
Placa de ejemplo
Como placa de ejemplo he usado una placa recién adquirida por AliExpress, en concreto un clon de la QMTech XC6SLX16 SDRAM Core Board, una placa que incluye una FPGA Spartan 6 de Xilinx, un oscilador a 50 MHz, una SDRAM de 32 Mb, una flash SPI de 8 Mbit (para almacenar la configuración no volátil de la FPGA), varios leds y múltiples puestos de entrada/salida. El clon que se puede adquirir por AliExpress es exactamente igual que la placa original. Me costó unos 19¤ con los gastos de envío incluidos.
Programador de ejemplo
Como interface de programación se ha optado por usar un conversor USB a UART/SPI/I2C/JTAG basado en el chip FT232H. En concreto he usado este por ser una opción barata y de buena calidad de construcción. Costó unos 9¤ con los gastos de envío incluidos.
Prueba de concepto
Instalamos el entorno ISE WebPack de Xilinx (la última versión disponible con soporte para Spartan 6 es la 14.7. No es necesario instalar los drivers de programación), lo abrimos y creamos un nuevo proyecto para la FPGA XC6SLX16, con encapsulado FTG256 y velocidad -2.
Yo llamé al proyecto "Spartan6Blinker" y dentro de él creé un único módulo VHDL al que llamé "Spartan6Blinker.vhd" con el siguiente código:
library IEEE; use IEEE.STD_LOGIC_1164.ALL; use IEEE.NUMERIC_STD.ALL; entity Spartan6Blinker is Port ( Clk : in std_logic; D1Led : out std_logic ); end entity; architecture A of Spartan6Blinker is constant COUNTER_WIDTH : integer := 23; signal CounterDBus : std_logic_vector((COUNTER_WIDTH - 1) downto 0); signal CounterQBus : std_logic_vector((COUNTER_WIDTH - 1) downto 0); begin process (Clk) begin if (Clk'event and (Clk = '1')) then CounterQBus <= CounterDBus; end if; end process; CounterDBus <= std_logic_vector(to_unsigned(to_integer(unsigned(CounterQBus)) + 1, COUNTER_WIDTH)); D1Led <= CounterQBus(COUNTER_WIDTH - 1); end architecture;
Como se puede ver es un sencillo contador incremental de 23 bits sin control de desbordamiento (se va incrementando desde 0 hasta (2^23 - 1) y vuelta a empezar) y lo único que hacemos es conectar el bit más significativo del registro contador a la salida del led D1.
A continuación añadimos un nuevo fichero fuente de tipo UCF (Implementation Constraints File) al que llamamos "QMTechSpartan6Board.ucf" (podemos ponerle el nombre que queramos) y le metemos el siguiente contenido:
NET Clk LOC = A10 | IOSTANDARD = LVCMOS33;
NET D1Led LOC = T9 | IOSTANDARD = LVCMOS33;
Lo que hemos hecho es definir en qué pines concretos está la entrada de reloj y la salida hacia el led D1. Estos datos están disponibles en el repositorio de Github de QMTech.
Hacemos doble click en "Generate Programming File" y esperamos a que termine todo el proceso de compilación y síntesis del VHDL. Este proceso generará un fichero llamado "Spartan6Blinker.bit" en la carpeta del proyecto, que es el fichero que se manda a la FGPA o se tosta en la flash SPI.
Por ultimo, nos vamos a una consola, nos descargamos el código fuente del programa xc3sprog en una carpeta aparte:
mkdir -p /opt/src
cd /opt/src
git clone https://github.com/buserror/xc3sprog.git
Y seguimos las instrucciones del fichero README para compilarlo.
Programar directamente la FPGA
Para programar la FPGA lo que hacemos es conectarle el programador basado en FT232H de la siguiente manera:
FT232H Spartan 6
AD0 --------- TCK
AD1 --------- TDI
AD2 --------- TDO
AD3 --------- TMS
GND --------- GND
Conectamos a continuación la placa Spartan 6 a la alimentación de 5 voltios, la placa FT232H al USB de nuestro ordenador y ejecutamos el xc3sprog de la siguiente manera:
cd /opt/src/xc3sprog/build
./xc3sprog -c ft232h /RUTA_CARPETA_PROYECTO/Spartan6Blinker.bit
Programar la flash SPI
Con el programador FT232H conectado de la misma forma, grabamos en la RAM de la FPGA una configuración que nos permitirá transferir datos entre JTAG y la flash SPI:
cd /opt/src/xc3sprog/build
./xc3sprog -c ft232h ../bscan_spi/xc6slx16_cs324.bit
Y a continuación transferimos nuestro fichero bit indicando que es para la flash:
./xc3sprog -c ft232h -I /RUTA_CARPETA_PROYECTO/Spartan6Blinker.bit
De esta forma la FPGA, nada más arrancar, cargará nuestro blinker (sin necesidad de que esté conectada por JTAG).

[ añadir comentario ] ( 1272 visualizaciones ) | [ 0 trackbacks ] | enlace permanente
Tweet | |


 ( 3 / 2509 )
( 3 / 2509 )Como todos los años cuando se acercan las fechas navideñas siempre trato de revisitar el concepto de luces del Belén aprovechando los conocimientos adquiridos en el último año. En este caso, entendiendo que el concepto de luces a secas ya hay que superarlo :-), se ha introducido una componente móvil en el Belén de este año: un cielo artificial con ciclo día-noche.
La rueda del cielo
Para simular un cielo que cambia entre día y noche se ha optado por una solución muy sencilla basada en un disco de cartón de medio metro de diámetro, aproximadamente, a cuyo eje se conecta directamente un motor paso a paso con una reductora. El motor girará lentamente a razón de una vuelta cada día.
Colocando el motor encima del mueble sobre el que se va a colocar el belén, con el eje apuntando a la pared, se puede colocar el disco de cartón de tal manera que sólo sea visible la mitad superior del mismo. De esta manera se puede pintar medio disco de cartón como si fuese de día (azul celeste, por ejemplo) y la otra mitad del disco de negro con el firmamento y la estrella de Belén, por ejemplo.

Electrónica de control de la rueda del cielo
El motor elegido para acoplar la rueda del cielo es el conocido y asequible 28BYJ-48 (que venden en AliExpress junto con la placa controladora a unos 2 ¤ en el momento de escribir estas líneas). Se trata de un motor paso a paso de 4 bobinas (4 pasos enteros u 8 medios pasos) y con una reductora interna que nos da una resolución teórica de 4096 medios pasos por vuelta (por cuestiones mecánicas, en realidad son medios 4076 pasos por vuelta, según comenta Luis Llamas en su blog).
La placa controladora tiene cuatro entradas digitales correspondientes cada una a una de las 4 bobinas del motor. Activando alternativamente las entradas 1, 2, 3, 4, 1, 2, 3, 4... hacemos girar el motor en un sentido, mientras que activando alternativamente las entradas 4, 3, 2, 1, 4, 3, 2, 1... hacemos girar el motor en el sentido opuesto. A aquellas personas que no estén familiarizadas con los motores paso a paso o con este motor paso a paso en particular les recomiendo esta entrada del blog de Luis Llamas, donde está magníficamente explicado.
La idea es hacer un circuito que haga que el motor paso a paso se mueva lentamente de manera que de una vuelta entera cada 24 horas (para simular el ciclo día-noche en el disco de cartón). Al diseño hay que añadirle botones de avance y retroceso rápido para que el disco pueda "calibrarse" o "sincronizarse" manualmente de forma sencilla (hay que recordar que no es necesaria una precisión milimétrica, es para un Belén). A continuación un diagrama del circuito a implementar en el CPLD:
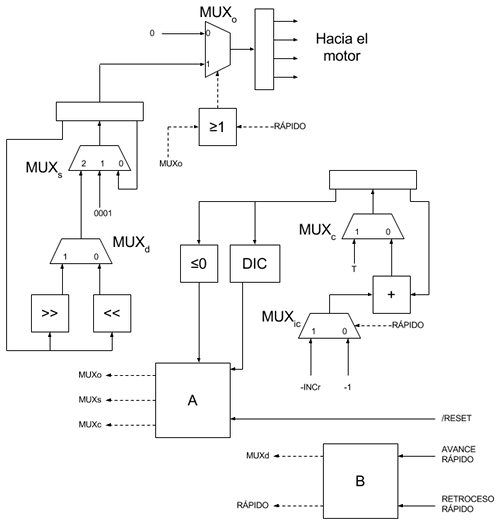
El circuito consta de tres registros:
- Uno que actúa como latch de salida.
- Otro que actúa de registro de rotación.
- Otro que actúa como contador.
El multiplexor que controla el valor del latch de salida (MUXo) permite elegir entre la salida del registro de rotación o todo ceros, el multiplexor que controla el valor del registro de rotación (MUXs)permite elegir entre mantener el valor (realimentación directa), cargar un valor "0001" (para cuando se inicializa el circuito) o cargar una versión rotada de la salida actual del registro de rotación (en un sentido u otro dependiento de otro multiplexor, MUXd). El multiplexor que controla el registro contador (MUXc) permite elegir entre cargar el valor de reset del contador (T) o cargar el valor decrementado. La constante con la que se decrementa el registro contador debe variar en función de la velocidad a la que queramos que se mueva el disco y está controlada por otro multiplexor (MUXic).
El resto de bloques que aparecen en el esquema son circuitos combinacionales:
- El bloque "<=0" genera un 1 si el valor del contador (con signo) es menor o igual a cero.
- El bloque "DIC" (Dentro Intervalo Cuenta) genera un 1 a su salida si el valor del registro contador está dentro de un intervalo de valores. Esto se utiliza para evitar que las bobinas del motor paso a paso consuman mucho ya que para girar el rotor un paso basta con generar un pulso lo suficientemente ancho en la bobina correspondiente y luego dejar el motor en reposo (la reductora hace que el motor rotor esté prácticamente frenado en ausencia de pulsos).
- El bloque ">=1" es una puerta OR. Cuando se está haciendo avance o retroceso rápido, el multiplexor de salida hace de buffer del registro de rotación, pero cuando no estamos girando rápido, hay que activar las bobinas el motor sólo el tiempo necesario para evitar que el circuito consuma mucha corriente. De esta forma aunque el registro de rotación tenga el valor "0100" el registro de salida sólo tendrá el valor "0100" el tiempo necesario para excitar la bobina correspondiente y, a continuación, emitirá un "0000" aunque en el registro de rotación siga estando el valor "0100".
- El bloque "+" es un bloque sumador estándar. El encargado de ir decrementando el registro contador.
Funcionamiento
Los otros dos bloques combinacionales (abajo a izquierda y derecha) son los encargados de controlar todo el conjunto. Veamos primero el bloque combinacional de abajo a la izquierda:
| Entradas | Salidas | ||||
|---|---|---|---|---|---|
| DIC | /RESET | <=0 | MUXs | MUXc | MUXo |
| X | 0 | X | 1 | 1 | 0 |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 |
| X | 1 | 1 | 2 | 1 | 0 |
Cuando la entrada /RESET se pone a 0, MUXs selecciona la entrada "0001", MUXc selecciona la entrada del valor de reset del contador (T) y MUXo selecciona la entrada "0000", por lo que en el siguiente ciclo de reloj el registro de salida se pondrá a cero, el registro contador se cargará con el valor T y el registro de rotación se cargará con el valor "0001".
Una vez que /RESET se pone a 1, como el registro contador vale T (se trata de un contador decremental), tanto las entradas C como DIC están a cero por lo que MUXs selecciona la entrada de realimentación (para mantener el valor actual del registro de rotación), MUXc selecciona la entrada procedente del sumador y MUXo sigue seleccionando la entrada con el valor "0000" (la salida del latch que va al motor sigue siendo "0000") por ahora.
Hay que tener en cuenta que, como el MUXc está selecionando la entrada procedente del sumador, cada ciclo de reloj que pasa, el valor del contador se decrementa. En algún momento el valor del contador entrará dentro del intervalo configurado para el bloque combinacional DIC y este bloque empezará a emitir un 1. Esto provoca que el MUXo seleccione la entrada procedente del registro de rotación por lo que se emitirá el valor almacenado en dicho registro hacia el motor durante el tiempo que el valor del contador genere un 1 a la salida del bloque DIC. Cuando el contador baje por debajo del umbral inferior del bloque comparador DIC, la salida de este bloque será de nuevo 0 y la salida del registro de salida volverá a ser "0000" de nuevo. El tiempo que el bloque comparador DIC emite un 1 debe ser suficiente como para que se exciten adecuadamente las bobina del motor (en mi caso lo he puesto para que las active durante un segundo, más que suficiente).
Una vez que el registro de salida ha vuelto a "0000" el registro contador continúa su camino hacia el cero. Cuando llega a cero (o lo sobrepasa hacia el negativo), el bloque "<=0" emite un 1. Esta condición hace que el MUXs seleccione la entrada de rotación (para que se active la siguiente bobina del motor y el rotor gire un poquito), que el MUXc seleccione la entrada del valor iniciar T (para que se cargue el contador con el valor inicial) y que el MUXo seleccione la entrada "0000" (para seguir emitiendo ceros).
Esto provoca que todo el ciclo empiece de nuevo por lo que tendremos que, calculando bien el valor de T y los valores umbral del bloque comparador DIC conseguiremos un disco dia-noche que de una vuelta entera una vez cada 24 horas.
Si el motor paso a paso da una vuelta completa cada 4076 medios pasos y nosotros vamos a utilizarlo con pasos enteros, cará una vuelta cada ${4076 \over 2} = 2038$ pasos enteros. Por tanto si queremos que de una vuelta entera cada día tendrán que pasar:
$${{24 \times 60 \times 60} \over 2038} = 42.3945 \ \ segundos/paso$$
Como el reloj va a 50 MHz el valor de T será de:
$${{24 \times 60 \times 60} \over 2038} \times 50000000 \approx 2119725221 \ \ ciclos/paso$$
Con este valor de T podemos hacer que el bloque DIC emita un 1 cuando:
$$2119725000 > contador > 2069725220$$
50000000 de ciclos de diferencia (1 segundo). Y un 0 en el resto de los casos.
El bloque combinacional de abajo a la derecha es el encargado de controlar el avance y retroceso rápidos.
| Entradas | Salidas | ||
|---|---|---|---|
| Avance rápido | Retroceso rápido | MUXd | Rápido |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | X | 0 | 1 |
En función de los valores de las entradas de avance rápido y retroceso rápido, el multiplexor MUXd seleccionará un sentido de rotación u otro. Además, en caso de que se pulse cualquiera de los dos botones, el registro latch de salida selecciona siempre la entrada proveniente del registro de rotación: cuando estamos haciendo avance y retroceso rápido los pulsos de activación serán tan cortos que no será necesario usar el mecanismo del bloque DIC para controlar la anchura de los pulsos de activación de las bobinas.

Luces para el cielo nocturno
Para rizar el rizo y aprovechando que tenía por aquí un CPLD chico de 64 macroceldas (el EPM3064A de Altera, unos 6 ¤ por aliexpress) me aventuré a colocar unas luces en la parte "nocturna" del disco giratorio. Una pila de botón de tipo CR2032 es más que suficiente para alimentar el CPLD y los 5 leds que se usan para simular las estrellas.

En este caso se ha realizado una implementación simplificada del diseño publicado en este post. En lugar de incluir un comparador y un latch se ha optado por emitir directamente hacia los leds, cinco de los bits del registro LFSR de 10 bits.
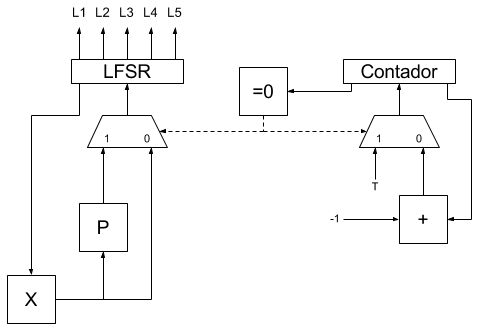
Si el reloj del CPLD va a 50 MHz (como en nuestro caso) y queremos que las luces cambien cada segundo, T debe valer 50000000. La descripción del resto de bloques combinacionales es la siguiente:
- El bloque "P" es el bloque que aplica el polinomio de realimentación maximal para 10 bits al valor actual del registro LFSR (una puerta XOR más un desplazamiento). Al ser un polinomio maximal de 10 bits el registro LFSR generará una secuencia de números pseudoaleatoria comprendida entre los valores 1 y 1023 (el valor 0 está fuera de la secuencia y en caso de que se alcance dicho valor, el LFSR se "para").
- El bloque "X" es un bloque que, en caso de que la entrada valga "0000000000" en la salida emite "0000000001", en caso contrario emite la entrada sin cambiar. Este bloque se coloca para garantizar que si el LFSR se pone totalmente a 0 (por ruido, reinicio, encendido, etc.) vaya a un valor que sí esté dentro de la secuencia pseudoaleatoria de números y pueda así seguir generando números dentro de dicha secuencia.
- El bloque "=0" es un bloque que emite un 1 si el valor del registro contador es 0 y un 0 en caso contrario.
Como se puede observar el comportamiento del generador de destellos para el firmamento nocturno es muy sencillo:
Si asumimos que el momento del arranque los registros están todos a cero, la salida del bloque "=0" será 1 por lo que se seleccionará la entrada T del multiplexor del contador y la entrada P del multiplexor del LFSR. Aunque el registro LFSR está a 0, la salida del bloque X será "0000000001" por lo que la salida de P será el siguiente valor de la secuencia maximal de P después del valor "0000000001". En el momento que llega el siguiente flanco de subida del reloj se carga el registro LFSR con el nuevo valor de la secuencia pseudoaleatoria y se carga el registro contador con el valor T (50000000).
A partir de ahora, como el registro contador contiene un valor diferente de 0, la salida del bloque "=0" será un 0 por lo que el multiplexor del registro LFSR mantendrá el valor actual del registro LFSR y el multiplexor del contador seleccionará la entrada que proviene del sumador. Esta condición se mantendrá durante el tiempo que el contador sea mayor que cero (para T = 50000000 a 50 MHz, tenemos un segundo de tiempo) y en el momento que el contador llegue a cero, el bloque combinacional "=0" emitirá de nuevo un uno y el proceso se reanudará de nuevo (carga del LFSR con el siguiente valor de la secuencia pseudoaleatoria y carga del contador con el valor T).
Si sacamos hacia fuera 5 de los 10 bits del registro LFSR (no tienen por qué ser consecutivos) obtendremos un razonable efecto de "cielo estrellado aleatorio" que cambia cada segundo. Ahora podemos colocar todo el montaje en la parte trasera del disco de cartón dejando que se asomen hacia adelante sólo los leds y poniendo en la cara no visible la plaquita con el CLPD y la pila de botón.
Todo el código VHDL está disponible en la sección soft.
A continuación puede verse una foto de todo el conjunto pintado y montado simulando el cielo nocturno:

Y simulando el clieno diurno ("amaneciendo"):

¡Feliz Navidad a todos! :-)
[ añadir comentario ] ( 4251 visualizaciones ) | [ 0 trackbacks ] | enlace permanente
Tweet | |
( 3 / 3785 )A lo largo de este post se abordará el diseño y la implementación en VHDL de una interfaz de salida VGA para FPGA. La interfaz lee una imagen de 64x48 pixels de una memoria (por ahora una ROM) interna y la renderiza usando el modo VGA estándar de 640x480 a 60Hz.
Señal VGA
Las señales más importantes que viajan por un cable VGA son:
- R (nivel de rojo, mínimo 0 voltios, máximo 0.7 voltios)
- G (nivel de verde, mínimo 0 voltios, máximo 0.7 voltios)
- B (nivel de azul, mínimo 0 voltios, máximo 0.7 voltios)
- Sincronismo horizontal (HSync, señal digital TTL que puede ser de 3.3 voltios)
- Sincronismo vertical (VSync, señal digital TTL que puede ser de 3.3 voltios)
Un flanco de bajada en HSync determina el fin de una línea horizontal de imagen y un flanco de bajada en VSync determina el fin de un fotograma, o de un cuadro). Hay unos "márgenes de seguridad" antes y después (front y back porch) de cada flanco de bajada de HSync de la misma forma que hay unos "márgenes de seguridad" (en forma de líneas en negro) antes y después (front y back porch) de cada flanco de bajada de VSync.
A continuación puede verse un diagrama de tiempos sobre cómo funcionan las señales de color y de sincronismo en un cable VGA:
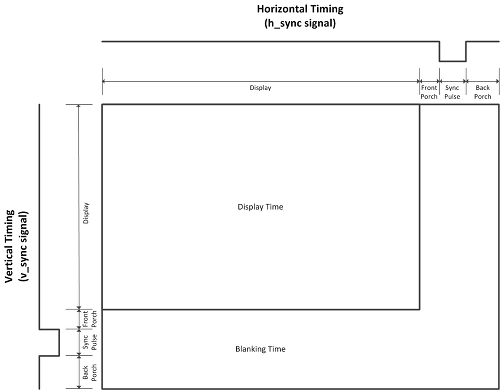
(imagen copyright © 2017 Scott Larson, extraida de este artículo)
Si asumimos una resolución VGA estándar de 640 x 480 pixels a 60 Hz, tendremos los siguientes valores:
| Pixel clock | Anchura (pixels) | Altura (líneas) | ||||||
| Visibles | No visibles | Visibles | No visibles | |||||
| Front porch | HSync | Back porch | Front porch | HSync | Back porch | |||
| 25.175 MHz | 640 | 16 | 96 | 48 | 480 | 10 | 2 | 33 |
Con estos valores vemos que, en efecto tenemos una tasa de refresco de:
$${1 \over {{{640+16+96+48} \over {25175000}} \times {\left(480+10+2+33\right)}}}=59.940\ Hz \approx 60\ Hz$$
Como los valores RGB son analógicos (entre 0 y 0.7 voltios), será necesario implementar un DAC (aunque sea de forma rudimentaria) por cada componente de color. Asumiremos una imagen de 8 colores con un bit por cada componente:
| 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| negro | azul | verde | cyan | rojo | rosa | amarillo | blanco |
De esta forma tendremos un DAC de 1 bit por cada color. Si la impedancia de entrada de las entradas RGB es de 75 Ohm vemos que con una sencilla resistencia de 270 Ohm en serie construimos un divisor de tensión que genera 0 voltios con un valor lógico 0 (0 voltios de salida digital) y 0.7 voltios con un valor lógico 1 (3.3 voltios de salida digital):
$${0 \times {75 \over {270+75}}}=0\ voltios$$
$${3.3 \times {75 \over {270+75}}}=0.71739\ voltios$$
Por cada píxel hay que almacenar 3 bits pero como las anchuras de bus de 3 bits son raras asumimos que cada pixel ocupa un byte del cual (por ahora) sólo se usan los 3 bits menos significativos.
Como el reloj de nuestra FPGA va a 50 MHz y el pixel clock es de 25.175 MHz se ha optado por asumir una imagen de 64 x 48 pixels. Esto es: cada pixel de la imagen en la memoria se corresponde con un cuadrado de 10 x 10 pixels en la pantalla. Usando esta aproximación, una imagen de 64 x 48 pixels necesita 64 x 48 = 3072 bytes de almacenamiento y el pixel clock se reduce de 25.175 MHz a 2.5175 MHz, que es una frecuencia más fácil de manejar por la FPGA.
Tenemos, por tanto, una memoria de 64 x 48 = 3072 bytes en la que cada byte posee los valores RGB en sus tres bits menos significativos. En cada línea de imagen se deben pintar 64 pixels (con un pixel clock de 2.5175 MHz en lugar de 25.175 MHz para que cada pixel de la memoria ocupe 10 pixels VGA de ancho) y cada línea debe ser pintada 10 veces de idéntica manera.
Ruta de datos y máquina de estados
A continuación puede verse una propuesta de ruta de datos a implementar para la interfaz VGA:
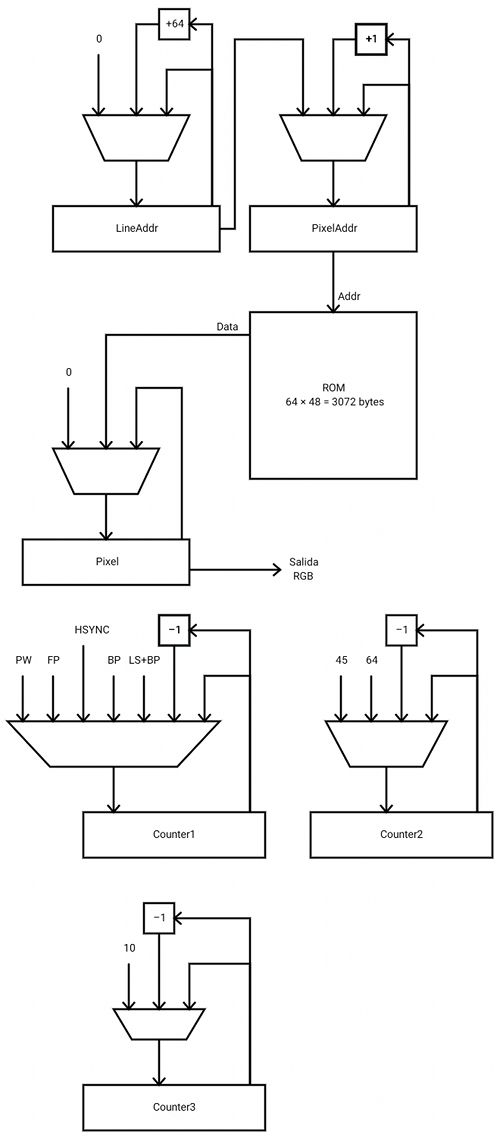
Leyenda:
PW = Pixel width
FP = Front porch (tiempo "en negro" antes del pulso HSync)
BP = Back porch (tiempo "en negro" después del puslto HSync)
LS = Line size, anchura total en pulsos de una línea en blanco de 640 pixels
El registro LineAddr almacena la dirección de comienzo de la línea actual. Es un registro que se incrementa de 64 en 64 y que ayuda a hacer el repetido de líneas (cada una de las 48 líneas de la imagen debe ser repetida 10 veces para renderizar las 480 líneas VGA).
El registro PixelAddr almacena la dirección de memoria del píxel actual que está siendo pintado. Este registro se inicializa siempre con el valor del registro LineAddr y es incrementado de uno en uno, 64 veces por cada línea (64 * 10 pixels = 640 pixels de anchura de la señal VGA).
El registro Pixel almacena el byte de cuyos tres bits más bajos se sacan las señales RGB de forma directa. Está gobernado por un multiplexor que decide si carga datos de la memoria o de la constante 0. Nótese que durante los márgenes de seguridad (front y back porch), durante los intervalos de sincronismo (tanto vertical como horizontal) y durante las lineas de retrazo (las que no se ven, de la 480 a la 524, 45 en total) debe emitirse una señal en negro por los pines RGB.
Se han habilitado además 3 contadores de propósito general que son utilizados por la máquina de estados para controlar los tiempos de cada fase de la señal VGA. La máquina de estados puede verse a continuación:
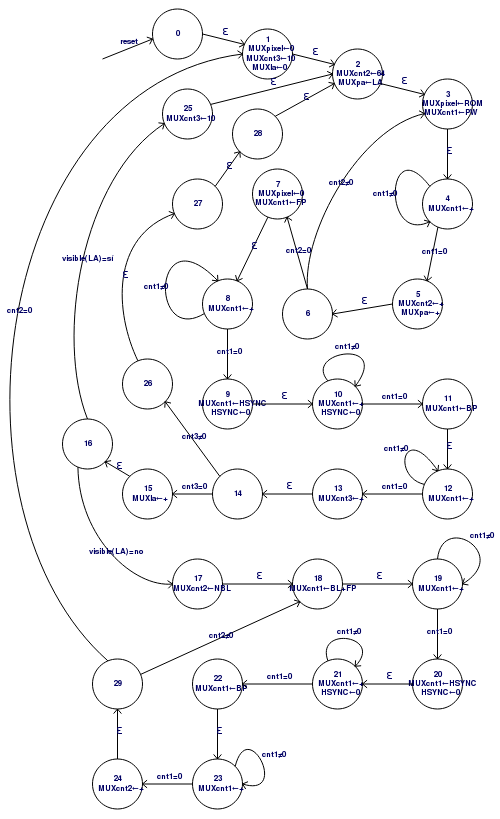
Los diferentes valores que se aplican a los contadores para controlar los tiempos del protocolo VGA se calculan teniendo en cuenta la frecuencia de reloj usada (50 MHz) y la frecuencia de pixel VGA (25.175 MHz). Por ejemplo el valor de PW (PIXEL_WIDTH) se usa para esperar un tiempo equivalente a 10 pixels:
$$PW={{1 \over 25175000} \times 50000000 \times 10}=20\ pulsos$$
De la misma forma se calcula el resto de valores:
$$FP={{1 \over 25175000} \times 50000000 \times 16}=32\ pulsos$$
$$HSYNC={{1 \over 25175000} \times 50000000 \times 96}=191\ pulsos$$
$$BP={{1 \over 25175000} \times 50000000 \times 48}=95\ pulsos$$
$$LS+BP={{1 \over 25175000} \times 50000000 \times \left(640+16\right)}=1303\ pulsos$$
Estos valores teóricos son luego ajustados ya que en esas ecuaciones sólo se tienen en cuenta los estados de espera y no se contabiliza el resto de estados, que también consumen ciclos de reloj.
Una técnica muy usada para compensar los tiempos de espera en las máquinas de estado es incluir estados que no hacen nada con transiciones vacías (épsilon). Como se puede ver en la imagen anterior, el estado 14 se alcanza siempre al final del renderizado de una línea horizontal VGA. Si Contador3 = 0 entonces se ha terminado una repetición de 10 líneas consecutivas y toca avanzar de línea, pero si Contador3 <> 0 entonces hay que volver a pintar la línea actual (la que está apuntada por el registro LA, LineAddress). En este último caso, la máquina de estados pasa por tres estados que no hacen nada (26, 27 y 28) pero que se han colocado ahí para que no haya diferencia entre la cantidad de ciclos que tarda una línea repetida y la cantidad de ciclos que tarda una línea nueva.
Buffers de salida para los sincronismos
Aunque la máquina de estados ya genera directamente las señales HSync y VSync, es necesario hacerlas pasar por un latch (biestable D) para garantizar que quedan libres de gitches.
-- acondicionador de señales HSync y VSync process (Clk) begin if (Clk'event and (Clk = '1')) then HSyncQBus <= HSyncDBus; end if; end process; HSyncDBus <= HSyncIn; HSyncOut <= HSyncQBus; process (Clk) begin if (Clk'event and (Clk = '1')) then VSyncQBus <= VSyncDBus; end if; end process; VSyncDBus <= VSyncIn; VSyncOut <= VSyncQBus;
Si no se colocasen estos latches y se cableasen directamente las salidas HSync y VSync a los pines de la PFGA podría ocurrir que transiciones intermedias espúreas entre estados generasen pulsos "fantasma" en dichas salidas. Haciendo pasar a estas señales por un latch se garantiza una carga atrasada y limpia que disminuye la probabilidad de que se produzcan estos glitches.
Por claridad, estos latches no se muestran en el diagrama con la ruta de datos mostrado anteriormente.
Código fuente e implementación
La máquina de estados se ha implementado, como otras veces, siguiendo el modelo estándar de máquina de Moore:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity FSM is port ( Clk : in std_logic; Reset : in std_logic; Counter1IsZero : in std_logic; Counter2IsZero : in std_logic; Counter3IsZero : in std_logic; LineAddrIsVisible : in std_logic; Counter2IsVSync : in std_logic; Counter1Mux : out std_logic_vector(2 downto 0); Counter2Mux : out std_logic_vector(1 downto 0); Counter3Mux : out std_logic_vector(1 downto 0); LineAddrMux : out std_logic_vector(1 downto 0); PixelAddrMux : out std_logic_vector(1 downto 0); PixelMux : out std_logic_vector(1 downto 0); HSync : out std_logic; VSync : out std_logic ); end entity; architecture A of FSM is signal DBus : std_logic_vector(4 downto 0); signal QBus : std_logic_vector(4 downto 0); begin -- lógica de estado siguiente DBus <= "00000" when (Reset = '1') else "00001" when ((QBus = "00000") or ((QBus = "11101") and (Counter2IsZero = '1'))) else "00010" when ((QBus = "00001") or (QBus = "11100") or (QBus = "11001")) else "00011" when ((QBus = "00010") or ((QBus = "00110") and (Counter2IsZero = '0'))) else "00100" when ((QBus = "00011") or ((QBus = "00100") and (Counter1IsZero = '0'))) else "00101" when ((QBus = "00100") and (Counter1IsZero = '1')) else "00110" when (QBus = "00101") else "00111" when ((QBus = "00110") and (Counter2IsZero = '1')) else "01000" when ((QBus = "00111") or ((QBus = "01000") and (Counter1IsZero = '0'))) else "01001" when ((QBus = "01000") and (Counter1IsZero = '1')) else "01010" when ((QBus = "01001") or ((QBus = "01010") and (Counter1IsZero = '0'))) else "01011" when ((QBus = "01010") and (Counter1IsZero = '1')) else "01100" when ((QBus = "01011") or ((QBus = "01100") and (Counter1IsZero = '0'))) else "01101" when ((QBus = "01100") and (Counter1IsZero = '1')) else "01110" when (QBus = "01101") else "01111" when ((QBus = "01110") and (Counter3IsZero = '1')) else "10000" when (QBus = "01111") else "10001" when ((QBus = "10000") and (LineAddrIsVisible = '0')) else "10010" when ((QBus = "10001") or ((QBus = "11101") and (Counter2IsZero = '0'))) else "10011" when ((QBus = "10010") or ((QBus = "10011") and (Counter1IsZero = '0'))) else "10100" when ((QBus = "10011") and (Counter1IsZero = '1')) else "10101" when ((QBus = "10100") or ((QBus = "10101") and (Counter1IsZero = '0'))) else "10110" when ((QBus = "10101") and (Counter1IsZero = '1')) else "10111" when ((QBus = "10110") or ((QBus = "10111") and (Counter1IsZero = '0'))) else "11000" when ((QBus = "10111") and (Counter1IsZero = '1')) else "11001" when ((QBus = "10000") and (LineAddrIsVisible = '1')) else "11010" when ((QBus = "01110") and (Counter3IsZero = '0')) else "11011" when (QBus = "11010") else "11100" when (QBus = "11011") else "11101" when (QBus = "11000") else "00000"; -- lógica de salida Counter1Mux <= "001" when (QBus = "00011") else -- cargar anchura de pixel "010" when (QBus = "00111") else -- cargar front porch "011" when ((QBus = "01001") or (QBus = "10100")) else -- cargar HSYNC "100" when ((QBus = "01011") or (QBus = "10110")) else -- cargar back porch "101" when (QBus = "10010") else -- cargar anchura línea + front porch "110" when ((QBus = "00100") or (QBus = "01000") or (QBus = "01010") or (QBus = "01100") or (QBus = "10011") or (QBus = "10101") or (QBus = "10111")) else -- decrementar "000"; Counter2Mux <= "01" when (QBus = "00010") else -- cargar 64 (la anchura de línea) "10" when ((QBus = "00101") or (QBus = "11000")) else -- decrementar "11" when (QBus = "10001") else -- cargar 45 (cantidad de líneas de blanqueo) "00"; Counter3Mux <= "01" when ((QBus = "00001") or (QBus = "11001")) else -- cargar 10 (líneas a repetir) "10" when (QBus = "01101") else -- decrementar "00"; LineAddrMux <= "01" when (QBus = "00001") else -- cargar 0 "10" when (QBus = "01111") else -- incrementar en 64 "00"; PixelAddrMux <= "01" when (QBus = "00010") else "10" when (QBus = "00101") else "00"; PixelMux <= "01" when ((QBus = "00001") or (QBus = "00111")) else -- cargar 0 "10" when (QBus = "00011") else -- cargar dato de la ROM "00"; HSync <= '0' when ((QBus = "01001") or (QBus = "01010") or (QBus = "10100") or (QBus = "10101")) else '1'; VSync <= '0' when (((QBus = "10010") or (QBus = "10011") or (QBus = "10100") or (QBus = "10101") or (QBus = "10110") or (QBus = "10111") or (QBus = "11000") or (QBus = "11101")) and (Counter2IsVSync = '1')) else '1'; -- biestables process (Clk) begin if (Clk'event and (Clk = '1')) then QBus <= DBus; end if; end process; end architecture;
El resto de la implementación consiste en codificar lo registros y los multiplexores:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity AllButFSM is port ( Clk : in std_logic; LineAddrMux : in std_logic_vector(1 downto 0); PixelAddrMux : in std_logic_vector(1 downto 0); PixelMux : in std_logic_vector(1 downto 0); PixelValue : out std_logic_vector(7 downto 0); HSyncIn : in std_logic; HSyncOut : out std_logic; VSyncIn : in std_logic; VSyncOut : out std_logic; Counter1Mux : in std_logic_vector(2 downto 0); Counter1IsZero : out std_logic; Counter2Mux : in std_logic_vector(1 downto 0); Counter2IsZero : out std_logic; Counter2IsVSync : out std_logic; Counter3Mux : in std_logic_vector(1 downto 0); Counter3IsZero : out std_logic; LineAddrIsVisible : out std_logic ); end entity; architecture A of AllButFSM is component Rom is generic ( Log2NumRows : integer := 12 -- 4096 bytes ); port ( AddressIn : in std_logic_vector((Log2NumRows - 1) downto 0); DataOut : out std_logic_vector(7 downto 0) ); end component; component Counter1 is port ( Clk : in std_logic; Mux : in std_logic_vector(2 downto 0); IsZero : out std_logic ); end component; component Counter2 is port ( Clk : in std_logic; Mux : in std_logic_vector(1 downto 0); IsZero : out std_logic; IsVSync : out std_logic ); end component; component Counter3 is port ( Clk : in std_logic; Mux : in std_logic_vector(1 downto 0); IsZero : out std_logic ); end component; signal LineAddrDBus : std_logic_vector(11 downto 0); -- 12 bits = 4096 bytes (sólo se usan los 64 * 48 = 3072 primeros bytes) signal LineAddrQBus : std_logic_vector(11 downto 0); signal PixelAddrDBus : std_logic_vector(11 downto 0); signal PixelAddrQBus : std_logic_vector(11 downto 0); signal RomOut : std_logic_vector(7 downto 0); signal PixelDBus : std_logic_vector(7 downto 0); signal PixelQBus : std_logic_vector(7 downto 0); signal HSyncDBus : std_logic; signal HSyncQBus : std_logic; signal VSyncDBus : std_logic; signal VSyncQBus : std_logic; constant FIRST_NO_VISIBLE_LINE_ADDRESS : integer := 3072; -- Dirección de memoria de la primera línea no visible begin -- dirección de inicio de la línea actual de pantalla process (Clk) begin if (Clk'event and (Clk = '1')) then LineAddrQBus <= LineAddrDBus; end if; end process; LineAddrDBus <= std_logic_vector(to_signed(0, 12)) when (LineAddrMux = "01") else std_logic_vector(to_signed(to_integer(signed(LineAddrQBus)) + 64, 12)) when (LineAddrMux = "10") else -- 64 bytes (pixels) por línea LineAddrQBus; LineAddrIsVisible <= '0' when (to_integer(unsigned(LineAddrQBus)) = FIRST_NO_VISIBLE_LINE_ADDRESS) else '1'; -- dirección del actual pixel process (Clk) begin if (Clk'event and (Clk = '1')) then PixelAddrQBus <= PixelAddrDBus; end if; end process; PixelAddrDBus <= LineAddrQBus when (PixelAddrMux = "01") else std_logic_vector(to_signed(to_integer(signed(PixelAddrQBus)) + 1, 12)) when (PixelAddrMux = "10") else -- 1 byte = 1 pixel PixelAddrQBus; -- ROM con la imagen de 64 x 48 pixels (1 byte por pixel, 64 * 48 = 3072 bytes) R : Rom generic map ( Log2NumRows => 12 ) port map ( AddressIn => PixelAddrQBus, DataOut => RomOut ); -- buffer de salida de la ROM (pixel actual) process (Clk) begin if (Clk'event and (Clk = '1')) then PixelQBus <= PixelDBus; end if; end process; PixelDBus <= RomOut when (PixelMux = "10") else std_logic_vector(to_signed(0, 8)) when (PixelMux = "01") else PixelQBus; PixelValue <= PixelQBus; -- contadores C1 : Counter1 port map ( Clk => Clk, Mux => Counter1Mux, IsZero => Counter1IsZero ); C2 : Counter2 port map ( Clk => Clk, Mux => Counter2Mux, IsZero => Counter2IsZero, IsVSync => Counter2IsVSync ); C3 : Counter3 port map ( Clk => Clk, Mux => Counter3Mux, IsZero => Counter3IsZero ); -- acondicionador de señales HSync y VSync process (Clk) begin if (Clk'event and (Clk = '1')) then HSyncQBus <= HSyncDBus; end if; end process; HSyncDBus <= HSyncIn; HSyncOut <= HSyncQBus; process (Clk) begin if (Clk'event and (Clk = '1')) then VSyncQBus <= VSyncDBus; end if; end process; VSyncDBus <= VSyncIn; VSyncOut <= VSyncQBus; end architecture;
La imagen se aloja en una ROM cuyos datos se especifican directamente en el código fuente de Rom.vhd. Para generar la imagen en formato VHDL usando el GIMP se hicieron los siguientes pasos:
- Se creó una nueva imagen de 64 x 48 pixels.
- Menú Ventanas -- Diálogos empotrables -- Paletas -- Botón derecho dentro del listado de paletas -- Importar paleta -- En "Seleccionar origen" se marcó "Archivo de la paleta" y se seleccionó el fichero "vga_fpga.gpl" que se ha incluido dentro del proyecto. Esto creó dentro del GIMP una nueva paleta de 8 colores que se correspondía con los 8 colores que genera nuestra FPGA.
- Se trabajó la imagen de 64x48 con esa paleta.
- Cuando se terminó de trabajar con la imagen, menú Imagen -- Modo -- Indexado -- En "Mapa de colores" se marcó la opción "Usar paleta personal", se seleccionó la paleta acabante de crear a partir del fichero "vga_fpga.gpl", se desmarcó la opción "Eliminar los colores sin usar de la paleta final" y "Aceptar".
- Menú Archivo -- Exportar como -- Se seleccionó como tipo de archivo "Cabecera de código fuente en C (.h)" -- Exportar
Esto creó un fichero .h con un array con el mapa de color (la paleta) y otro array de 3072 bytes con la imagen completa. Afortunadamente el formato de datos de array de C y VHDL es relativamente similar por lo que simplemente hubo que trabajar un poco con el comando "sed" para adaptar los datos. Por ejemplo, un bloque de texto de esta forma:
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,7,
7,0,0,0,0,0,0,0,0,0,0,0,0,0,3,3,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,7,
7,0,0,0,0,0,0,0,0,0,0,0,0,3,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,3,3,3,
3,0,0,3,3,3,0,0,0,0,3,3,3,0,0,0,
Puede convertirse a formato de datos VHDL de esta forma:
$ cat datos.txt | sed -e 's/0/x"00"/g' | sed -e 's/1/x"01"/g' | sed -e 's/2/x"02"/g' | sed -e 's/3/x"03"/g' | sed -e 's/4/x"04"/g' | sed -e 's/5/x"05"/g' | sed -e 's/6/x"06"/g' | sed -e 's/7/x"07"/g'
Generando la salida:
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"07",
x"07",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"03",x"03",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"07",
x"07",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"03",x"00",x"00",
x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"00",x"03",x"03",x"03",
x"03",x"00",x"00",x"03",x"03",x"03",x"00",x"00",x"00",x"00",x"03",x"03",x"03",x"00",x"00",x"00",
Que es fácilmente incluible en un fichero VHDL como un array (ver Rom.vhd).
Circuito
El circuito externo a la FPGA sólo requiere las líneas de reset, de reloj y de sincronismo conectadas directamente y cada una de las tres líneas de componentes de color (RGB) conectada con una resistencia en serie de 270 Ohm.
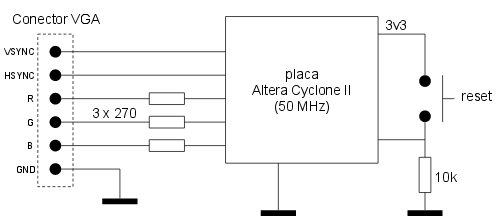
El resultado:


Como siempre, todo el código fuente está disponible en la sección soft.
[ añadir comentario ] ( 1670 visualizaciones ) | [ 0 trackbacks ] | enlace permanente
Tweet | |
( 3 / 3535 )Incluir una entrada analógica en una FPGA pasa, normalmente, por agregar al menos un integrado que haga de ADC. Sin embargo, existen alternativas al ADC tradicional que, aprovechando las características de una FPGA, nos permiten implementar un conversor analógico-digital utilizando muy pocos componentes externos.
Registro de aproximaciones sucesivas (SAR)
Esta técnica utiliza un comparador, una resistencia y un condensador como únicos componentes externos y consume dos pines E/S de la FPGA. Se consigue una resolución en bits arbitraria que sólo dependerá de los valores de R, de C y de la frecuencia de reloj de la FPGA.
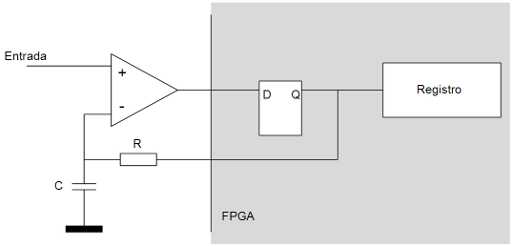
El principio de funcionamiento es muy sencillo: inicialmente el condensador se encuentra descargado y la salida de realimentación (el pin conectado a R) se pone a 1. Esto hace que el condensador empiece a cargarse. En el instante en que el voltaje en el condensador llegue hasta la mitad de Vcc (1.65v en el caso de una FPGA alimentada a 3.3v), la FPGA lee el valor de la entrada digital (el otro pin). Esta entrada está conectada a la salida de un comparador que emitirá 3.3v si el voltaje en la entrada V+ es superior al voltaje en la entrada V- y 0v en caso contrario.
Si la FPGA lee un 0 en esa entrada significará que el voltaje que estamos midiendo en la entrada V+ se encuentra por debajo de Vcc/2 por lo que ya podemos determinar que el bit más significativo del valor convertido es un 0. Si la FGPA lee un 1 en esa entrada significará que el voltaje que estamos midiendo en la entrada V+ se encuentra por encima de Vcc/2 por lo que ya podemos determinar que el bit más significativo del valor convertido es en este caso un 1.
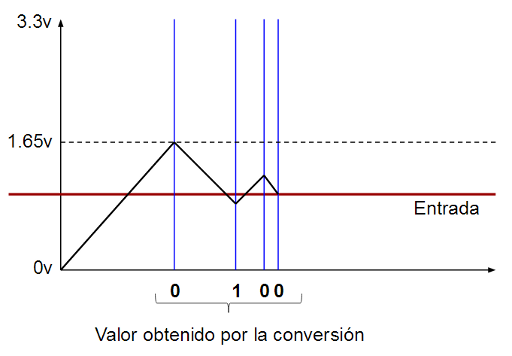
Si la FPGA ha leido un 0 en la entrada de comparación (V+ está por debajo del voltaje que hay en ese instante en los extremos del condensador, Vcc/2), significará que para determinar el siguiente bit hay que bajar el voltaje de la entrada V- (descargar el condensador), por lo que se emite un 0 por el pin conectado a R. Esto provoca que el condensador empiece a descargarse.
Si la FPGA leyó un 1 en la primera comparación (V+ está por encima del voltaje que hay en ese instante en los extremos del condensador, Vcc/2), significará que para determinar el siguiente bit hay que seguir cargando el condensador (la FPGA debe seguir emitiendo un 1 por la pata que conecta a R).
Independientemente de si la FPGA emite un 0 (para descargar el condensador) o un 1 (para seguir cargándolo), espera la mitad de tiempo que la primera vez antes de volver a leer la entrada conectada al comparador. En esta segunda lectura vuelve a hacer lo mismo: Si vale 0 significa que el voltaje del condensador está por encima del voltaje que estamos midiendo (V+) mientras que si vale 1 significa que el voltaje del condensador está por debajo del voltaje que estamos midiendo. En el primer caso el siguiente bit valdrá 0 y se emite un 0 por el pin conectado a R para descargar del condensador. En el segundo caso el siguiente bit valdra 1 y se emitirá un 1 por el pin conectado a R para cargar el condensador. Como puede observar el bit que se emite como valor es el mismo que el que alimenta a la salida conectada a R.
En cada iteración del proceso se espera la mitad de tiempo que la iteración anterior, se empieza siempre por el bit más significativo y se pueden realizar tantas iteraciones como se deseen: La cantidad de bits de resolución de la conversión vendrá determinada por la cantidad de comparaciones que hagamos.
Implementación: el circuito
En este caso se ha implementado una pequeña prueba de concepto: un conversor de 4 bits de resolución usando un amplificador operacional barato LM358N (por AliExpress se pueden adquirir 10 unidades por menos de 2¤ en el momento que escribo estas líneas) para usarlo como comparador, un condensador de 1uF y una resistencia de 10K.
Como FPGA he utilizado una Cyclone II de Altera que pillé hace poco. No es tan potente como la Spartan-3E de Xilinx que he usado en otros montajes pero es compacta, barata y más que suficiente para el ADC.
Implementación: el software
Como se vió en la descripción varios párrafos más arriba, la FPGA debe leer la entrada de comparación en unos instantes determinados: inicialmente debe esperar hasta que el condensador llegue a Vcc/2 para realizar la primera medida, la segunda medida la realizará en la mitad de tiempo que la primera, la tercera en la mitad de tiempo que la segunda y así sucesivamente.
En nuestro caso, asumiendo un condensador de 1uF (C = 0.000001), una resistencia de 10K (R = 10000), la salida de la FPGA que está conectada a R, a la que etiquetaremos como Vi con un valor de 3.3v y la entrada inversora del comparador, a la que llamaremos Vo con un valor de 1.65v (3.3 / 2), tenemos que:
$$t=-R \times C \times log\left({{V_o - V_i} \over {V_o(0) - V_i}}\right)$$
$$t = -10000 \times 0.000001 \times log\left({{1.65 - 3.3} \over {0 - 3.3}}\right) = 0.006931471805599453 \; s$$
Es el tiempo que tarda Vo en valer 1.65v (la mitad de Vcc = 3.3v) partiendo de 0v (condensador totalmente descargado). Esta ecuación es la solución analítica a la ecuación diferencial de la carga de un circuito RC que vimos en este post anterior.
Si asumimos una frecuencia de reloj de 50MHz tenemos que hacen falta:
$$50000000 * 0.006931471805599453 = 346574 \; ciclos$$
Para esperar desde que el condensador está totalmente descargado hasta que Vo = 1.65v. Como se va a hacer una conversión de 4 bits los puntos de comparación se deberán hacer en los siguientes instantes:
1ª comparación (bit 3): 346574 ciclos de reloj
↓
346574 / 2
↓
2ª comparación (bit 2): 173286 ciclos de reloj (instante 519860)
↓
173286 / 2
↓
3ª comparación (bit 1): 86643 ciclos de reloj (instante 606503)
↓
86643 / 2
↓
4ª comparación (bit 0): 43321 ciclos de reloj (instante 649824)Tras hacer la 4ª comparación es necesario realizar una descarga completa del condensador para iniciar la siguiente conversión. Si asumimos el peor de los casos, que el condensador esté totalmente cargado (Vo(0) = 3.3v), tenemos que para llegar a Vo = 0.01v con Vi = 0 se necesitan:
$$-10000 \times 0.000001 \times log\left({{0.01 - 0} \over {3.3 - 0}}\right) = 0.057990926544605255 \; segundos$$
Que equivalen a:
$$50000000 \times 0.057990926544605255 = 2899546 \; ciclos$$
Desde un punto de vista teórico el condensador nunca se descarga del todo (siempre tiene carga residual). Si se pusiese 0 en lugar 0.01 en la ecuación anterior el tiempo tendería a infinito, por lo que hay que poner una cantidad muy baja que no sea cero. De forma global se ve que cada conversión requiere:
649824 ciclos para la conversión en sí + 2899546 ciclos para descargar el condensador del todo antes de iniciar una nueva conversión = 3549370 ciclos
Para contar 3549370 ciclos (desde 0 hasta 3549369) hacen falta como mínimo 22 bits ($2^{21} = 2097152$, se queda corto, y $2^{22} = 4194304$). Por tanto el "motor" de nuestro conversor analógico-digital de 4 bits será un contador de 22 bits que emitirá las siguientes señales de control:
0 --> forzar biestable de comparación = 1
346574 --> cargar el biestable con el 1º valor de comparación
346575 --> empujar valor biestable en registro de desplazamiento (bit 3)
519860 --> cargar el biestable con el 2º valor de comparación
519861 --> empujar valor biestable en registro de desplazamiento (bit 2)
606503 --> cargar el biestable con el 3º valor de comparación
606504 --> empujar valor biestable en registro de desplazamiento (bit 1)
649824 --> cargar el biestable con el 4º valor de comparación
649825 --> empujar valor biestable en registro de desplazamiento (bit 0)
forzar biestable de comparación = 1
649826 --> cargar registro de salida desde registro de desplazamientoEl proceso de descarga se realizará entre el ciclo 649825 y el 4194303 ($2^{22} - 1$). No se va a reiniciar el contador en el ciclo 3549370 para evitar sobrecargar con más puertas lógicas el diseño, sino que se va a dejar que el contador se desborde de forma natural en el ciclo 4194304 ($2^{22}$). Se pierde una centésima de segundo en resolución temporal pero para el caso que nos ocupa no es relevante. Aprovechar el mismo registro contador de tiempo como máquina de estados simplifica enormemente el diseño.
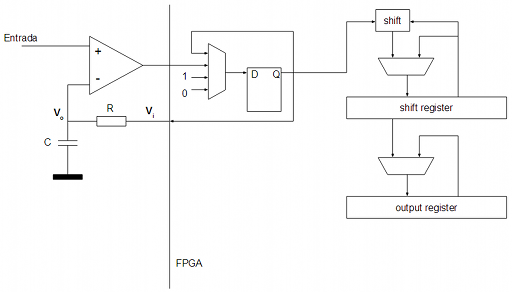
La implementación en VHDL partiendo de este diagrama es muy sencilla:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity ADC is port ( Clock : in std_logic; Reset : in std_logic; CompIn : in std_logic; ChargeOut : out std_logic; DataOut : out std_logic_vector(3 downto 0) ); end entity; architecture A of ADC is signal DComp : std_logic; signal QComp : std_logic; signal CompSel : std_logic_vector(1 downto 0); signal DCounter : std_logic_vector(21 downto 0); signal QCounter : std_logic_vector(21 downto 0); signal DShiftReg : std_logic_vector(3 downto 0); signal QShiftReg : std_logic_vector(3 downto 0); signal ShiftRegEnable : std_logic; signal DOutReg : std_logic_vector(3 downto 0); signal QOutReg : std_logic_vector(3 downto 0); signal OutRegEnable : std_logic; constant Conversion1Cycle : integer := 346574; constant Conversion2Cycle : integer := 519860; constant Conversion3Cycle : integer := 606503; constant Conversion4Cycle : integer := 649824; begin -- comparator d flip-flop process (Clock) begin if (Clock'event and (Clock = '1')) then QComp <= DComp; end if; end process; DComp <= '0' when ((CompSel = "00") or (Reset = '1')) else '1' when (CompSel = "01") else CompIn when (CompSel = "10") else QComp; ChargeOut <= QComp; -- shift register process (Clock) begin if (Clock'event and (Clock = '1')) then QShiftReg <= DShiftReg; end if; end process; DShiftReg <= (QShiftReg(2 downto 0) & QComp) when (ShiftRegEnable = '1') else QShiftReg; -- output register process (Clock) begin if (Clock'event and (Clock = '1')) then QOutReg <= DOutReg; end if; end process; DOutReg <= QShiftReg when (OutRegEnable = '1') else QOutReg; DataOut <= QOutReg; -- 22 bit counter & fsm process (Clock) begin if (Clock'event and (Clock = '1')) then QCounter <= DCounter; end if; end process; DCounter <= std_logic_vector(to_unsigned(0, 22)) when (Reset = '1') else std_logic_vector(to_unsigned(to_integer(unsigned(QCounter)) + 1, 22)); CompSel <= "00" when (to_integer(unsigned(QCounter)) = (Conversion4Cycle + 1)) else "01" when (to_integer(unsigned(QCounter)) = 0) else "10" when ((to_integer(unsigned(QCounter)) = Conversion1Cycle) or (to_integer(unsigned(QCounter)) = Conversion2Cycle) or (to_integer(unsigned(QCounter)) = Conversion3Cycle) or (to_integer(unsigned(QCounter)) = Conversion4Cycle)) else "11"; ShiftRegEnable <= '1' when ((to_integer(unsigned(QCounter)) = (Conversion1Cycle + 1)) or (to_integer(unsigned(QCounter)) = (Conversion2Cycle + 1)) or (to_integer(unsigned(QCounter)) = (Conversion3Cycle + 1)) or (to_integer(unsigned(QCounter)) = (Conversion4Cycle + 1))) else '0'; OutRegEnable <= '1' when (to_integer(unsigned(QCounter)) = (Conversion4Cycle + 2)) else '0'; end architecture;
Conclusión
Usar un registro de aproximaciones sucesivas (SAR) es la forma más sencilla y barata de implementar un ADC, aunque tiene sus inconvenientes:
- Las conversiones son lentas. Aunque pongamos condensadores y resistencias pequeños, es complicado aumentar la frecuencia de muestreo por encima de unos pocos KHz.
- La pendiente de carga de un condensador en un circuito típico RC no es lineal por lo que la conversión resultante tampoco será lineal. Este escollo puede superarse con un circuito externo más elaborado que garantice una corriente de carga constante en el condensador y, por tanto, una pendiente de carga constante en el mismo.
También tiene sus ventajas :-):
- Usa relativamente pocos recursos de la FPGA.
Muy pocos componentes externos. El comparador podría implementarse incluso utilizando las entradas diferenciales que todas las FPGAs tienen (LVDS, mini-LVDS, etc.).
- La resolución en bits es arbitraria y sólo depende de la implementación interna en la FPGA.
A continuación puede verse un vídeo con el conversor implementado al que se le han conectado cuatro leds:
Todo el código puede descargarse de la sección soft.
[ añadir comentario ] ( 1356 visualizaciones ) | [ 0 trackbacks ] | enlace permanente
Tweet | |
( 3 / 4843 )Transmitir una señal modulada en FM dentro de la banda de frecuencias de la FM comercial utilizando FPGAs es un tópico ampliamente cubierto en decenas de webs y vídeos online pero que en pocos casos es desgranado y explicado de forma entendible y rigurosa. A lo largo de este post se desarrollará tanto la base teórica como una prueba de concepto de un transmisor FM basado en FPGA.
Los fundamentos
La modulación FM consiste en hacer variar la frecuencia de la señal que estamos mandando a la antena en función de la amplitud de la señal moduladora (sonido, por ejemplo). El rango de frecuencias reservado para emisoras comerciales de audio abarca desde los 87.5 MHz hasta los 108 MHz (es el rango que recoge cualquier receptor FM analógico) con una profundidad de modulación de +- 75 KHz. Esto significa que si queremos emitir en la frecuencia de 100 MHz debemos hacer variar la frecuencia entre 99.925 MHz y 100.075 MHz en función de la amplitud de la señal moduladora.
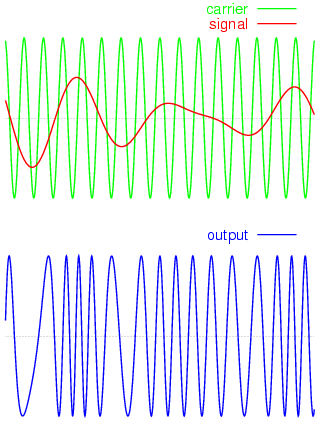
(imagen extraida de Wikipedia, con licencia Creative Commons Attribution - Share Alike 2.0, autor Gvf)
Generar la señal en el dominio digital
Intentar hacer un transmisor FM utilizando una FPGA nos hace chocar, a priori, con un primer impedimento: Poder generar una señal que varíe de frecuencia de una forma tan ligera. Hay que tener en cuenta que con una anchura de modulación de 150 KHz (75 KHz + 75 KHz) y asumiendo una señal sonora muestreada a 16 bits tenemos que la variación de la señal de salida de la antena debe de ser en pasos de:
$${150000 \over {2^{16}}} = {150000 \over 65536} = 2.2888 Hz$$
Esos son muy pocos hercios. En el dominio digital lo habitual para modificar la frecuencia de una señal es multiplicarla por una constante (mediante un PLL) o dividirla entre una constante (mediante un divisor de frecuencias). Los PLLs son circuitos híbridos (entre analógicos y digitales), no son todo lo rápido que nos gustaría (lo normal es que un PLL necesite varios ciclos hasta estabilizarse en la frecuencia deseada), normalmente trabajan con factores constantes (no variables como en nuestro caso) y no están siempre disponibles en las FPGAs para uso directo del usuario. Los divisores de frecuencia son más fáciles de hacer (no dejan de ser baterías de biestables) pero, como su propio nombre indica, sólo son capaces de dividir la frecuencia entre un valor entero.
Acumuladores de fase
Existe, sin embargo, una forma bastante ingeniosa para la síntesis directa de señales digitales sin necesidad del uso de PLLs ni de divisores de frecuencia: los acumuladores de fase. Un acumulador de fase es una de las partes que integran un oscilador digital basado en tabla de ondas. Imaginemos que queremos generar una onda senoidal mediante una tabla de ondas.
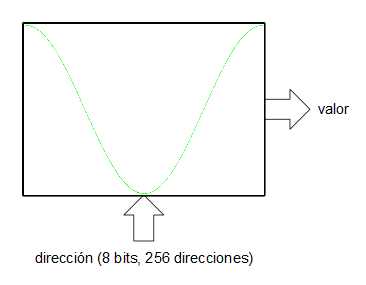
Asumiremos, por simplificar, que la tabla de la onda (realmente sería una ROM o una RAM) tiene un tamaño de 256 muestras ($2^8$). Por otro lado tenemos un registro (al que llamaremos acumulador de fase) de 16 bits y lo que hacemos es indexar la tabla de ondas utilizando los 8 bits más significativos del acumulador de fase. Las entradas D de los biestables de este registro se conectan a la salida un sumador que suma las salidas Q (el valor actual de registro) más un valor de entrada de 16 bits. En cada flanco de subida del reloj del sistema el registro (el acumulador de fase) se carga con el valor de las entradas D procedentes del sumador. En cada tick de reloj el acumulador va acumulando el valor de la entrada de 16 bits.
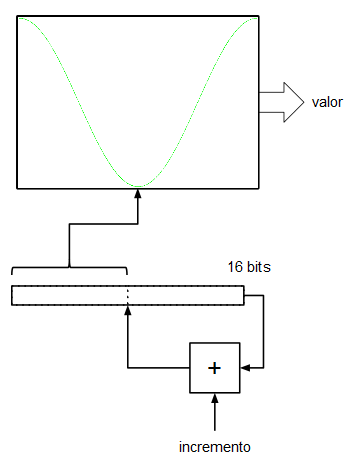
Si en la entrada de 16 bits ponemos un 0, el registro se quedará "quieto", no cambiará su valor y, por tanto la salida de datos de la ROM indexada por dicho registro sacará un valor constante (frecuencia de 0 Hz). Si en la entrada de 16 bits ponemos un 1, en registro se irá incrementando de 1 en 1, sin embargo, como lo que indexa a la tabla de valores son los 8 bits más significativos, este índice sólo avanzará cada 256 pulsos de reloj del sistema. Esto significa que con una frecuencia de reloj de 32 KHz, nuestro oscilador generaría una señal con una frecuencia de:
$${32000 \over 256} = 125 Hz$$
Yéndonos al otro extremo, si en la entrada de 16 bits metemos un valor de $2^{15} = 32768$, el acumulador de fase, al ser de 16 bits, se desbordará cada dos ciclos de reloj: el acumulador de fase generará la secuencia de valores 0, 32768, 0, 32768, 0, 32768, etc. que, a su vez, indexarán los valores mínimo y máximo de la onda senoidal que tenemos en la tabla. Esto significa que la salida del oscilador ha alcanzado su frecuencia máxima (su frecuencia de Nyquist, de 16 KHz).
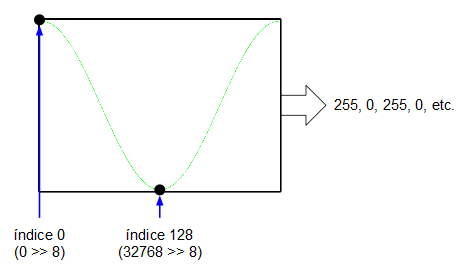
Como se puede comprobar, los incrementos en los pasos son lineales por lo que podemos establecer una especie de regla de tres para el cálculo de la frecuencia de salida de nuestro oscilador imaginario:
$$I_{acumulador fase} = {f_{deseada} \over 32000} \times 2^{16}$$
Vemos que si frecuencia_deseada = 0, entonces incremento_acumulador_fase = 0. Si frecuencia_deseada = 16000 (la frecuencia Nyquist, para 32 KHz), entonces:
$$I_{acumulador fase} = {16000 \over 32000} \times 2^{16} = {1 \over 2} \times 2^{16} = 2^{15} = 32768$$
Para 440 Hz (la nota LA de la cuarta octava del piano) tenemos que:
$$I_{acumulador fase} = {440 \over 32000} \times 2^{16} = 901.12$$
En estos casos, cuando el resultado es fraccionario, hay dos opciones: O quedarse con la parte entera (redondeando o truncando, incremento_acumulador_fase = 901), o, si no queremos perder precisión, incrementar el número de bits para reducir el error. Por ejemplo, utilizando un acumulador de fase de 59 bits conseguiríamos un valor de incremento entero (sin parte fraccionaria):
$$I_{acumulador fase} = {440 \over 32000} \times 2^{59} = 7926335344172073$$
De forma general se puede plantear la ecuación de la siguiente manera:
$$I_{acumulador fase} = {f_{deseada} \over f_{muestreo}} \times 2^{bits}$$
Nótese que la cantidad de bits que indexa la tabla de ondas no es relevante. Lo único importante es que la tabla de ondas está indexada por la parte alta del registro acumulador de fase. Como se puede apreciar, con este método es posible generar frecuencias arbitrarias con pasos relativamente pequeños y sólo limitados por el número de bits que utilicemos en el acumulador de fase.
El transmisor
Imaginemos que la frecuencia de muestreo es ahora de 320 MHz y que queremos generar una frecuencia de 100 MHz. Utilizando un acumulador de fase de 32 bits (la cantidad de bits elegida es arbitraria) tendríamos que:
$$I_{acumulador fase} = {100000000 \over 320000000} \times 2^{32} = 1342177280$$
Como se comentó antes, la cantidad de bits de resolución a la hora de indexar la tabla de ondas no es relevante a efectos de frecuencia (aunque sí a efectos de distorsión armónica y de relación señal/ruido). En nuestro caso, como no disponemos de un DAC sino que vamos a generar una señal cuadrada directamente, en teoría lo que necesitamos es una tabla con una onda cuadrada de tal forma que cuando esté en el máximo emita un 1 y cuando esté en el mínimo emita un 0.
Si asumimos que en la tabla de ondas vamos a meter una onda cuadrada con un ciclo de trabajo del 50% (perfectamente cuadrada), esto significará que la mitad de la tabla de ondas va a estar al valor mínimo (0 por ejemplo) y la otra mitad al valor máximo (255 por ejemplo, si es una ROM de 8 bits sin signo). Si al final vamos a traducir la salida de la tabla de ondas como un 0 si está en el valor mínimo y como un 1 si está en el valor máximo, es obvio que la salida de la tabla de ondas coincidirá con el valor del bit más significativo del acumulador de fase.
Y he aquí la "magia" del invento: Usando un único registro con un sumador podemos hacer un oscilador de onda cuadrada para el que podemos controlar la frecuencia de forma precisa entre 0 Hz y la mitad de la frecuencia de reloj. La precisión a la hora de ajustar la frecuencia nos la dará la cantidad de bits que usemos.
El jittering
Cualquier incremento en el acumulador de fase que no sea potencia de dos va a generar un efecto jitter en la señal de salida haciendo que ésta muchas veces diste de ser una señal cuadrada perfecta. Esto, como es obvio, provocará que la cantidad de armónicos que se generen se dispare. Vamos a verlo con un ejemplo.
Imaginemos el caso anterior: 320 MHz de frecuencia de reloj, un acumulador de fase de 32 bits y un incremento para el acumulador de fase igual a 1342177280. Aplicando este acumulador de fase obtenemos la siguiente salida (correspondiente al bit más significativo):
1 1 0 1 1 0 1 1 0 0 1 0 0 1 0 0 ... la secuencia se repite indefinidamente
Como se puede observar esta secuencia de bits dista mucho de parecerse a una señal cuadrada con ciclo de trabajo del 50%, en concreto genera tres pulsos anchos más juntos y luego dos pulsos estrechos más separados. Sin embargo si hacemos el análisis de Fourier de esta secuencia, tratándola como si fuese una señal, calculándole la transformada de Fourier usando un software numérico como Octave:
octave> abs(fft([1 1 0 1 1 0 1 1 0 0 1 0 0 1 0 0])) ans = 8.00000 1.79995 0.00000 1.01959 0.00000 5.12583 0.00000 1.20269 0.00000 1.20269 0.00000 5.12583 0.00000 1.01959 0.00000 1.79995
Vemos que la transformada de Fourier resultante es efectivamente simétrica (quitando la posición 0, que es la componente de continua), al tratarse de una señal real, y que, descartando la componente de continua (el índice 0 del vector), hay un máximo en el índice 5 del vector. Por las propiedades de la transformada de Fourier en este caso la posición 8 (el centro del vector y el centro de simetría) se corresponde con la frecuencia Nyquist que, al ser la frecuencia de reloj de 320 MHz, sería de 160 MHz (la mitad de la frecuencia del reloj). El máximo situado en la posición 5 del vector se corresponderá, siguiendo una regla de tres, con la frecuencia de:
$${{160000000 \times 5} \over 8} = 100000000 = 100 MHz$$
En efecto, la frecuencia fundamental (el máximo en la transformada de Fourier) de la señal de salida es de 100 MHz, que era nuestro objetivo, aunque como se puede ver en el análisis de Fourier, también se emitirán armónicos de 20 MHz (el valor 1.79995 se corresponde con la frecuencia ${{160 \times 1} \over 8}$), de 60 MHz (${{160 \times 3} \over 8}$) y de 140 MHz (${{160 \times 7} \over 8}$), aunque de menor amplitud.
Implementación y prueba de concepto
Como se va a emitir el sonido por radio FM y aún no disponemos de un ADC que permita la lectura de una fuente externa de audio, se generará la señal de audio dentro de la propia FPGA.
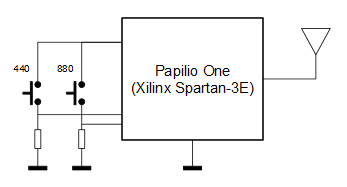
El sistema consta de dos entradas conectadas a sendos botones y que permiten seleccionar la frecuencia del tono a transmitir: cuando no se pulsa ningún botón no se modula (se genera la portadora sin modular), cuando se pulsa el botón 440 la portadora se modula con una señal cuadrada de 440 Hz (nota LA en la cuarta octava del piano), mientras que si se pulsa el botón 880 la portadora se modula con una señal cuadrada de 880 Hz (nota LA en la quinta octava del piano).
La única salida del sistema es la salida de la antena, que va a un trozo de cable que se coloca al aire. No es necesario nada más si vamos a colocar el receptor a pocos metros de la FPGA. En el caso de que queramos conectar la salida a una antena real y que queramos más potencia habría que colocar circuitos acondicionadores y/o amplificadores a la salida y, sobretodo, filtros: hay que recordar que la señal de salida es una onda cuadrada repleta de armónicos.
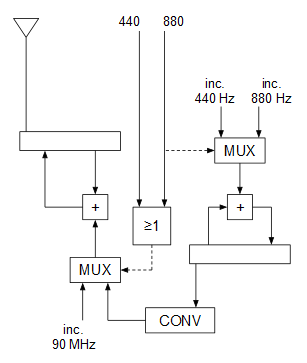
En reposo, las entradas 440 y 880 valen 0, por lo que el MUX inferior selecciona la entrada del incremento correspondiente a los 90 MHz (portadora sin modular). Cuando se pulsa sólo el botón 440 el MUX inferior deja pasar la señal moduladora (ya convertida en secuencias de incrementos en lugar de en 0 y 1) a la entrada del oscilador para modularlo, y cuando se pulsa el botón 880 ocurre lo mismo con el MUX inferior y, además, al cambiar la entrada de selección del MUX superior, cambia el incremento del oscilador que genera la señal moduladora para que genere 880 Hz en lugar de 440 Hz.
El módulo combinacional CONV convierte la entrada de 1 bit (0 o 1) proveniente del oscilador de 440 u 880 Hz, en una salida de 32 bits que es el incremento de fase de correspondiente a cada nivel de la señal moduladora:
0 --> 1341058799
1 --> 1343295761
En este caso se ha realizado una implementación sobre una FPGA Spartan-3E de Xilinx con un reloj externo de 32 MHz (papilio one). Las Spartan-3E disponen de varios DCM (Digital Clock Managers) que permiten subir la frecuencia de reloj mediante multiplicadores. En este caso, con un reloj a 32 MHz la máxima frecuencia que se puede alcanzar es de 288 MHz, por lo que ajustamos los cálculos a dicha frecuencia y asumiendo que vamos a transmitir en la banda de 90 MHz.
$$I_{acumulador fase} = {90000000 \over 288000000} \times 2^{32} = 1342177280$$
Como la señal moduladora (los tonos de 440 y 880 Hz) van a ser también ondas cuadradas, sólo hay que calcular los incrementos para el 0 y el 1 de la señal moduladora (en este caso no hay valores intermedios). El 0 de la señal moduladora lo asociaremos a 89,925 MHz y el 1 de la señal moduladora lo asociaremos a 90,075 MHz (recordemos que la profundidad de modulación en la FM comercial es de 75 KHz).
$$I_{89.925} = {89925000 \over 288000000} \times 2^{32} \approx 1341058799$$
$$I_{90.075} = {90075000 \over 288000000} \times 2^{32} \approx 1343295761$$
A continuación puede verse el código fuente:
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity FMTransmitter is port ( Clk : in std_logic; Reset : in std_logic; Button440 : in std_logic; Button880 : in std_logic; AntOut : out std_logic ); end entity; architecture Architecture1 of FMTransmitter is component Oscillator is generic ( NBits : integer := 32 ); port ( IncrementIn : in std_logic_vector(31 downto 0); Clk : in std_logic; Reset : in std_logic; DataOut : out std_logic ); end component; component Mux2Inputs is generic ( NBits : integer := 32 ); port ( Sel : in std_logic; DataIn0 : in std_logic_vector((NBits - 1) downto 0); DataIn1 : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; signal Mux1Out : std_logic_vector(31 downto 0); signal Mux1Sel : std_logic; signal ConvOut : std_logic_vector(31 downto 0); signal ConvIn : std_logic; signal Mux2Out : std_logic_vector(31 downto 0); begin RadioOsc : Oscillator generic map ( NBits => 32 ) port map ( Clk => Clk, Reset => Reset, IncrementIn => Mux1Out, DataOut => AntOut ); Mux1Sel <= Button440 or Button880; Mux1 : Mux2Inputs generic map ( NBits => 32 ) port map ( Sel => Mux1Sel, DataIn0 => std_logic_vector(to_unsigned(1342177280, 32)), -- center freq = 90.0 MHz DataIn1 => ConvOut, DataOut => Mux1Out ); -- center freq - 75 KHz when 0 -- center freq + 75 KHz when 1 ConvOut <= std_logic_vector(to_unsigned(1341058799, 32)) when (ConvIn = '0') else std_logic_vector(to_unsigned(1343295761, 32)); AudioOsc : Oscillator generic map ( NBits => 32 ) port map ( Clk => Clk, Reset => Reset, IncrementIn => Mux2Out, DataOut => ConvIn ); Mux2 : Mux2Inputs generic map ( NBits => 32 ) port map ( Sel => Button880, DataIn0 => std_logic_vector(to_unsigned(6562, 32)), -- 440 Hz DataIn1 => std_logic_vector(to_unsigned(13124, 32)), -- 880 Hz DataOut => Mux2Out ); end architecture;
Tanto el oscilador de salida (el de alta frecuencia) como el oscilador de audio se han implementado usando el mismo componente Oscillator.vhd.
library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; use ieee.std_logic_signed.all; entity Oscillator is generic ( NBits : integer := 32 ); port ( IncrementIn : in std_logic_vector(31 downto 0); Clk : in std_logic; Reset : in std_logic; DataOut : out std_logic ); end entity; architecture Architecture1 of Oscillator is component Reg is generic ( NBits : integer := 32 ); port ( Enable : in std_logic; Clk : in std_logic; DataIn : in std_logic_vector((NBits - 1) downto 0); DataOut : out std_logic_vector((NBits - 1) downto 0) ); end component; signal MuxOut : std_logic_vector((NBits - 1) downto 0); signal RegOut : std_logic_vector((NBits - 1) downto 0); begin PhaseAcc : Reg generic map ( NBits => NBits ) port map ( Enable => '1', Clk => Clk, DataIn => MuxOut, DataOut => RegOut ); MuxOut <= (others => '0') when (Reset = '1') else (RegOut + IncrementIn); DataOut <= RegOut(NBits - 1); end architecture;
El tipo de sumador
En otros proyectos FPGA anteriormente abordados en este blog, cada vez que hacía falta un sumador se tiraba de un sumador estándar implementado mediante lógica combinatoria (Adder.vhd). Hasta ahora se ha hecho así por razones pedagógicas. En este caso, sin embargo, al estar el reloj a una frecuencia extremadamente alta para la FGPA ha sido necesario el uso del operador +. Este operador garantiza la mejor implementación de la suma para la plataforma y esto se traduce, en el caso del Spartan-3E y en el caso de la mayoría de las FPGAs existentes, en que se va a hacer uso de sumadores que ya se encuentran integrados (hardwired) en el sustrato de todas las FPGA (todos los fabricantes los incluyen, de mayor o menor cantidad de bits).
¿Qué ventajas tienen estos sumadores con respecto al sumador que hemos estado usando hasta ahora? La principal diferencia es que en nuestro Adder.vhd el acarreo es en cascada, mientras que los sumadores implementados a fuego en las FPGAs están basados siempre en circuitos CLA (Carry Look Ahead), que permiten precalcular los acarreos de cada bit sin necesidad de que estén calculados los bits anteriores. Aún siendo circuitos combinacionales tanto los unos como los otros, el tiempo de propagación del resultado en el caso de sumadores con CLA es mucho menor que en el caso de sumadores con acarreo en cascada (como el Adder.vhd que hemos usado hasta ahora en los proyectos).
En nuestro caso concreto se da además la circunstancia que, con un reloj a 288 MHz, el sumador con acarreo en cascada (el Adder.vhd de siempre) da problemas de timing o, lo que es lo mismo, no le da tiempo de sumar tan rápido y no queda otra opción que tirar del operador + (cosa que, por otro lado, es lo recomendable ya que se garantiza siempre la mejor implementación).
Vídeo
A continuación un pequeño fragmento de vídeo donde se puede ver y escuchar el invento en funcionamiento. La calidad del audio es bastante baja: usé mi radio-despertador como receptor, en el receptor del móvil se oye mucho mejor pero no hubiese podido grabarlo :-)
Espero que haya resultado interesante. Todo el código fuente se puede descargar de la sección soft.
[ añadir comentario ] ( 2236 visualizaciones ) | [ 0 trackbacks ] | enlace permanente
Tweet | |
( 3 / 3959 ) Calendario
Calendario





{kind=link}