); void task1() { DDRD |= 0x04; // PD2 (D0 on Arduino Leonardo) as output while (true) { PORTD ^= 0x04; for (volatile uint32_t i = 0; i < 66000; i++) ; } } void task2() __attribute__ ((naked)); void task2() { DDRC |= 0x80; // PC7 (D13 on Arduino Leonardo) as output while (true) { PORTC ^= 0x80; for (volatile uint32_t i = 0; i < 200000; i++) ; } }
Consideraciones adicionales
Nótese que tanto la ISR como las funciones "tarea" ("task1" y "task2") son declaradas con el atributo "naked". Este atributo indica al compilador que no genere código preámbulo ni postámbulo (el código ensamblador relacionado normalmente con el manejo de parámetros y valores de retorno).
En el caso de las funciones "task1" y "task2" se ha usado este atributo por una cuestión de coherencia ya que no se trata de funciones que son invocadas de forma normal desde otra parte del programa y además se trata de funciones que no terminan nunca de ejecutarse.
El caso de la función ISR es más delicado porque en ese caso sí que es necesario usar el atributo "naked". Como se vió en la primera prueba con la interrupción del Timer 0, para el siguiente código:
ISR(TIMER0_OVF_vect) {
PORTC ^= 0x80;
}
El compilador generaba instrucciones PUSH y POP de los registros que utilizaría, antes y después de la operación "PORTC ^= 0x80" respectivamente. En nuestro caso necesitamos que el apilado (PUSH) y desapilado (POP) de registros sea siempre igual y masivo y que esté perfectamente controlado por nosotros por lo que definimos la función con el atributo "naked" y nos encargamos nosotros de escribir de forma explícita el código ensamblador de preámbulo y postámbulo de la ISR.
Todo el código puede descargarse de la sección soft.
Lo sentimos. No se permiten nuevos comentarios después de 90 días.
 Calendario
Calendario




